2月16日凌晨,OpenAI再次扔出一枚深水炸彈,發佈首個文生視頻模型Sora。據介紹,Sora可以直接輸出長達60秒的視頻,並且包含高度細致的背景、復雜的多角度鏡頭,以及富有情感的多個角色。目前官網上已經更新48個視頻demo,在這些demo中,Sora不僅能準確呈現細節,還能理解物體在物理世界中的存在,並生成具有豐富情感的角色。該模型還可以根據提示、靜止圖像甚至填補現有視頻中的缺失幀來生成
一位時髦女士漫步在東京街頭,周圍是溫暖閃爍的霓虹燈和動感的城市標志。

一名年約三十的宇航員戴著紅色針織摩托頭盔展開冒險之旅,電影預告片呈現其穿梭於藍天白雲與鹽湖沙漠之間的精彩瞬間,獨特的電影風格、采用35毫米膠片拍攝,色彩鮮艷。

豎屏超近景視角下,這隻蜥蜴細節拉滿:

OpenAI表示,公司正在教授人工智能理解和模擬運動中的物理世界,目標是訓練出能夠幫助人們解決需要與現實世界互動的問題的模型。在此,隆重推出文本到視頻模型——Sora。Sora可以生成長達一分鐘的視頻,同時保證視覺質量和符合用戶提示的要求。
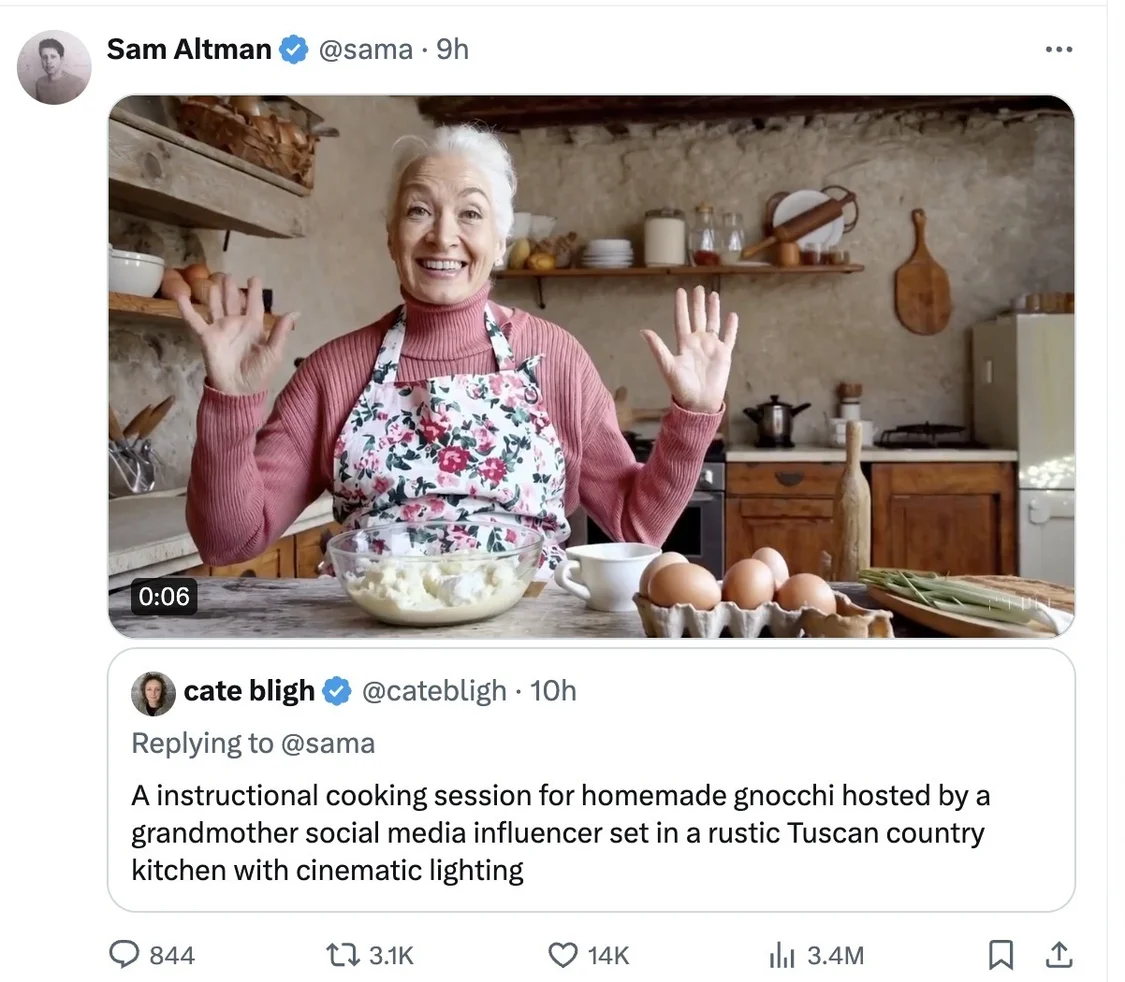
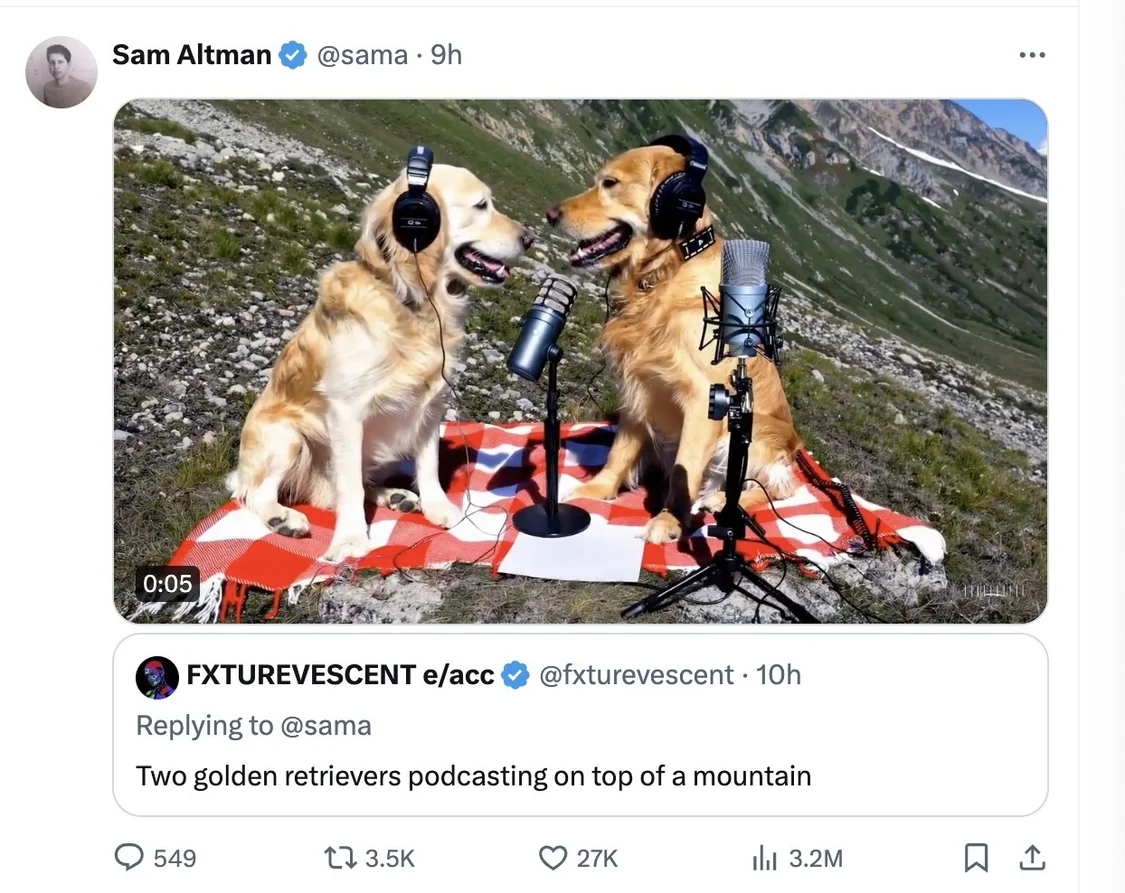
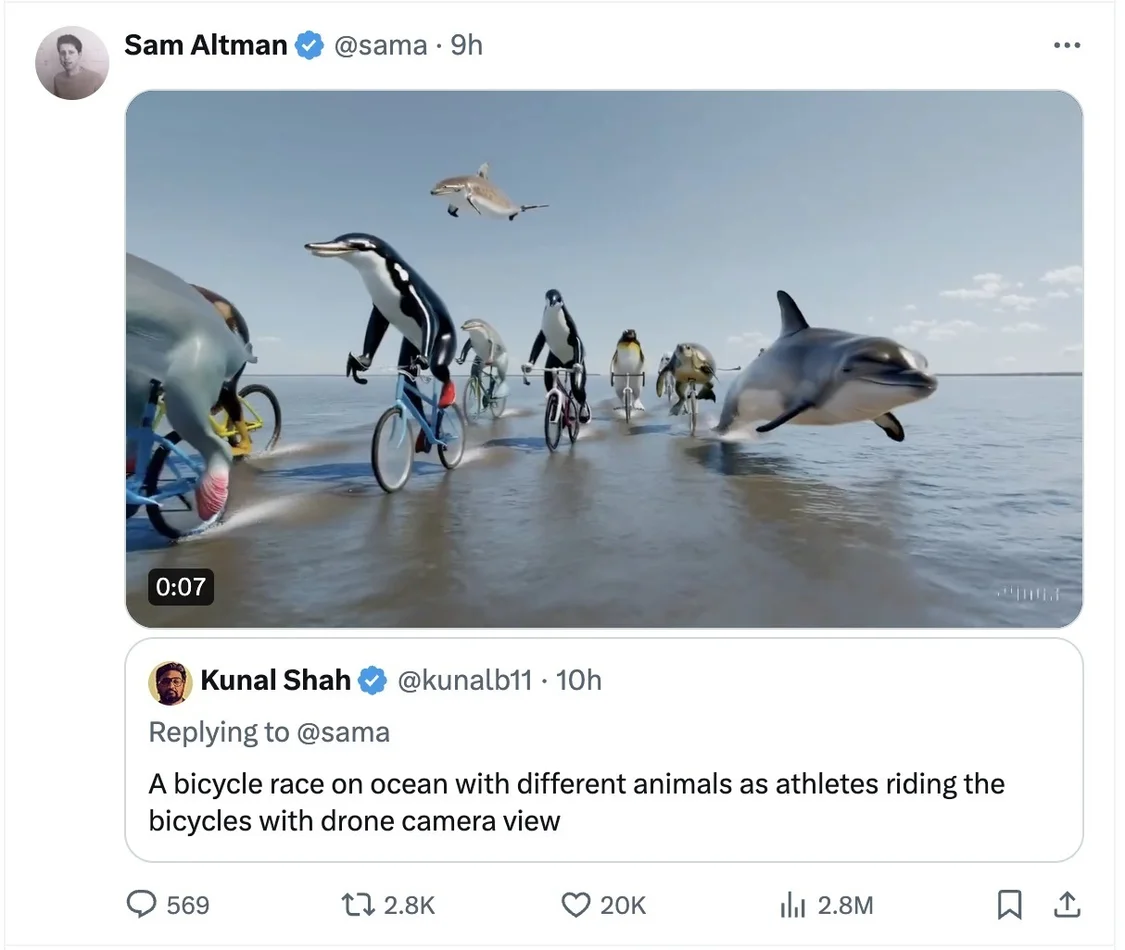
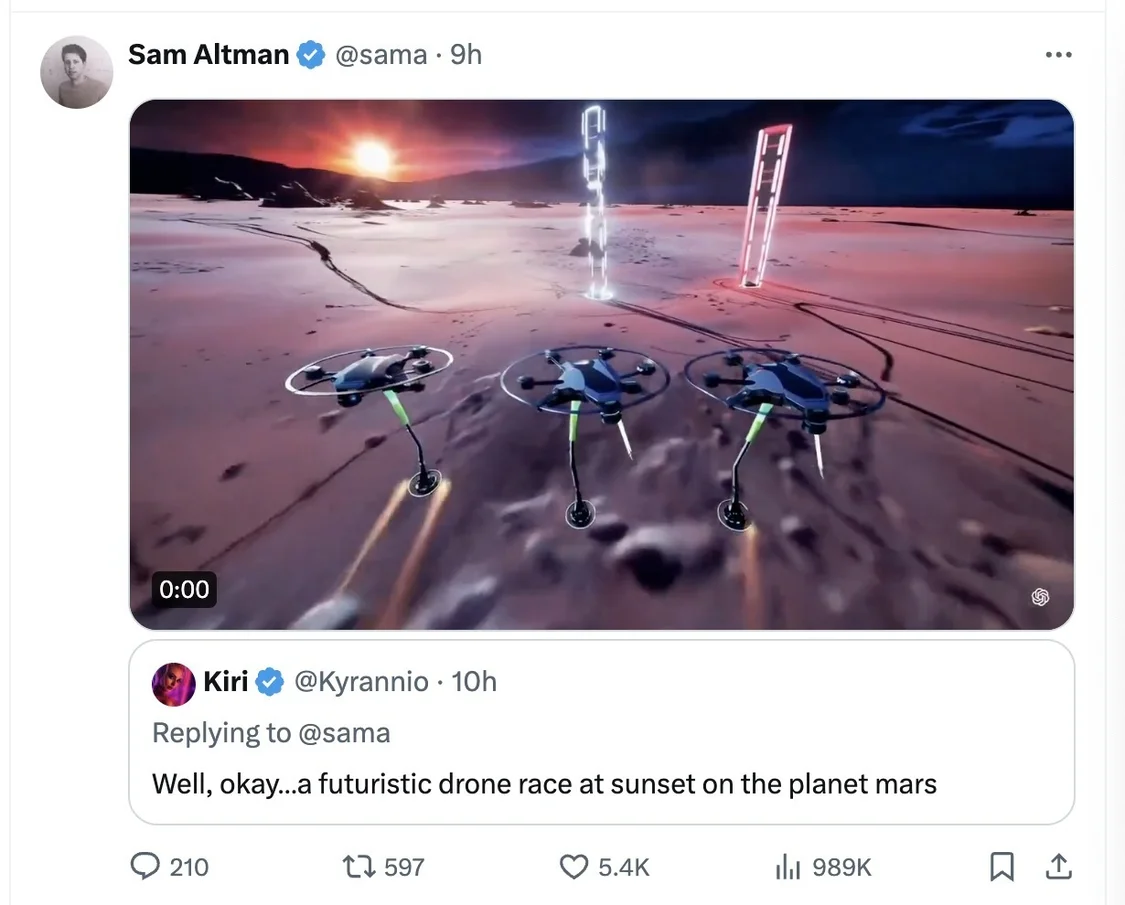
OpenAI創始人兼CEOSam Altman(奧爾特曼)太會玩,讓網友評論回復Prompt(大語言模型中的提示詞),他選一些用Sora生成視頻。截至發稿,奧爾特曼連發多條根據網友提示詞生成的視頻,包括不同動物在海上進行自行車比賽、發佈自制面疙瘩烹飪教學視頻的祖母、兩隻金毛犬在山頂做播客、日落時分火星上進行的一場無人機競賽等。但這些視頻時長為9秒至17秒不等。
技術層面,Sora采用擴散模型(diffusion probabilistic models)技術,基於Transformer架構,但為解決Transformer架構核心組件註意力機制的長文本、高分辨率圖像處理等問題,擴散模型用可擴展性更強的狀態空間模型(SSM)主幹替代傳統架構中的註意力機制,可以使用更少的算力,生成高分辨率圖像。此前Midjourney與Stable Diffusion的圖像與視頻生成器同樣基於擴散模型。
同時,Sora也存在一定的技術不成熟之處。OpenAI表示,Sora可能難以準確模擬復雜場景的物理原理,可能無法理解因果關系,可能混淆提示的空間細節,可能難以精確描述隨著時間推移發生的事件,如遵循特定的相機軌跡等。
根據OpenAI關於Sora的技術報告《Video generation models as world simulators》(以下簡稱報告),跟大語言模型一樣,Sora也有湧現的模擬能力。
OpenAI方面在技術報告中表示,並未將Sora單純視作視頻模型,而是將視頻生成模型作為“世界模擬器”,不僅可以在不同設備的原生寬高比直接創建內容,而且展示一些有趣的模擬能力,如3D一致性、長期一致性和對象持久性等。目前Sora能夠生成一分鐘的高保真視頻,OpenAI認為擴展視頻生成模型是構建物理世界通用模擬器的一條有前途的途徑。
報告指出,OpenAI研究在視頻數據上進行大規模訓練的生成模型。具體而言,聯合訓練文本條件擴散模型,該模型可處理不同持續時間、分辨率和長寬比的視頻和圖像。OpenAI利用一種基於時空補丁的視頻和圖像潛在代碼的變壓器架構。最大的模型Sora能夠生成一分鐘的高保真視頻。結果表明,擴展視頻生成模型是構建通用物理世界模擬器的有前途的途徑。
報告重點介紹OpenAI將各類型視覺數據轉化為統一表示的方法,這種方法能夠對生成模型進行大規模訓練,並對Sora的能力與局限進行定性評估。先前的大量研究已經探索使用多種方法對視頻數據進行生成建模,包括循環網絡、生成對抗網絡、自回歸轉換器和擴散模型。這些研究往往隻關註於狹窄類別的視覺數據、較短的視頻或固定大小的視頻。而Sora是一個通用的視覺數據模型,它能夠生成跨越不同時長、縱橫比和分辨率的視頻和圖像,甚至能夠生成長達一分鐘的高清視頻。
OpenAI從大型語言模型中汲取靈感,這些模型通過訓練互聯網規模的數據獲得通用能力。LLM范式的成功在一定程度上得益於令牌的使用,這些令牌巧妙地統一文本的不同模式——代碼、數學和各種自然語言。在這項工作中,OpenAI考慮視覺數據的生成模型如何繼承這些優勢。雖然LLM有文本令牌,但Sora有視覺補丁。之前已經證明,補丁是視覺數據模型的有效表示。補丁是一種高度可擴展且有效的表示,可用於在多種類型的視頻和圖像上訓練生成模型。
Sora支持采樣多種分辨率視頻,包括1920x1080p的寬屏視頻、1080x1920的豎屏視頻以及介於兩者之間的所有分辨率。這使得Sora能夠直接以原生縱橫比為不同的設備創建內容。同時,它還允許在生成全分辨率內容之前,使用相同的模型快速制作較小尺寸的內容原型。