今日凌晨,OpenAI推出其首款文生視頻大模型Sora。該模型能根據提示詞生成長達1分鐘的視頻,或者擴展生成的視頻使其更長,同時視覺質量相當驚艷。相比以往的視頻模型,Sora的亮點非常明顯,不僅對文本理解更深刻,可以準確地呈現提示詞,而且能在一個生成的視頻中創建多個鏡頭,準確地保留角色和視覺風格。


尤其值得一提的是,Sora在細節處理上做得非常出挑,能夠理解復雜場景中不同元素之間的物理屬性及其關系,正確呈現它們在物理世界中的存在方式。

除支持文本指令輸入外,該模型支持生成圖像,也支持將現有靜止圖像變成視頻,能對現有視頻進行擴展、將兩個視頻銜接並填充缺失的幀。
其3D仿真能力非常突出,無論是制作短視頻、動畫、電影畫面,還是渲染視頻遊戲,Sora都展示出令人期待的落地前景。

為全方位展示Sora的水平,OpenAI一口氣放出48個用Sora直接生成、未經修改、長度不等(9秒~60秒)的視頻。下文附有48個視頻的完整展示,火眼金睛的讀者朋友們可以研究下這些視頻的準確程度,或者從專業性上找找bug。
OpenAI將這個大模型稱作是“能夠理解和模擬現實世界的模型的基礎”,相信其能力“將是實現AGI的重要裡程碑”。其技術報告今日剛剛新鮮出爐:

技術報告指路:https://openai.com/research/video-generation-models-as-world-simulators
一、Sora技術拆解:60秒視頻、理解力強大、一次預見多幀
OpenAI首個文生視頻大模型Sora是一個在可變持續時間、分辨率、寬高比的視頻和圖像上聯合訓練的文本條件擴散模型。

與GPT模型類似,Sora使用Transformer架構,擴展性很強大,能一次生成時長1分鐘的視頻,或者擴展生成的視頻使其更長。
隨著訓練計算量增加,樣本質量顯著提高。

具體來看,該模型能生成具有多個角色、特定類型的運動以及精確的主題和背景細節的復雜場景。
通過賦予模型一次多幀的預見能力,OpenAI團隊解決一個具有挑戰性的問題,即確保一個主題即使暫時消失在視野之外也保持不變。
過去的圖像和視頻生成方法通常是調整大小,裁剪或修剪視頻到標準尺寸——例如,4秒視頻、256×256分辨率。而OpenAI發現在原始大小的數據上進行訓練提供一些好處:
(1)采樣的靈活性:Sora可以采樣寬屏1920x1080p視頻、垂直1080×1920視頻以及介於兩者之間的所有視頻。這讓Sora可直接以不同設備的原始寬高比為其創建內容。它還支持在生成全分辨率的內容之前,以較小的尺寸快速創建內容原型——所有內容都使用相同的模型。

(2)改進框架和構圖:OpenAI通過經驗發現,在視頻的原始長寬比上進行訓練可以改善構圖和框架。研究團隊將Sora與其模型的一個版本進行比較,該版本將所有訓練視頻裁剪為方形。在正方形裁剪(左圖)上訓練的模型有時會生成僅部分顯示主題的視頻。相比之下,來自Sora(右圖)的視頻有改進的幀。

此外,Sora文生視頻大模型具備如下特點:
1、強大的語言理解能力:訓練文本到視頻生成系統需要大量帶有相應文本說明的視頻。OpenAI將DALL·E 3中介紹的字幕重配技術(Recaptioning)應用到視頻中,首先訓練一個高度描述性的字幕模型,然後使用它為其訓練集中的所有視頻生成文本字幕。OpenAI發現,對高度描述性的視頻字幕進行訓練可提高文本保真度以及視頻的整體質量。與DALL·E 3類似,研究團隊還利用GPT將簡短的用戶提示轉換為更長的詳細字幕,並將其發送到視頻模型。這使得Sora能準確按照用戶提示生成高質量的視頻。

2、支持現有的圖像或視頻輸入:這種功能使Sora能夠執行廣泛的圖像和視頻編輯任務——創建完美的循環視頻、動畫靜態圖像、向前或向後擴展視頻等。比如,基於DALL·E 3圖像生成視頻,從一個生成的視頻片段開始向前/向後擴展視頻,編輯轉換視頻的風格/環境,將兩個輸入視頻無縫銜接在一起。


3、圖像生成功能:研究團隊通過在一個時間范圍為一幀的空間網格中排列高斯噪聲塊來實現這一點。該模型可以生成可變大小的圖像,最高可達2048 × 2048分辨率。

4、新興的仿真能力:OpenAI發現視頻模型在大規模訓練時表現出許多有趣的突發能力。這些功能使Sora能夠從現實世界中模擬人、動物和環境的某些方面。Sora可以生成帶有動態攝像機運動的視頻。隨著攝像機的移動和旋轉,人物和場景元素在三維空間中始終如一地移動。
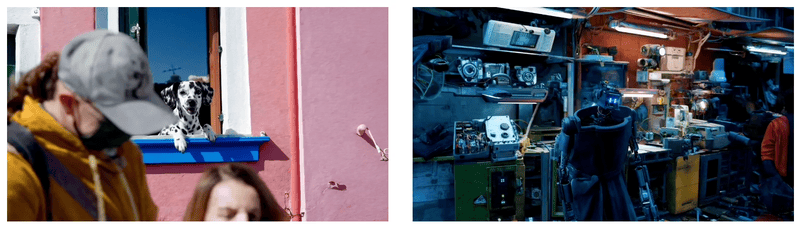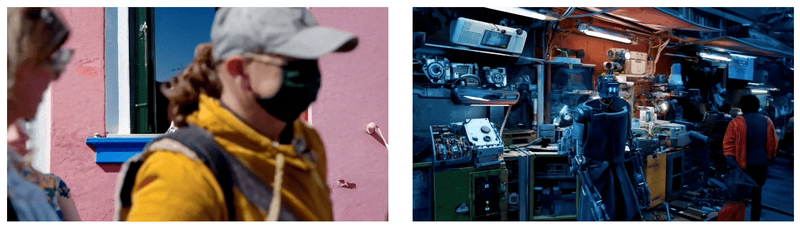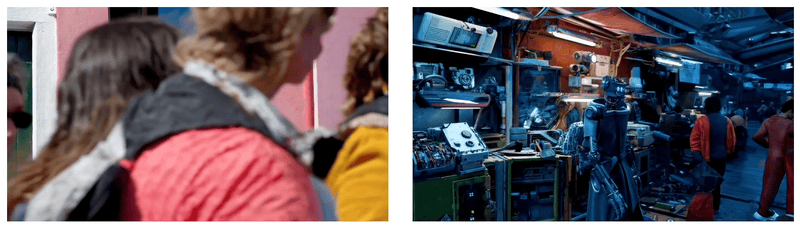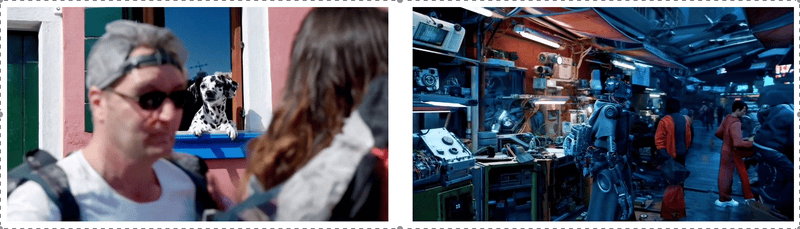
Sora經常能夠有效地為短期和長期依賴關系建模,可以在單個樣本中生成同一角色的多個鏡頭,在整個視頻中保持其外觀一致。該模型有時可以用簡單的方式模擬影響世界狀態的行為,例如,畫傢可以在畫佈上留下新的筆觸,隨著時間的推移,或者一個人吃漢堡時留下咬痕。

在模擬數字世界方面,Sora能夠模擬人工過程,比如視頻遊戲,可在高保真度渲染世界及其動態的同時,用基本策略控制《我的世界》中的玩傢。

這些功能表明,視頻模型的持續擴展是發展物理和數字世界以及生活在其中的物體、動物和人的高性能模擬器的一條有希望的道路。
OpenAI從大語言模型獲得靈感,大語言模型的成功部分歸功於tokens優雅地統一文本代碼、數學及各種自然語言的不同模式。Sora研究則考慮到讓視覺數據的生成模型繼承這些優點。
此前視覺patch已經被證明是視覺數據模型的有效表示。OpenAI發現patch是一種高度可擴展且有效的表示形式,可用於在不同類型的視頻和圖像上訓練生成模型。
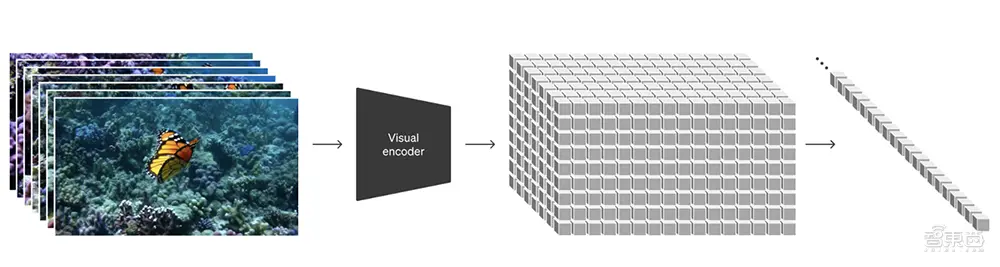
OpenAI將視頻轉換成patch,訓練一個降低視覺數據維度的網絡,該網絡將原始視頻作為輸入並輸出在時間和空間上壓縮的潛在表示。Sora在這個壓縮的潛在空間中接受訓練並隨後生成視頻。 OpenAI還訓練相應的解碼器模型。
給定一個壓縮的輸入視頻,研究團隊提取一系列時空patch,充當Transformer tokens,這種基於patch的表示使得Sora能對不同時長、寬高比、分辨率的視頻和圖像進行訓練。在推理時,可通過在適當大小的網格中排列隨機初始化的patches來控制生成視頻的大小。
Sora是一個擴散模型;輸入一個噪聲patch,它被訓練來預測原始的“幹凈”patch。在這項工作中,OpenAI發現擴散Transformer可以作為視頻模型有效擴展。
二、48個視頻Demo:動漫電影、逼真自然、魔幻大片
OpenAI一共放出48個視頻來展示Sora模型的強大之處。受站點上傳限制,下文主要以動圖形式來簡要呈現這些生成視頻的部分視覺效果。
提示詞1:一個時髦的女人走在東京的街道上,到處都是溫暖的霓虹燈和生動的城市標志。她穿著黑色皮夾克、紅色長裙、黑色靴子,拿著一個黑色錢包。她戴著太陽鏡,塗著紅色的口紅。她走起路來自信而隨意。街道是潮濕和反光的,創造一個彩色燈光的鏡子效果。許多行人走來走去。

提示詞2:幾隻巨大的長毛猛獁象穿過一片白雪覆蓋的草地,它們長長的毛茸茸的皮毛在風中輕拂,遠處白雪覆蓋的樹木和戲劇性的雪山,午後的光線與縷縷的雲和遠處的太陽創造溫暖的光芒,低相機的視角是驚人的,捕捉到美麗的攝影,景深的大型毛茸茸的哺乳動物。

提示詞3:這是一部電影預告片,講述30歲的太空人戴著紅色羊毛針織摩托車頭盔的冒險經歷,藍天,鹽沙漠,電影風格,用35毫米膠片拍攝,色彩鮮艷。

提示詞4:無人機拍攝的海浪沖擊著大蘇爾加雷角海灘上崎嶇的懸崖。藍色的海水拍打著白色的波浪,夕陽的金色光芒照亮巖石海岸。遠處有一座小島,島上有一座燈塔,懸崖邊上長滿綠色的灌木叢。從公路到海灘的陡峭落差是一個戲劇性的壯舉,懸崖的邊緣突出在海面上。這是一幅捕捉到海岸原始美景和太平洋海岸公路崎嶇景觀的景色。

提示詞5:動畫場景特寫一個毛茸茸的矮個子怪物跪在融化的紅燭旁。美術風格是3D和現實的,重點是照明和紋理。這幅畫的氣氛是一種驚奇和好奇,因為怪物睜大眼睛,張開嘴巴凝視著火焰。它的姿勢和表情傳達一種天真和頑皮的感覺,好像它是第一次探索周圍的世界。暖色和戲劇性燈光的使用進一步增強圖像的舒適氛圍。

提示詞6:一個華麗渲染的珊瑚礁紙工藝品世界,到處都是五顏六色的魚和海洋生物。

提示詞7:這個維多利亞冠鴿的特寫展示它引人註目的藍色羽毛和紅色胸部。它的羽冠是由精致的花邊羽毛制成的,而它的眼睛是醒目的紅色。鳥的頭微微向一側傾斜,給人一種帝王和威嚴的印象。背景是模糊的,吸引人們註意到這隻鳥引人註目的外表。

提示詞8:兩艘海盜船在一杯咖啡中航行時相互爭鬥的逼真特寫視頻。

提示詞9:一個20多歲的年輕人坐在天空的一片雲上讀書。

提示詞10:淘金熱時期加州的歷史鏡頭

提示詞11:一個玻璃球的近景,裡面有一個禪宗花園。球體中有一個小矮人正在耙花園,並在沙子上創造圖案。

提示詞12:一個24歲的女人眨著眼睛的極端特寫,站在馬拉喀什的神奇時刻,電影膠片拍攝,70mm,景深,生動的色彩,電影感。

提示詞13:一隻卡通袋鼠跳迪斯科。

提示詞14:一個美麗的自制視頻,展示2056年尼日利亞拉各斯的人們。用手機攝像頭拍攝的。

提示詞15:一個培養皿,裡面生長著竹林,小熊貓在裡面跑來跑去。

提示詞16:攝像機圍繞著一大堆老式電視旋轉,這些電視播放著不同的節目——20世紀50年代的科幻電影、恐怖電影、新聞、靜態、70年代的情景喜劇等,背景設在紐約博物館的一個大型畫廊裡。

提示詞17:一個小的、圓的、毛茸茸的、有一雙大而富有表現力的眼睛的生物探索一個充滿活力的魔法森林的3D動畫。這種動物是兔子和松鼠的異想天開的混合體,有著柔軟的藍色皮毛和濃密的條紋尾巴。它沿著波光粼粼的小溪跳躍,驚奇地睜大眼睛。森林裡充滿神奇的元素:發光和變色的花朵,紫色和銀色葉子的樹木,以及像螢火蟲一樣的小浮動燈。這隻生物停下來和一群在蘑菇圈周圍跳舞的小仙女嬉戲。這隻生物敬畏地仰望著一棵巨大的、發光的樹,這棵樹似乎是森林的中心。

提示詞18:攝像機跟在一輛黑色車頂架的白色復古SUV後面,它在陡峭的山坡上沿著松年輪繞的陡峭土路加速行駛,灰塵從輪胎上揚起,陽光照在越野車上,在土路上加速行駛,在現場投下溫暖的光芒。這條土路彎彎曲曲地延伸到遠處,看不到其他的汽車或車輛。道路兩旁的樹木都是紅杉,點綴著一片片綠色植物。從後面看到的汽車跟隨曲線輕松,使它看起來好像是在崎嶇不平的地形上行駛。土路本身被陡峭的丘陵和山脈包圍,上面是清澈的藍天和縷縷的雲。

提示詞19:火車在東京郊區行駛時,車窗上的倒影。

提示詞20:一架無人機攝像機環繞著一座美麗的歷史悠久的教堂,這座教堂建在阿馬爾菲海岸的巖石上,這張照片展示歷史和宏偉的建築細節,分層的小路和露臺,海浪撞擊著下面的巖石,俯瞰著意大利阿馬爾菲海岸的海岸水域和丘陵景觀,遠處的幾個人在露臺上散步,欣賞著壯觀的海景。下午溫暖的陽光為現場創造一種神奇而浪漫的感覺,美麗的攝影捕捉到令人驚嘆的景色。

提示詞21:一隻巨大的橙色章魚在海底休息,與沙質和巖石地形融為一體。它的觸手在身體周圍展開,眼睛是閉著的。章魚沒有意識到一隻帝王蟹正從巖石後面向它爬來,它的爪子抬起,準備攻擊。這種螃蟹是棕色的、多刺的,有長腿和觸角。這個場景是從廣角拍攝的,展示海洋的廣闊和深度。海水清澈湛藍,陽光透過來。鏡頭銳利,動態范圍大。章魚和螃蟹是焦點,而背景稍微模糊,創造景深效果。

提示詞22:一群紙飛機在茂密的叢林中飛舞,像候鳥一樣在樹木之間穿梭。

提示詞23:一隻貓叫醒正在睡覺的主人,要求吃早飯。主人試圖忽略貓,但貓嘗試新的策略,最後主人從枕頭下拿出一個秘密的零食,讓貓多待一會兒。

提示詞24:基納巴坦幹河上的婆羅洲野生動物。

提示詞25:有中國龍的中國農歷新年慶祝視頻。

提示詞26:參觀藝術畫廊,欣賞許多風格各異的精美藝術品。

提示詞27:美麗、白雪皚皚的東京城市熙熙攘攘。鏡頭穿過熙熙攘攘的城市街道,跟隨幾個人享受美麗的雪天,在附近的攤位上購物。絢麗的櫻花花瓣隨著雪花在風中飛舞。

提示詞28:這是一幅定格動畫,描繪一朵花從郊區房子的窗臺上長出來。

提示詞29:賽博朋克設定的機器人生活故事。

提示詞30:極致特寫一個60歲、頭發胡子花白的男人,在深度思考宇宙歷史,他坐在一傢巴黎的咖啡館,穿著一件羊毛外套西裝外套和一件襯衫,戴著一件棕色的貝雷帽、眼鏡,有一個非常專業的外表,結束時他有一個微妙的、封閉式的笑容,好像找到答案,神秘生活,燈光非常電影化,金色燈光和巴黎的街道和城市作為背景,景深,電影感,35mm膠片。

提示詞31:一個美麗的剪影動畫展示一隻狼對著月亮嚎叫,感到孤獨,直到它找到它的族群。

提示詞32:紐約市像被淹沒的亞特蘭蒂斯。魚、鯨魚、海龜和鯊魚遊過紐約的街道。

提示詞33:一窩金毛獵犬小狗在雪地裡玩耍。他們的頭從雪中探出頭來,身上覆蓋著雪。

提示詞34:一個人跑步的步印場景,電影膠片,35mm拍攝。

提示詞35:五隻小灰狼在一條偏僻的礫石路上嬉戲追逐,周圍長滿草。幼崽們又跑又跳,互相追逐,互相撕咬、玩耍。

提示詞36:籃球穿過籃筐然後爆炸。

提示詞37:考古學傢在沙漠中發現一把普通的塑料椅子,他們小心翼翼地挖掘並撣去上面的灰塵。

提示詞38:一位頭發梳得整整齊齊的白發老奶奶站在一張木制餐桌前,身後是一個色彩斑斕的生日蛋糕,上面插著無數的蠟燭,她的眼睛裡閃爍著幸福的光芒,臉上流露出一種純粹的快樂和幸福。她身體前傾,輕輕地吹滅蠟燭,蛋糕上有粉紅色的糖霜和糖屑,蠟燭也不再閃爍,老奶奶穿著一件淺藍色的襯衫,上面裝飾著花卉圖案,可以看到幾個快樂的朋友和傢人坐在桌子旁慶祝,背景虛化。這個場景拍得很漂亮,像電影一樣,展示老奶奶和餐廳的3/4視圖。暖色調和柔和的燈光改善心情。

提示詞39:鏡頭直接對著意大利佈拉諾五顏六色的建築。一隻可愛的斑點狗從一樓的窗戶往外看。許多人沿著建築物前的運河街道散步或騎自行車。

提示詞40:一隻可愛快樂的水獺穿著黃色救生衣自信地站在沖浪板上,沿著綠松石般的熱帶水域騎行,附近是鬱鬱蔥蔥的熱帶島嶼,3D數字渲染藝術風格。

提示詞41:這張變色龍的特寫照片展示它驚人的變色能力。背景是模糊的,吸引人們註意到動物引人註目的外表。

提示詞42:一隻柯基在熱帶毛伊島拍攝視頻。

提示詞43:一隻白橙相間的虎斑貓歡快地在茂密的花園裡竄來竄去,好像在追逐什麼東西。它的眼睛睜得大大的,歡快地向前跑著,一邊走一邊掃視著樹枝、花朵和樹葉。這條小路很窄,因為它在所有的植物之間穿行。這個場景是從地面的角度拍攝的,緊跟在貓後面,給人一個低而親密的視角。圖像是電影般的暖色調和顆粒紋理。樹葉和植物之間分散的日光形成溫暖的對比,突出貓的橙色皮毛。這張照片清晰銳利,景深淺。

提示詞44:藍色聖托裡尼鳥瞰圖,展示白色基克拉迪建築和藍色圓頂的驚人建築。火山口的景色令人嘆為觀止,燈光營造出一種美麗、寧靜的氛圍。

提示詞45:工人、設備和重型機械密集的建築工地的傾斜。

提示詞46:一個巨大的、高聳的雲在一個人的形狀在地球上隱約出現。雲人把閃電射向地面。

提示詞47:一隻薩摩耶犬和一隻金毛獵犬在夜晚的霓虹燈城市裡嬉戲。附近建築物發出的霓虹燈在它們的皮毛上閃閃發光。

提示詞48:Glenfinnan高架橋是英國蘇格蘭的一座歷史悠久的鐵路橋,橫跨馬萊格鎮和威廉堡之間的西部高地線。一列蒸汽火車駛離大橋,在拱形高架橋上行駛,這是一幅令人驚嘆的景象。風景點綴著鬱鬱蔥蔥的綠色植物和巖石山脈,為火車之旅創造風景如畫的背景。天空湛藍,陽光明媚,這是個探索這個雄偉景點的美好日子。

三、不足:難以模擬復雜場景,混淆提示詞的空間細節
OpenAI坦言,當前Sora目前存在許多局限性,可能難以準確地模擬復雜場景的物理屬性,比如玻璃破碎;也可能無法理解因果關系的具體實例。例如,一個人咬一口餅幹,但之後餅幹上可能沒有咬痕。

該模型還可能混淆提示的空間細節,例如,混淆左和右,並且可能難以精確描述隨時間發生的事件,例如跟隨特定的攝像機軌跡。
OpenAI強調說,在將Sora應用於OpenAI的產品之前,他們將采取一些重要的安全措施,包括與紅隊專傢合作進行對抗性測試、構建檢測分類器等工具來幫助檢測誤導性內容、計劃在未來包含C2PA元數據等。
除開發新技術為部署做準備外,OpenAI還利用其為使用DALL·E 3的產品構建的現有安全方法,這些方法也適用於Sora。
Sora文生視頻大模型的研究由Bill Peebles、Tim Brooks領導,系統領導者是Connor Holmes。以下人員均參與此研究的貢獻。

OpenAI還對下述人員致以特別感謝:

結語:OpenAI終於下場,視頻生成模型迎來重磅玩傢!
隨著OpenAI首款文生視頻大模型Sora推出,去年已經如火如荼展開的文生視頻大模型大戰,今年儼然要通過卷向更強性能,開啟落地之年。
其研究團隊相信,Sora今天所擁有的能力表明,視頻模型的持續擴展是一條很有前途的道路,可以開發出物理和數字世界的模擬器,以及生活在其中的物體、動物和人。
OpenAI承諾將與世界各地的政策制定者、教育工作者和藝術傢接觸,解他們的擔憂,並確定這項新技術的積極用例。
盡管進行廣泛的研究和測試,但OpenAI團隊無法預測人們使用其技術的所有有益方式,也無法預測人們濫用它的所有方式。該團隊相信隨著時間的推移,從現實世界的使用中學習是創建和發佈越來越安全的AI系統的關鍵組成部分。