假期輕松愉快,沒太關註時事。沒想到一覺醒來,朋友圈突然被一則新聞刷屏:OpenAI發佈文生視頻模型Sora。好傢夥,瞬間給我拉回工作氛圍。人們一直期待GPT-5,但Sora帶來的轟動不亞於GPT-5的發佈。之前大傢還在關註,Google推出的Gemini能否殺死GPT4,全世界各大科技巨頭能否在這波AI浪潮中彎道超車。現在,顯然沒人關註。因為OpenAI自己可能要用它先殺死GPT-4。

我上官網(https://openai.com/sora)看演示視頻,無論從視頻流暢度還是細節表現能力上,Sora的效果都相當驚艷。
難怪有人說:現實,不存在。
比如官推裡這條14秒的東京雪景: 美麗的,被雪覆蓋的東京正繁忙著。鏡頭穿過繁忙的城市街道,跟隨著幾個享受雪景和在附近攤位購物的人。美麗的櫻花瓣隨風飄落,與雪花一同飛舞。
盡管我們能感覺到,還有那麼一些不自然。但當素材用,已經足矣。

又比如下面這張對法令紋和痘印的刻畫,隻要不去吹毛求疵,確實已經足夠真實。
說句不該說的,這張圖,至少看起來比坐在美顏前面的女主播們真實……

網友們也第n+1次紛紛哀悼起相關賽道的公司們:
“OpenAI就是不能停止殺死創業公司。”
“天哪,現在起我們要弄清什麼是真的,什麼是假的。”
“我的工作沒。”
“整個影像素材行業被血洗,安息吧。”
……
01 現實與虛擬的界限
其實,文字生成視頻這回事,早就不新鮮。
2023年8月,RunwayGen2正式推出,AI生成式視頻正式進入大眾視野。
到今年初,不計其數的產品一個接一個,PIKA、Pixverse、SVD、Genmo、Moonvalley……等等等等。
太多,也太卷。
我們能明顯感覺到,最近小半年刷的短視頻裡,多很多不自然的視頻。稍微品一品,就能察覺這肯定不是人工剪輯的。
首先,沒有超過4s的連貫鏡頭;其次,很不自然。
這些實用的工具,基本都是小公司出品的,功能並不完善。
說不完善都還算保守,簡直就是漏洞百出。
視頻內容歸根結底,是對現實世界的還原。既然如此,那其中必然包含大量交互鏡頭——物與物、人與人、人與物,等等。
就像用攝像機拍出來的片段一樣。
我們看電影、看視頻,看的也是交互,相信沒幾個人喜歡看一個人的獨白。
比如,玻璃杯從桌子上摔到地上,它應該碎掉;像皮球摔到地上,它應該彈兩下。
但讓AI去合成這類場景,你就會發現,它並不會還原以上的物理現象。物體與物體碰撞或疊加到一起,AI隻會讓其中一方變形。
這說明一個關鍵問題: 過去的AI並不理解現實世界的規律。

不符合人類常識的視頻,能有多大市場呢?
不理解基礎物理的AI,它的上限能有多高?
想要解決這個問題,難不難?很難。
現在的AI大模型,雖然是模擬的人腦,但畢竟有所區別。
最本質的區別在於: AI 沒有想象力。
比如,你一巴掌扇在我臉上,面部肌肉如何顫動?把一顆魚雷扔進池塘,水面如何散開?
我們可以想象到後續會發生的事情,AI 不能。
無論它的參數堆得多高、計算速度再快,都不能。
即便是目前的Sora也做不到。
從各種演示例子中可以看到,雖然Sora 對自然語言有著深入的理解,能夠準確洞悉提示詞,生成表達豐富的內容,甚至可以創建多個鏡頭、保持角色和視覺風格的一致性。
但是,它依然無法準確模擬出復雜場景的物理現象,因為它不理解因果關系。
比如,人咬一口餅幹,但餅幹上沒有咬痕;又或者混淆左右、不遵循特定的攝像軌跡;甚至無法理解,影子是人的影子還是物的影子……
如此一來的結果,便是合成有違物理常識的視頻。

既然如此,Sora到底牛在哪裡,為什麼這麼多人追捧它?
因為它其實做得足夠好,至少比同行們好太多。
用Fortune雜志的話來說就是: 將生成式AI之戰轉移到好萊塢。
用官網的話來說,它能夠生成包含多種角色和特定類型的運動,主體和背景細節準確;還能理解事物在物理世界的存在方式。
簡單來說,它雖然還不能理解需要想象力的因果律,但最基本的現實場景,它是可以還原的。
AI生成視頻這一條賽道,誕生至今還不到1年,我們確實不能要求太高。
如果把上文描述的內容當做終結目標,把去年至今的一系列生成工具作為雛形,Sora大概處在兩者之間。
它是如何做到的?
02 誰站在巨人肩上?
Sora主要采用兩種技術。
一個是擴散模型(diffusion model),原本是用於文字轉圖片的。
簡單來講,是先生成一張全是noise(噪聲)的圖片,與目標圖片的vector尺寸相同(比如目標圖片是256*256,初始sample圖片也要是256*256),然後經過若幹次denoise(去噪聲),讓圖片逐步成型。
問題在於,大模型怎麼知道去除什麼?保留什麼?
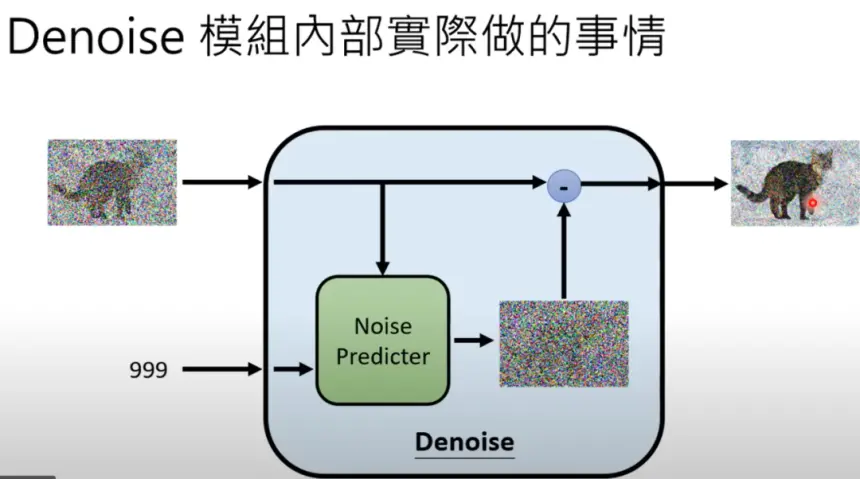
當然需要訓練。
研究人員得先用清晰的圖片,一步一步加噪聲進去,如下圖。
這是上圖的逆序,即反向擴散。
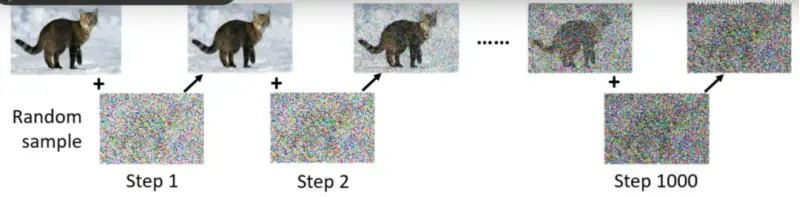
看懂上面兩個步驟,你才能理解MIT Technology Review究竟在說啥:
Sora的團隊使用DALL-E 3背後的技術,即擴散模型。擴散模型經過訓練後可以將模糊的隨機像素變成圖片。
其原理並不復雜,但需要時間和人力成本。
另一項技術是Transformer的神經網絡,就是GPT(Generative Pre-Trained Transformer)中的T。
但是,Transformer 架構人盡皆知,在文字、圖像生成上已經成為主流,為什麼別人沒想著在視頻生成上用,就OpenAI 用呢?
用技術的話來說: Transformer 架構中,全註意力機制的內存需求會隨著輸入序列長度而二次方增長。
說人話就是: 計算成本太高。
即便OpenAI背靠微軟,各種融資拿到手軟,也不願意這樣燒錢。
所以他們開發一個視頻壓縮網絡,先把視頻數據降維到latent(潛空間),再將壓縮過的數據生成 Patche,這樣就能使輸入的信息變少,有效減小計算量壓力。
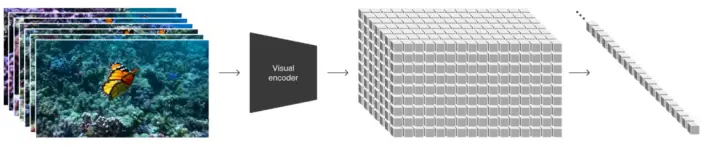
然後,為讓大模型更好理解用戶的意思,OpenAI 直接把文生視頻模型套進已經得到市場認可的GPT模型范式中,這就是它獨有的優勢。
使用者輸入的提示詞,並非直接交給Sora,而是先讓成熟的GPT將文本進行精準詳細的擴寫。
Sora再根據GPT提供的詳細文本,逐幀生成更準確的視頻。
說實話,個人認為,這才是Sora有別於其他模型的最大優勢。
其他團隊即便能解決其他步驟,但沒有成熟的大模型,也是白搭。
整體上看,Sora的成功幾乎是水到渠成的。
它能有如今驚艷的表現,基本全部得益於OpenAI過去的成果,有些是借用思路,有些則是不可或缺的基本架構。
這就是所謂的先發優勢,它不僅僅體現在老生常談的壟斷問題上面。
一生二、二生三、三才生萬物。
反觀OpenAI此時此刻全世界的各大競爭對手,無一例外全部卡在文生文、文生圖上。
更有甚者,連一都沒有的,還是老老實實抓緊做底層。不然等先發者三生萬物,真的是什麼都晚。
我們能明顯感覺到,AI比過去任何行業的迭代都要快。
也許,這個技術差隻要維持兩年,就會變成永遠無法逾越的鴻溝。
所謂“差距隻有幾個月”、“彎道超車”,基本是不存在的。
03 尾聲
正如上文所說,Sora目前仍有很大缺陷。
它能生成復雜、精美且足夠長的視頻,這證明AI在理解現實世界的能力上有相當大的提升。
但這種提升,依然基於大量的訓練,而不是AI本身對世界的理解。Sora對視頻的處理依舊是有很多局限性,甚至包括很基本的事實錯誤。
所以Sora給人的感覺雖然震撼,但還稱不上這兩天熱烈討論的“世界模型”。
所謂“現實不存在”,絕對不是指現在。
但未來說不準。
在我們普通人眼中,Sora就是個文生視頻模型。它的出現,意味著大多數影視、視頻制作從業人員,即將失業。
但對OpenAI團隊而言,並不僅此而已——這必然是他們構建AGI(通用人工智能)的重要環節。
AGI與世界的交互不僅體現在文字、圖片和語音等形式上,還有更直接的視覺視頻,這也是人類自古以來認知和理解世界最重要的方式。
所以生成視頻、理解視頻和理解物理世界,是未來AGI必備能力之一。
此時此刻,我們還能想象得到,生成式AI會對影視、遊戲制作行業造成天翻地覆的影響。
等到通用人工智能問世的那一刻,AI到底能做什麼、會對世界造成多大的影響?
所有人都能想象到的,是必然會應用到具身智能,也就是機器人上。
但除此之外呢?抱歉,想象力有限,真的想象不出來。
或許,AI真的就是全人類期待幾十年的那個技術奇點。你知道某些事情會發生,但無法想象究竟是什麼事。(如果能想象,那也就不叫奇點)
隻能祈禱,未來是星辰大海,商機遍地。