太瘋狂!Claude3Opus超越GPT-4,成為新的國王!今天,ChatbotArena更新聊天機器人對戰的排行榜,在經過時間的洗禮和群眾的檢驗之後,之前略遜於GPT-4的Claude3竟然反超!
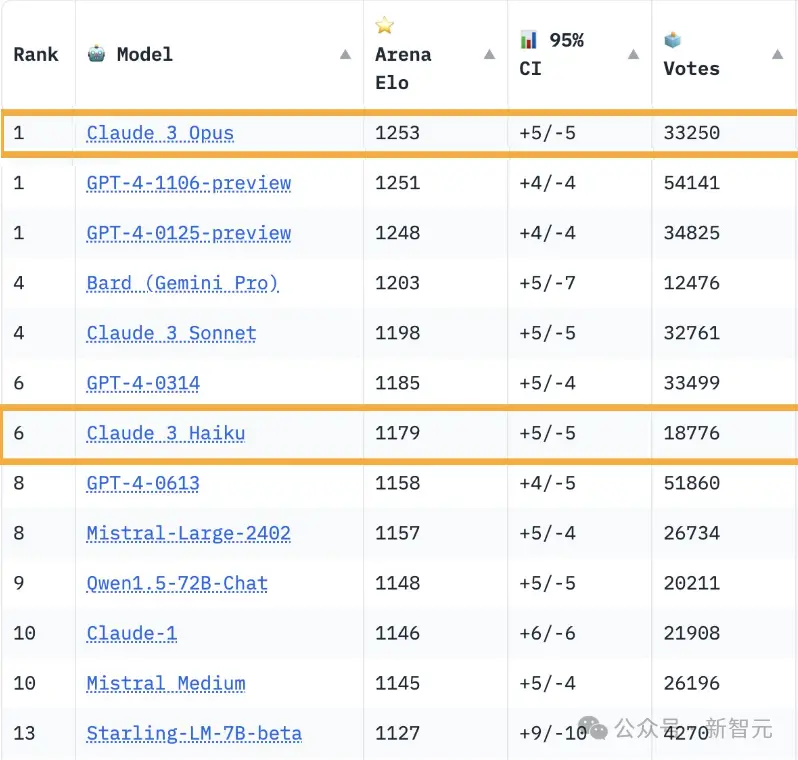
而且不僅僅是Claude 3的超大杯Opus成功登頂,藐視眾生,Claude 3傢族的整體表現都非常亮眼。
大杯Claude 3 Sonnet排到第4,就連最小的Claude 3 HaiKu都達到GPT-4水平!
那麼相比於基準測試跑分,這個榜單的權威性如何?
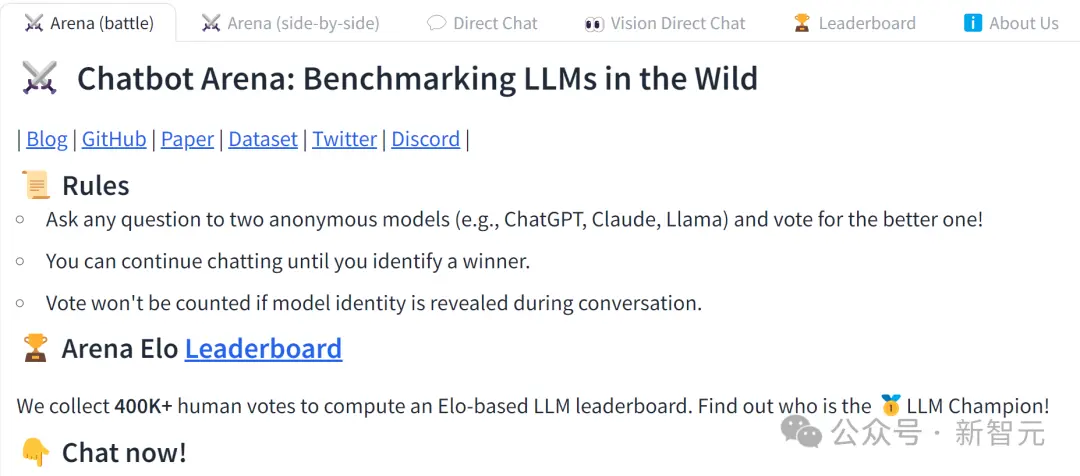
Chatbot Arena(聊天機器人競技場),由伯克利團隊開發,每個模型在榜單上的得分,完全取決於真實人類用戶的使用體驗。
我們來看一下打分規則:
用戶同時向兩個匿名模型(比如ChatGPT、Claude、Llama)提出任何相同的問題,然後根據回答投票給表現更好的模型;
如果一次回答不能確定,用戶可以繼續聊天,直到確定獲勝者;
如果在對話中透露模型的身份,則不會計算投票。
Chatbot Arena平臺收集超過40萬人的投票,來計算出這個大模型的等級分排行榜,最終找出誰是冠軍。
顯然,這回Claude 3贏麻。
我們來看一下真實的戰況:
在所有非平局對戰中, A對B獲勝的比例:
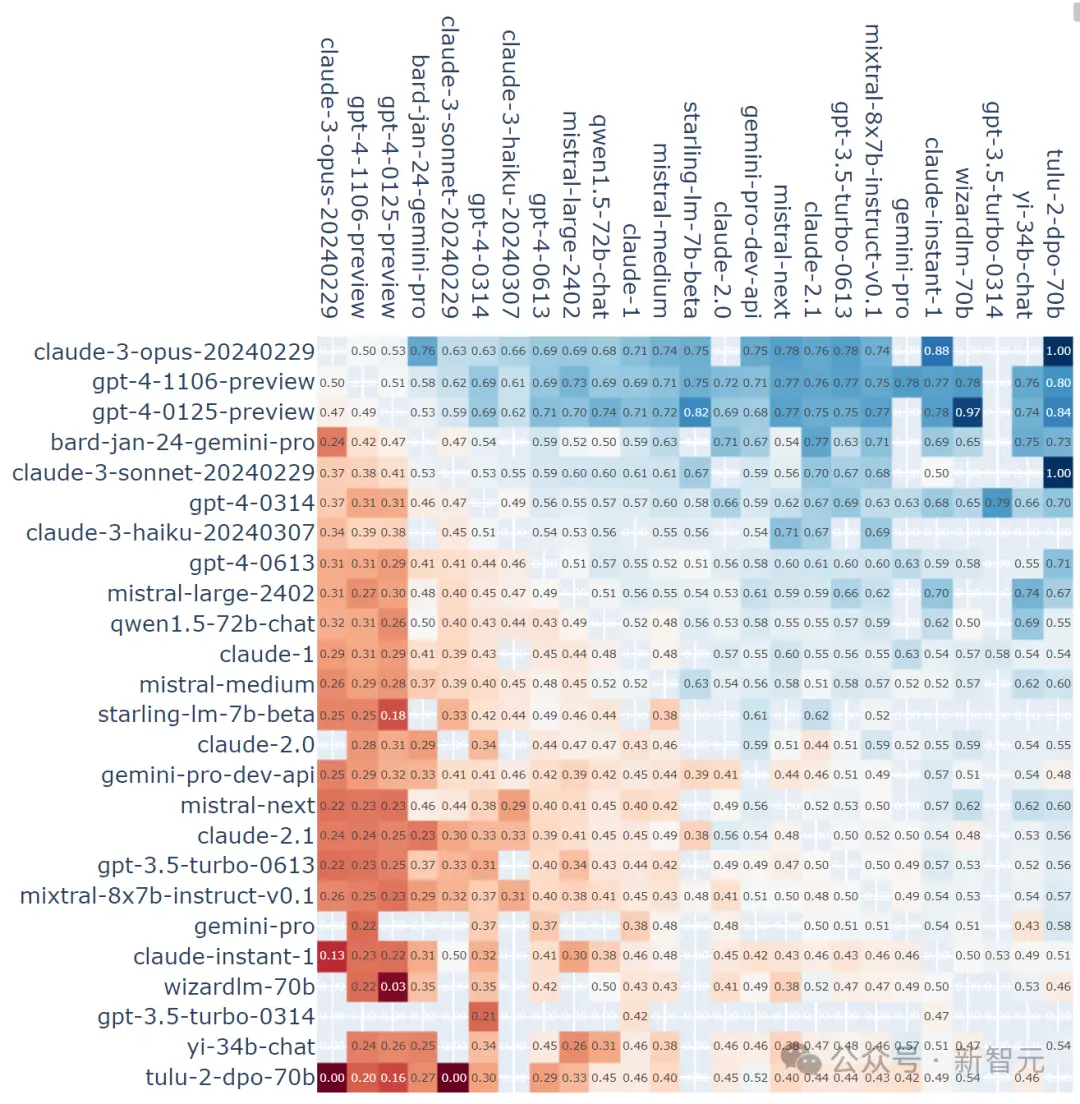
模型之間的對戰次數(無平局):
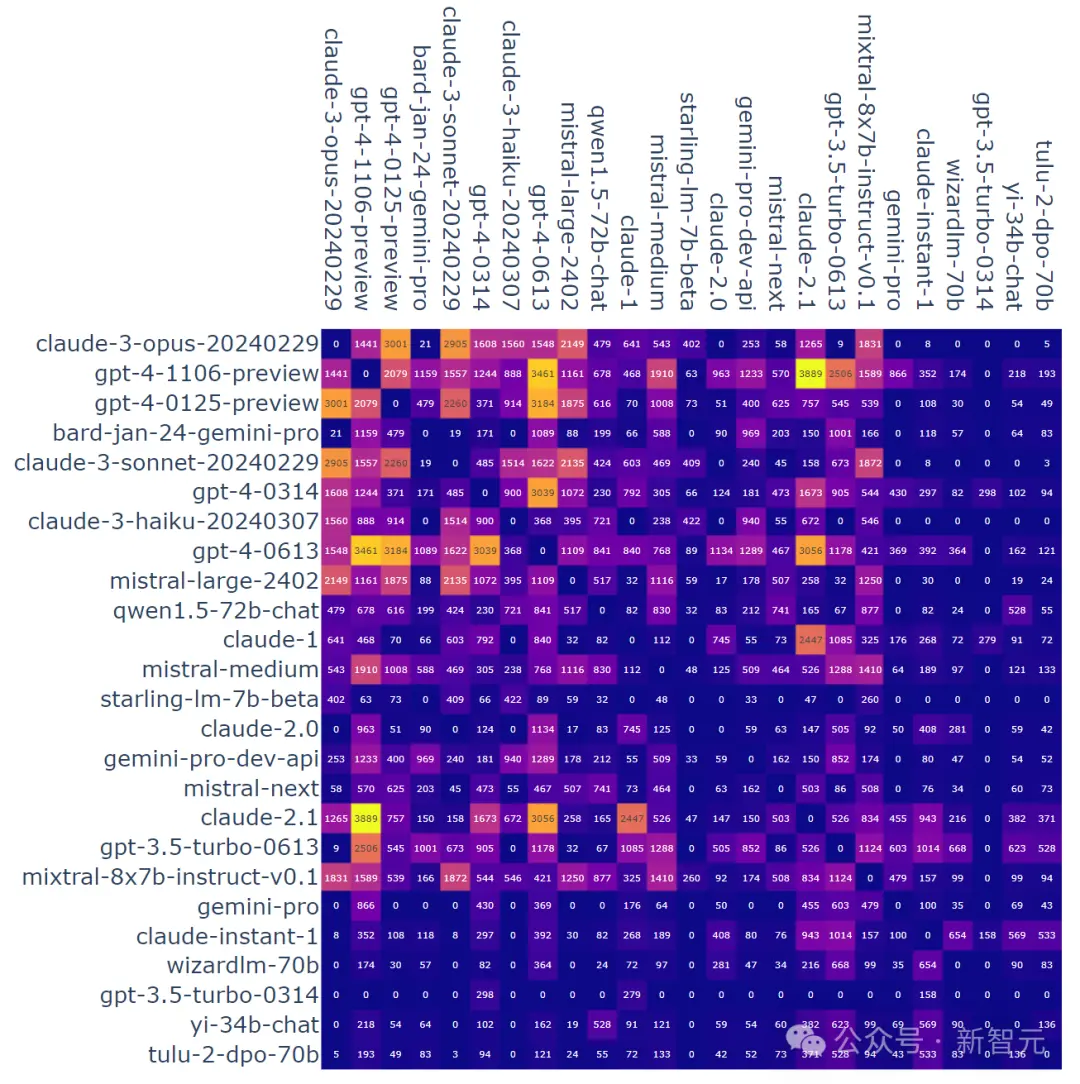
GPT-4終於被幹掉,對此,有網友開始惡搞:

剛在當地超市看到Sam Altman,他一臉震驚地看著手機。幾秒鐘後,他真的倒下,開始劇烈顫抖。經過2分鐘的搖晃和尖叫,一群人圍繞著他試圖幫助他。但令人驚訝的是,他在2分鐘後停止顫抖和尖叫,站起來,拿起手機開始撥打一個號碼。
“準備釋放......”
咱也不知道Altman要放的是不是GPT-5。
網友表示,Claude確實要比GPT勤奮得多:
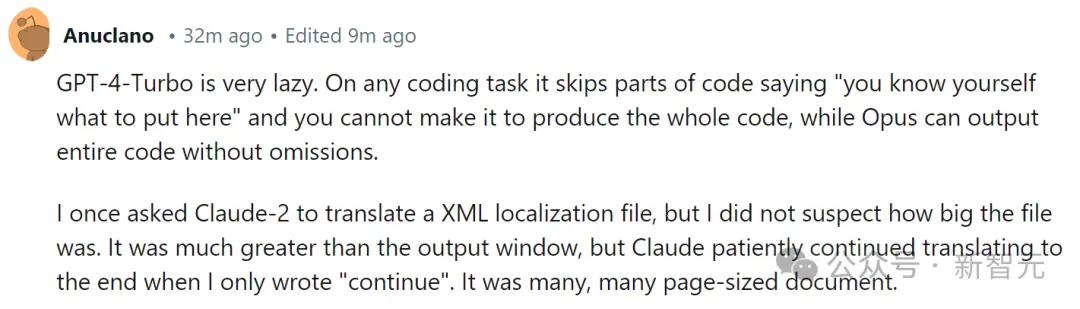
GPT-4-Turbo非常懶惰。在任何編碼任務中,它都會跳過部分代碼,並表示“你自己知道要放什麼”,而Opus可以毫無遺漏地輸出整個代碼。
就連Claude-2也通過自己的勤奮和耐心感動這位網友。
更有比較務實的網友指出,Haiku的排名更為重要,因為它是第一個可以以極低成本即時運行的LLM,並且具有足夠高的智能來提供實時客戶服務。


盲生你發現華點!Claude 3 Haiku不僅與原始版本的GPT-4表現一樣好,關鍵是相當便宜,在一些平臺你甚至可以免費使用。
大傢於是紛紛誇起Claude 3 Haiku:
智能相當於GPT-4,價格比GPT-3.5便宜,而且據說模型可能隻有20B大小。

有網友表示,OpenAI不行啦,現在Anthropic才是老大,一時間,平臺內外充滿快活的空氣。

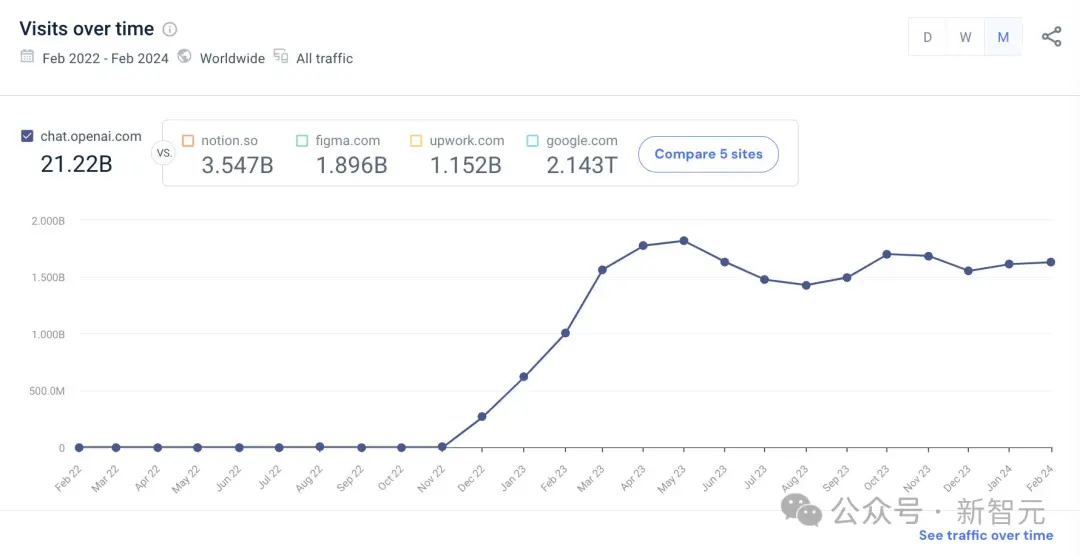
ChatGPT 一年零增長
回過頭來再看ChatGPT這邊,從最初的高光、王者,到現在不能說泯然眾人吧,反正多少有點寒酸。
最近,有關統計平臺曝出:ChatGPT在過去一年中居然零增長!
最近一段時間,ChatGPT一直被指責懶惰、系統提示臃腫,而另一方面競爭也愈演愈烈——Claude 3和Gemini Pro 1.5現在都提供比GPT-4多8倍的上下文長度和更好的recall能力。
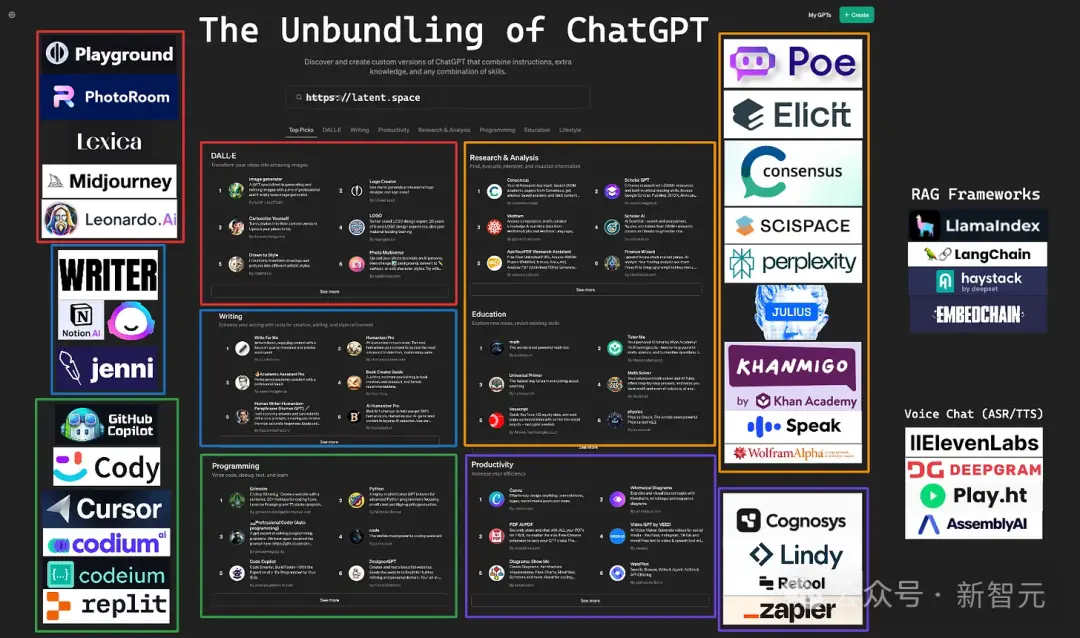
對於幾乎每個ChatGPT用例,現在都有大量垂直化的AI初創公司,致力於滿足用戶的需求,而不是滿足於現有的ChatGPT界面和捆綁工具
它們有更好的UI選項(例如IDE和圖像/文檔編輯器)、更好的原生集成(例如用於cron重復操作)、更好的隱私/企業保護(例如用於醫療保健和金融),更細粒度的控制(GPT的默認RAG是幼稚且不可配置的)。
以下是一些網友列舉相關垂直領域的產品,以及公司的融資情況:
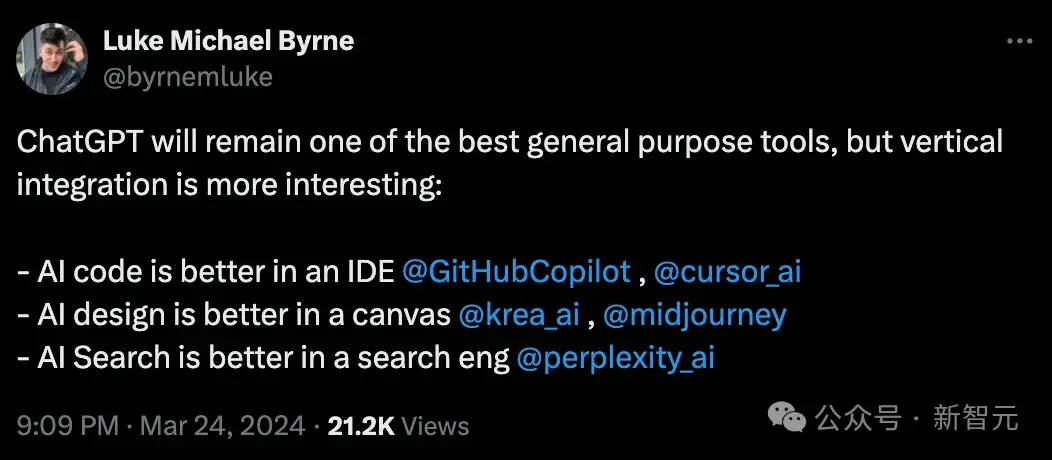
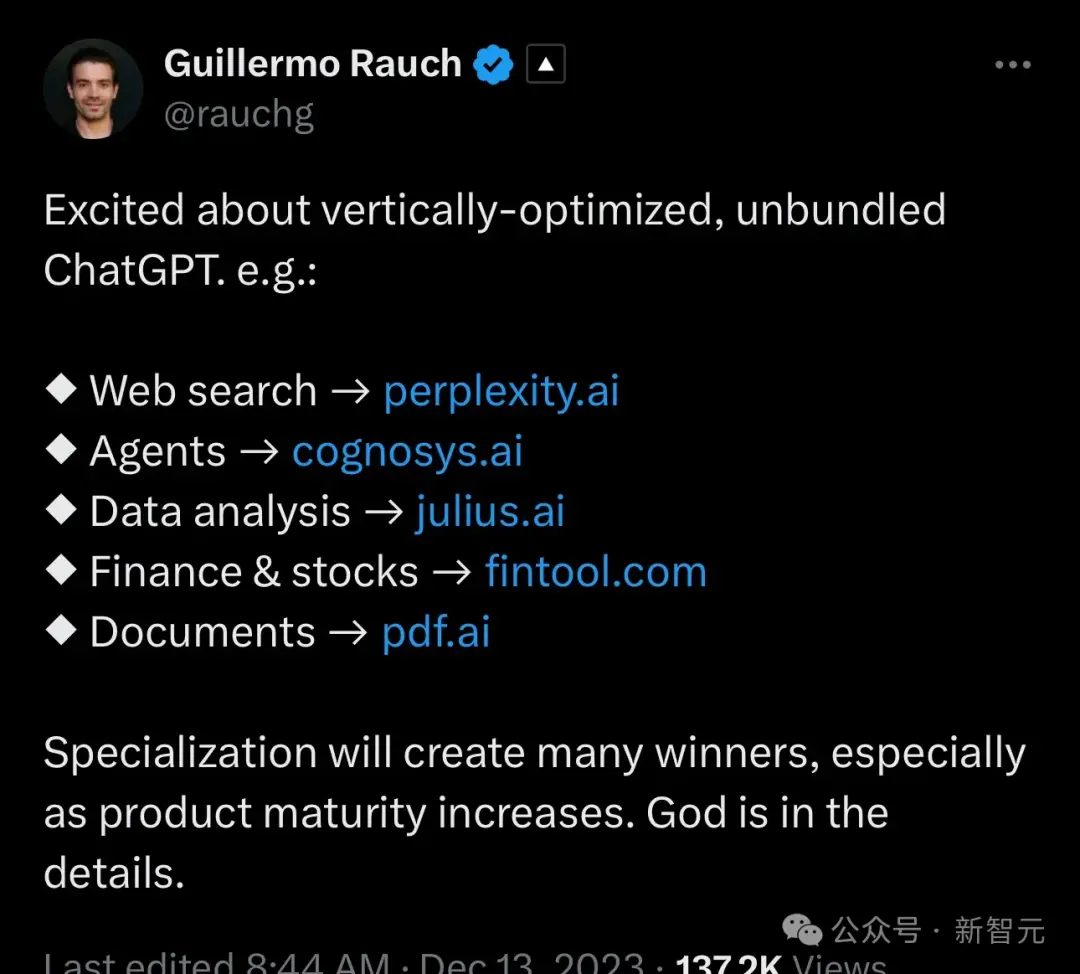

從某種意義上說,OpenAI的B2B和B2C部分相互競爭,這在某種程度上是良性競爭——OpenAI可以使用來自ChatGPT的RLHF數據進行訓練。
而新的GPT商店可以看作是,OpenAI為抓住這些垂直化需求的嘗試。
——與其離開平臺,到處支付20美元/月,為什麼不留在ChatGPT內部而隻需要支付一次,讓OpenAI將理論上的收入分配給GPT創作者?

對此,大部分創作者也很明智,一般隻向ChatGPT發佈精簡版的應用,作為自己主要平臺的一個渠道。
在遊戲機業務中,眾所周知,購買決策往往是由平臺獨占遊戲驅動的。從某種意義上說,ChatGPT的未來會以平臺專屬模型為特色。

所以,當Sora甚至是GPT-5公開發佈時,一定會率先登陸自傢的平臺,也許那將是下一輪ChatGPT的增長點。