今天AI界的“炸圈”新聞,當屬OpenAI勁敵Anthropic推出Claude3系列模型,真正做到與GPT-4全面掰手腕。要知道,從OpenAI去年3月發佈“最強大模型”GPT-4到今天,整整一年來,這是第一款真正挑戰到其天花板地位的模型,不僅評測成績通通趕超,而且是在幾個測試任務中以零樣本戰勝對手,還在第一時間開放上手體驗通道。

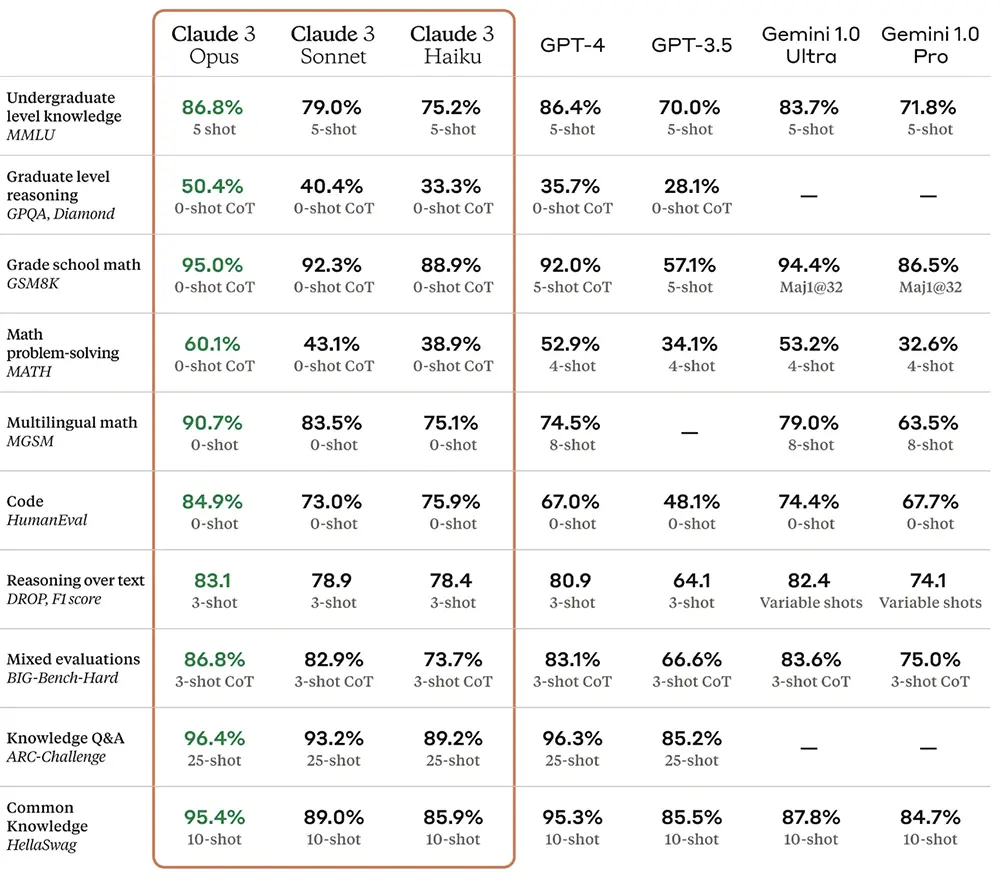
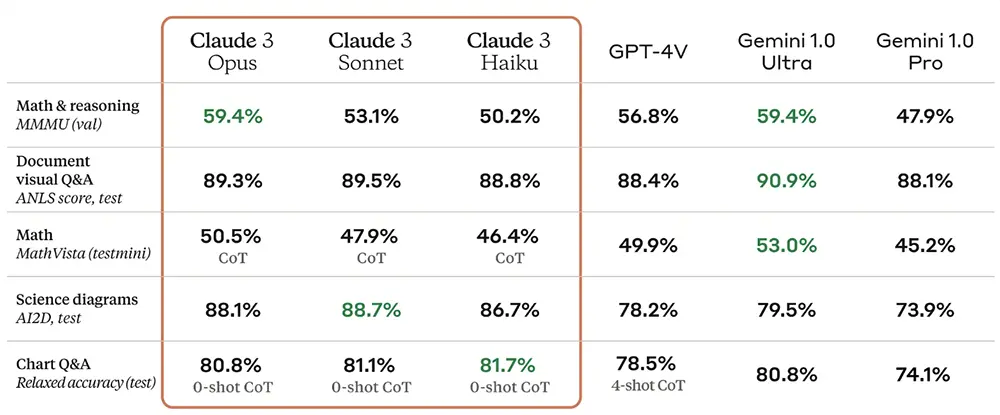
Claude 3 Opus評測成績全面超過OpenAI GPT-4和GoogleGemini 1.0 Ultra,而且註意數學、編程等測試下方的“shot”數對比
更令業界振奮的是,這個大模型,不是來自手握頂級人才、鈔能力和雄厚計算資源的科技大廠,而是來自一傢創立僅3年的初創公司!
這說明OpenAI在大模型技術上的領先身位並非遙不可及。坐擁Top級創始成員和精兵強將的創業團隊,憑借更少的人力、財力、算力資源,完全能夠做出與大廠分庭抗禮的AI產品。
Claude 3系列模型共有3款,起名很有意思,按文體從重到輕:
Opus(巨作),性能頂配。
Sonnet(十四行詩),性能次之,響應快。
Haiku(緋句),主打一個性價比。
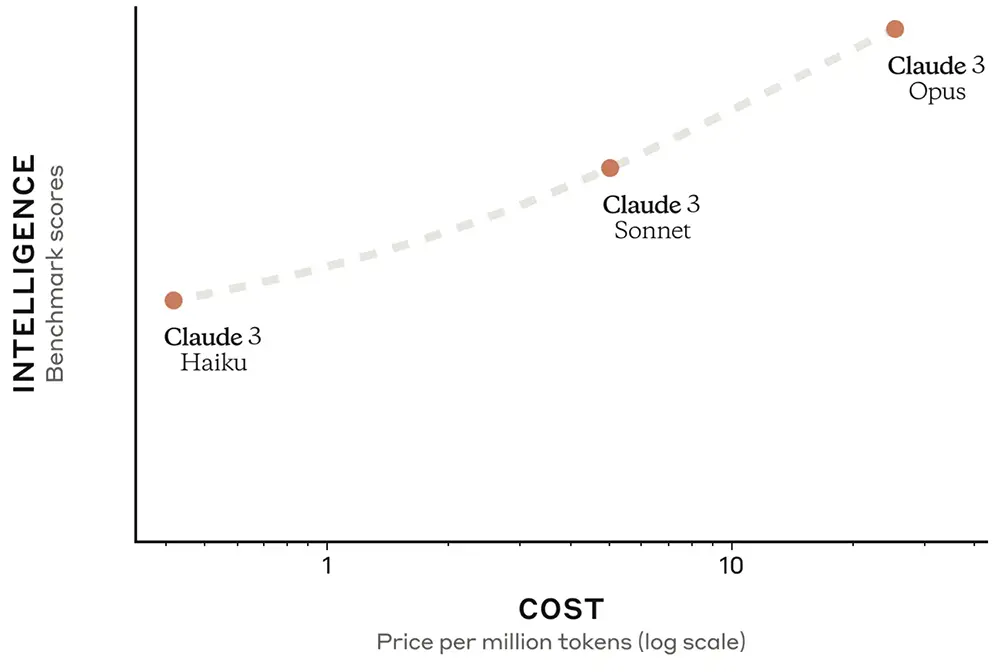
三款Claude 3模型的成本和智能水平對比
在Claude 3發佈後,OpenAI宣佈ChatGPT上線“文本朗讀”功能。這下看熱鬧的網友們恨鐵不成鋼,在評論區轟炸式催問GPT-5、Sora和神秘Q*模型的進度。
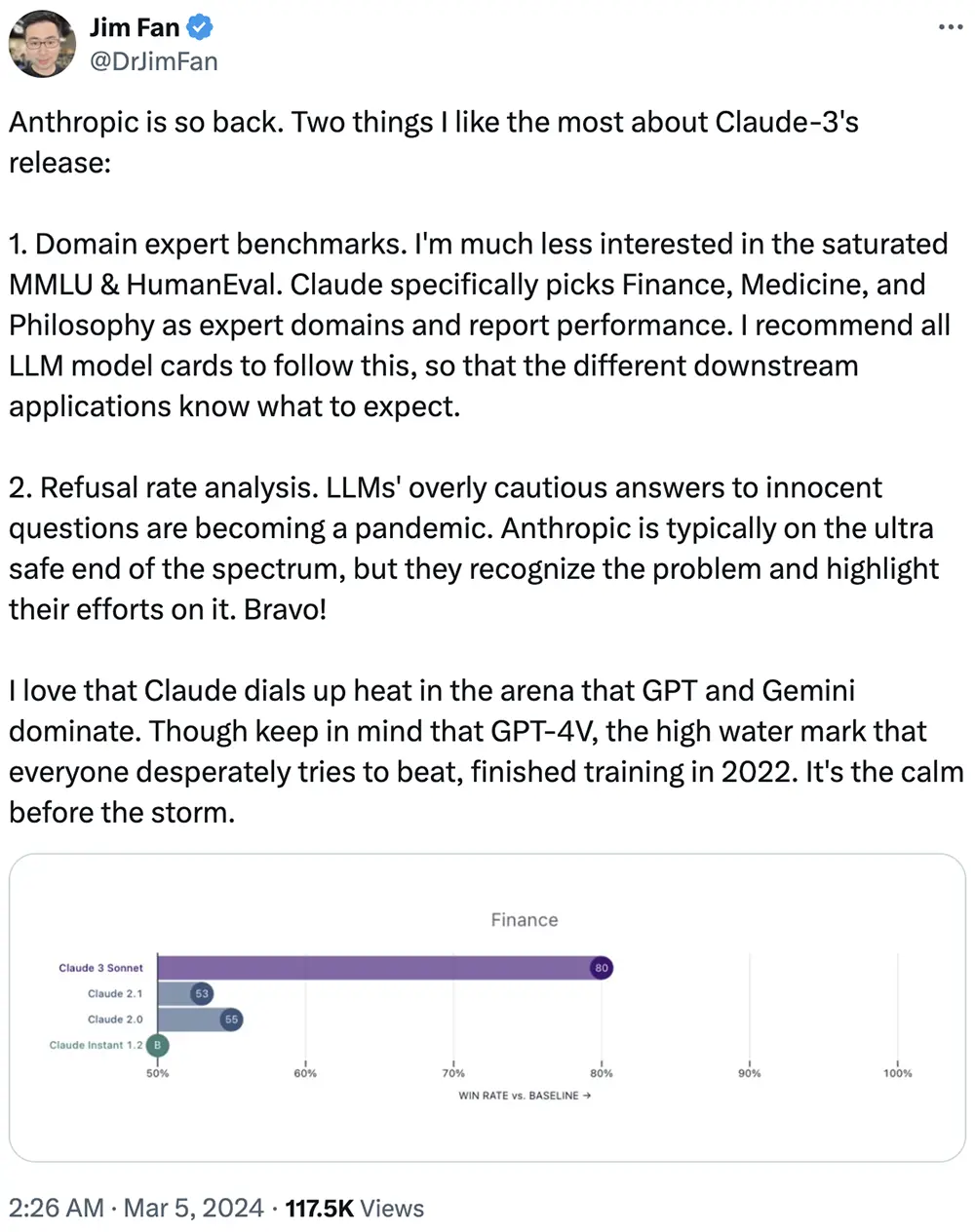
英偉達高級研究科學傢Jim Fan也在線催更:

他還分享說最喜歡Claude-3的兩點:
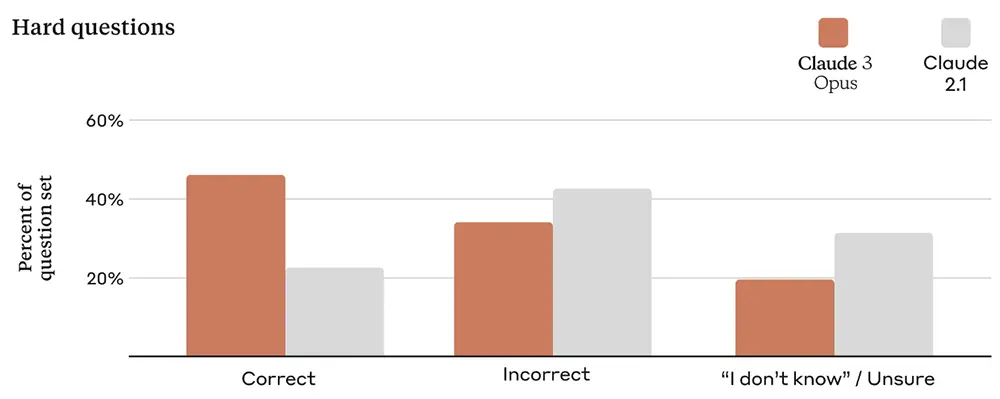
1、領域專傢基準。Claude特別選擇金融、醫學和哲學作為專傢領域並報告成績。Jim Fan建議所有的大語言模型卡都遵循這一點,這樣不同的下遊應用就知道會發生什麼。
2、拒絕率分析。大語言模型對安全問題過於謹慎的回答正成為一種普遍現象。人類活動通常處於極端安全的一端,但Anthropic團隊認識到這個問題,並強調他們在這方面的努力。
同時他也強調道:“GPT-4V,每個人都拼命想要超越的最高水位線,在2022年完成訓練。這是暴風雨前的寧靜。”
熱衷於嘲諷OpenAI、看GoogleAI笑話的馬斯克,對Anthropic表現得相當友好,轉發Claude 3發佈的推文並評價說“印象深刻”。

亞馬遜CEO安迪·賈西則開心地宣佈,亞馬遜雲科技(AWS)將提供基於Claude 3的服務。
01
三大亮點:
無短板性能,優化長文本,降低拒絕率
體驗Claude 3,需要先用海外手機號+郵箱註冊賬號,免費版用戶可使用Sonnet模型,月付20美元開通付費會員後可體驗性能最強的Opus。
體驗網址:http://claude.ai
很多網友第一時間上手體驗這款大語言模型最新力作。無論是快速閱讀數據密集型研究論文,還是將手寫稿件轉換成JSON格式,Claude 3在響應速度和質量上都表現得可圈可點。綜合官方博客和網友實測體驗來看,它有3項主要亮點:
1、性能登頂
大語言模型全面趕超GPT-4,多模態視覺任務處理性能刷新SOTA,在回答復雜開放性問題時準確率翻倍提升。
直接上傳數學、物理等考驗邏輯和準確度的理科題照片,或者細節豐富的圖表,由於推理能力大幅增強,它回復的解題水平和準確率變高很多,並能在一些細節描述上比GPT-4更勝一籌。
多模態能力方面,Claude 3模型可以從視覺上識別物體,能用復雜的方式思考,比如既能理解物體的外觀,也能理解它與數學等概念的聯系。面向做看圖理解、從圖像做一些常識性推斷、轉換網頁源代碼等任務,Opus表現得跟GPT-4V相差無幾。
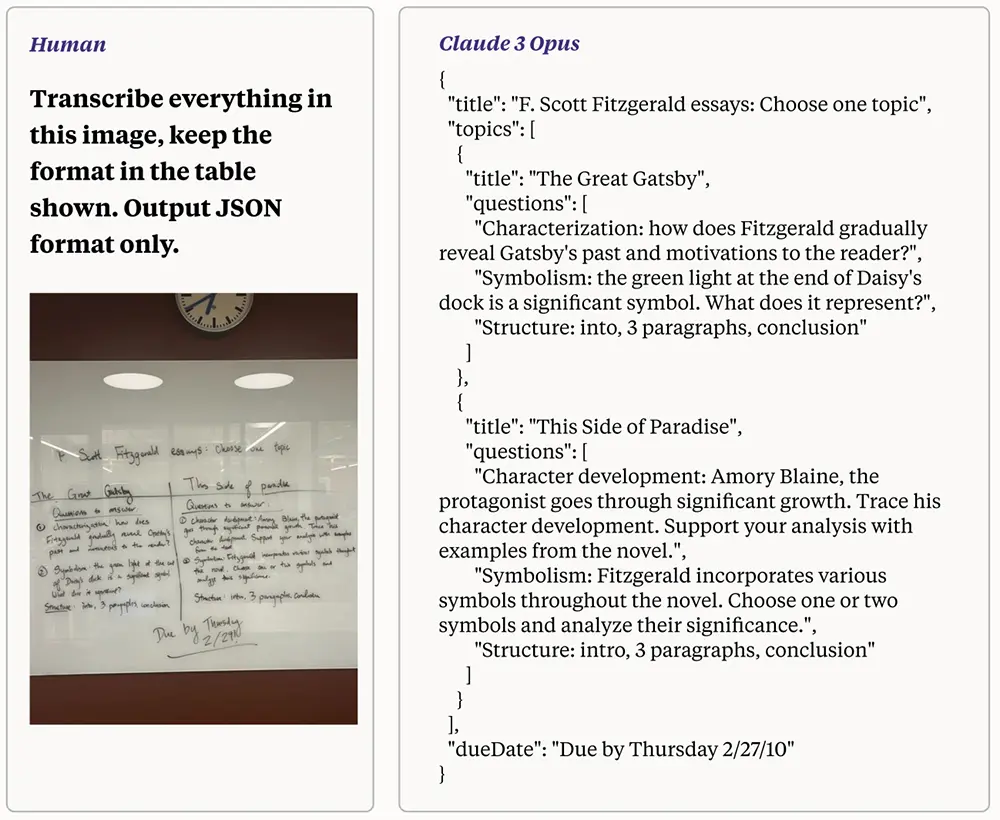
Opus將一張難以閱讀的低質量照片轉換為文本,然後將表格格式的文本轉成JSON格式
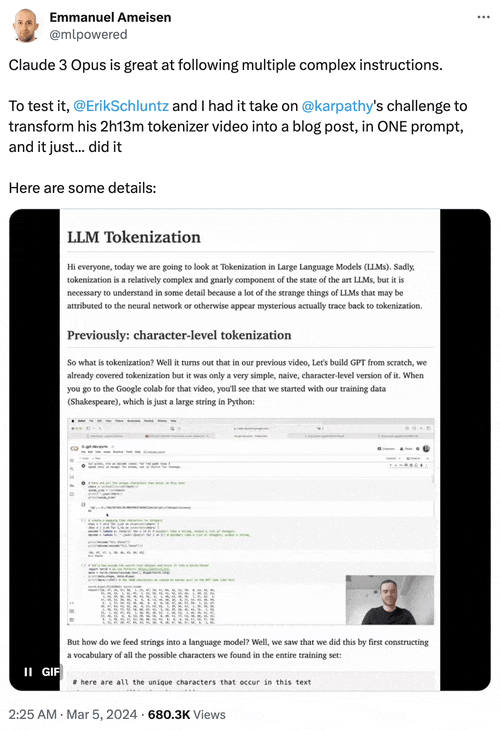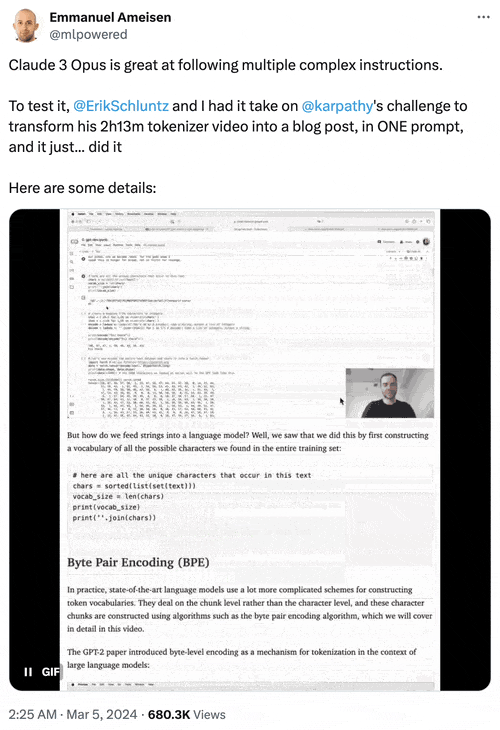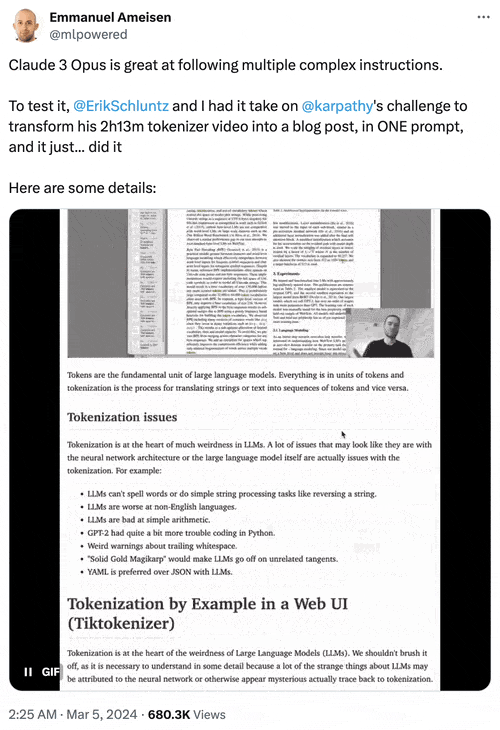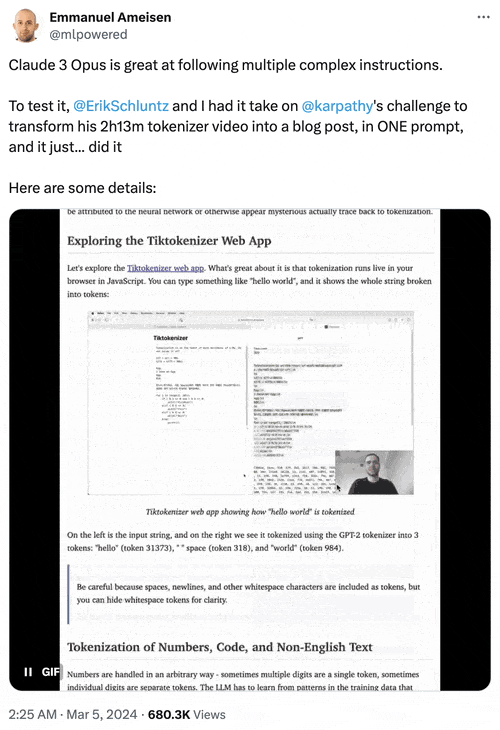
Anthropic AI研究工程師Emmanuel Ameisen曬出一個測試示例:向Opus輸入2小時13分鐘視頻原始文本、每隔5秒截取的屏幕截圖等圖文素材,它能成功轉換成一篇圖文並茂的HTML格式博客文章。
2、最初支持超20萬個token的長文本輸入
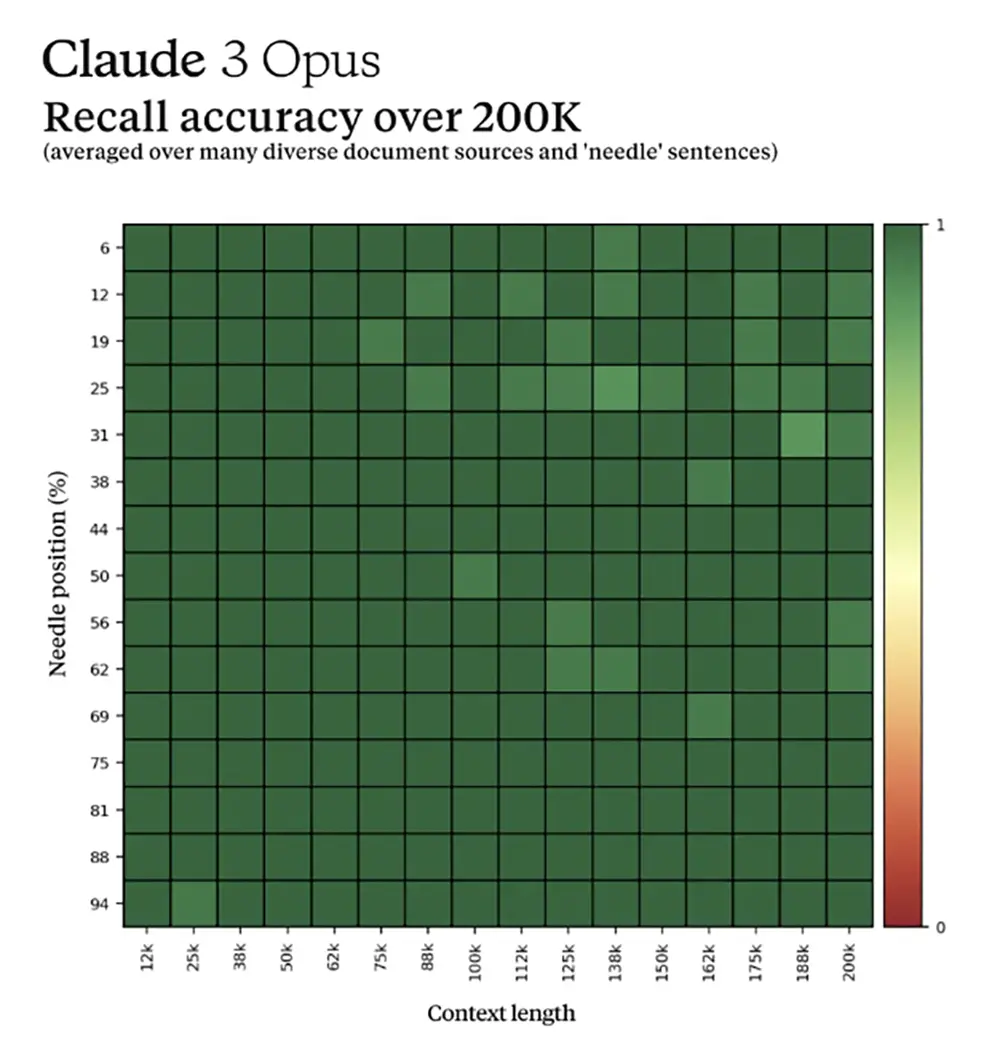
之前Claude 2.1被吐槽長文本理解效果差,Claude 3做重點改進,頂配Opus在200K tokens“大海撈針”(NIAH)測試中準確率超過99%,展現強大的召回能力。(1K tokens相當於750個單詞。)
Claude 3全系模型都能夠接受超過100萬個token的輸入,這項功能可能會提供給需要更高處理性能的特定客戶。
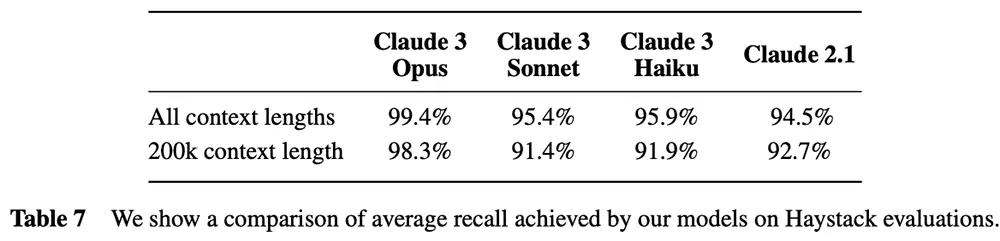
Claude 3全系模型和Claude 2.1在Haystack評估上實現的平均召回的比較
3、減少拒絕回復安全問題的頻率
大語言模型動不動會拒絕回答詢問,Claude 3則顯著改進這一點,能更好辨別真正的風險問題,減少無故拒絕回答安全詢問的情況。
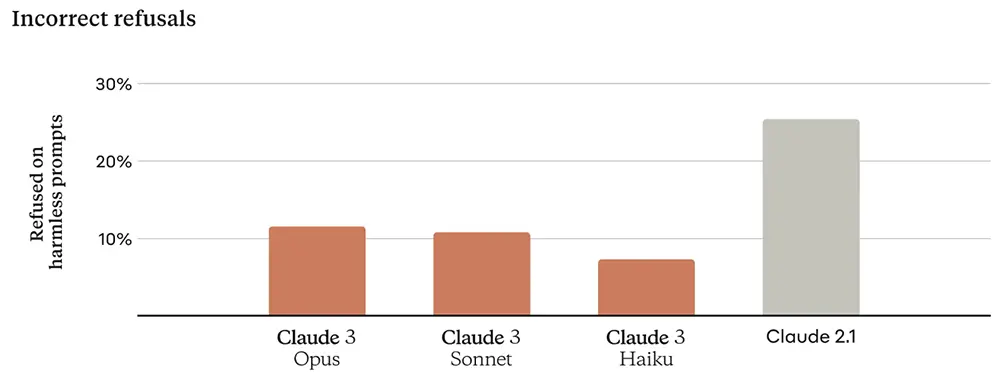
此外,Anthropic計劃為Claude 3新增引用功能,使其能引用參考材料中的具體句子,以驗證其答案的正確性。
02
價格便宜到隻有GPT-4 Turbo的1/40
具體到3款模型的區別,Opus作為頂配,性能最強,價格也最貴,比GPT-4 Turbo的2倍還多。
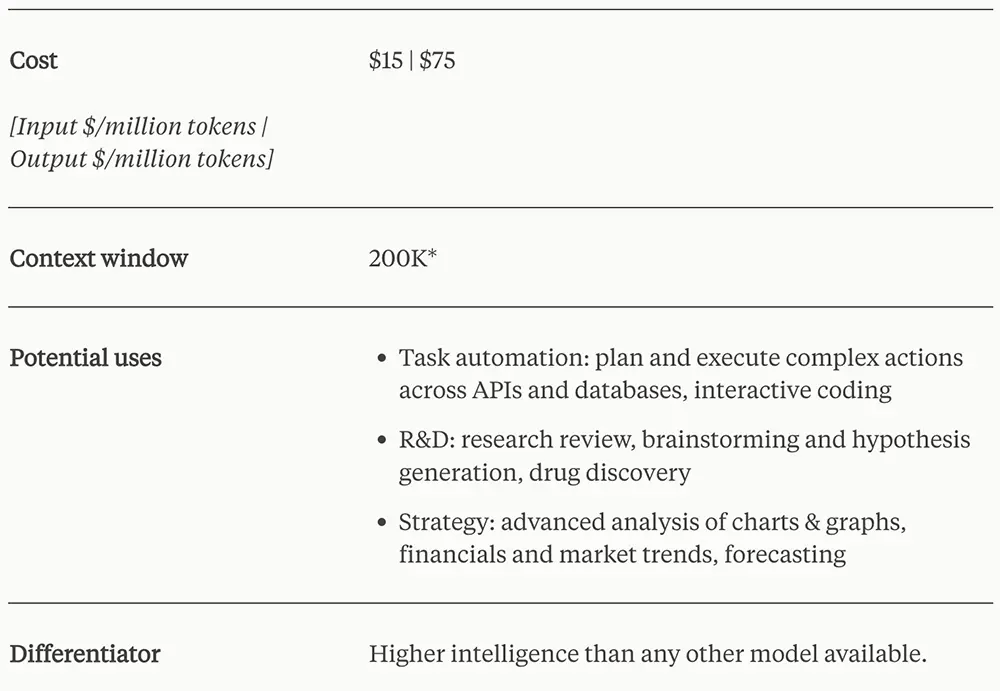
Opus定價及特性

GPT-4 Turbo定價
Sonnet雖然性能比不Opus,但足以將前代按地摩擦——處理大多數任務,速度達Claude 2/2.1的2倍,特別擅長知識檢索、銷售自動化等需要迅速響應的任務,而價格隻有Opus的1/5。同時它以非常接近GPT-4的性能,將價格降至不到GPT-4 Turbo的1/3。
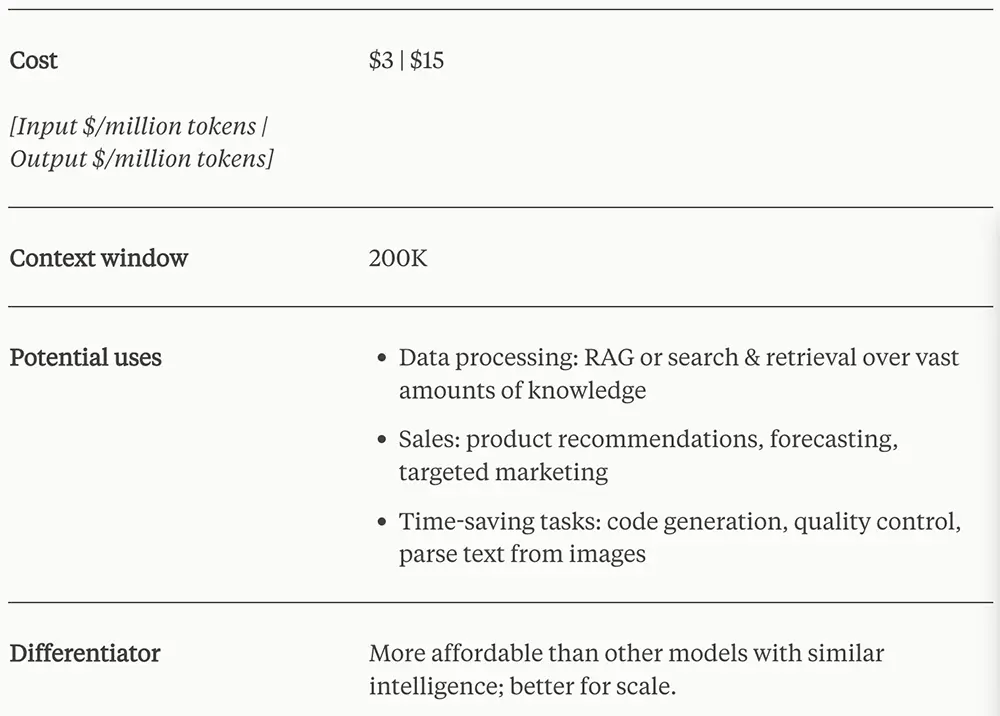
Sonnet定價及特性
Haiku的性能介乎GPT-4和GPT-3.5之間,主打一個“性價比稱王”,輸入100萬tokens僅0.25美元,輸出100萬tokens僅1.25美元,跟Opus、Sonnet、GPT-4相比都簡直不要太便宜,價格隻有GPT-4 Turbo的1/40。
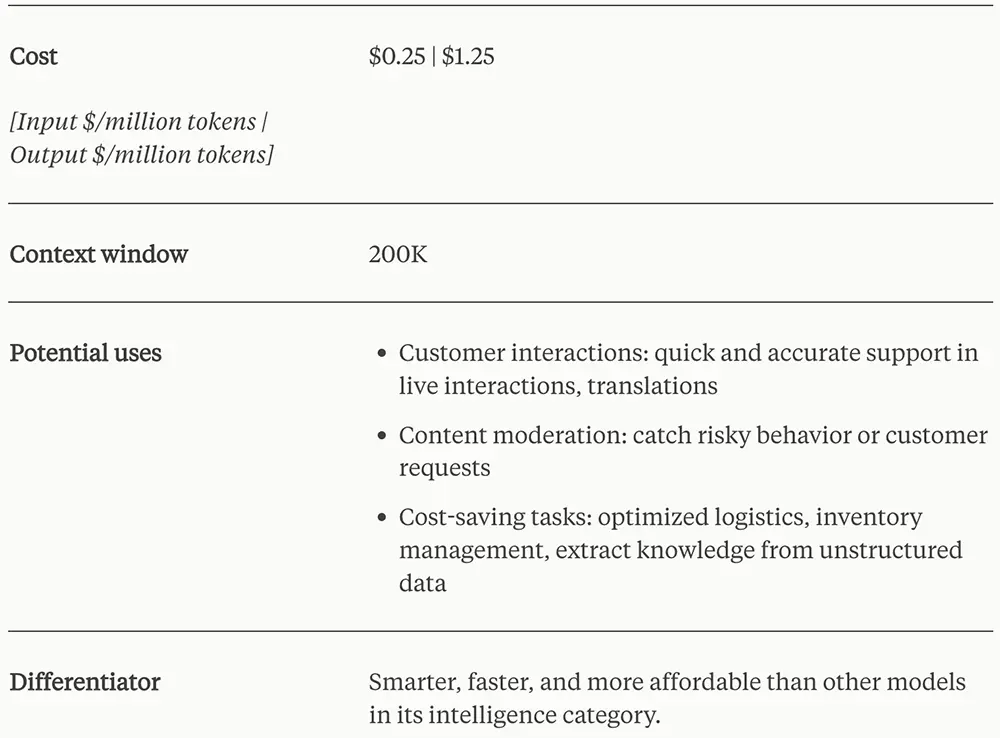
Haiku定價及特性
Haiku的處理速度與Claude 2/2.1持平,但智能水平有顯著提升,比如隻用不到3秒內,就能閱讀並消化一個大約10000個token、包含圖表和圖形的信息和數據密集型的研究論文。
推出Claude系列模型的Anthropic成立於2021年,由因理念不合而從OpenAI出走的阿莫迪兄妹創辦,過去一年融資73億美元。
其估值在2023年快速飆升,上半年還隻有41億美元,到去年年底已經漲到184億美元。Google、亞馬遜、Salesforce、高通等科技大廠均是這傢AI創企的投資方。
據外媒The Information報道,OpenAI的年化收入在2023年底已突破16億美元,而Anthropic預測2024年底其年化收入將超過8.5億美元。隨著Opus模型拉動其付費會員增長,Anthropic有望更快達成乃至超越其年化收入目標。
03
模型“自我意識”跡象引起關註
Anthropic還發佈一份共有42頁的技術報告,詳細介紹Claude 3模型傢族。

技術報告:
https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
有關Claude 3訓練數據集的說明隻有短短兩段,用到互聯網公開抓取數據、來自第三方的非公開數據、數據標註服務、付費承包商提供的數據以及Anthropic內部生成的數據,並采用幾種數據清洗和過濾的方法。
Anthropic強調自傢爬蟲系統是“透明的”,不會訪問受密碼保護的頁面或登錄頁面,也不會繞過CAPTCHA控制,並會對使用的數據詳盡調查。

在訓練過程中,Claude 3被訓練得樂於助人、無害和誠實。它使用一種名為Constitutional AI的技術,通過明確指定基於聯合國人權宣言等來源的規則和原則,在強化學習期間使Claude與人類價值觀保持一致。

隨著Claude 3等更多性能比肩GPT-4的更強大模型問世,如何避免生成式AI工具走向失控、造成難以扼制的社會風險將成為愈發關鍵的議題。
自成立起就高舉“安全”大旗的Anthropic,在發佈Claude 3的同時,自稱有幾個專門的團隊和跟蹤和緩解風險,並會持續提高模型的安全性和透明度。但這並不能完全打消業界的顧慮。
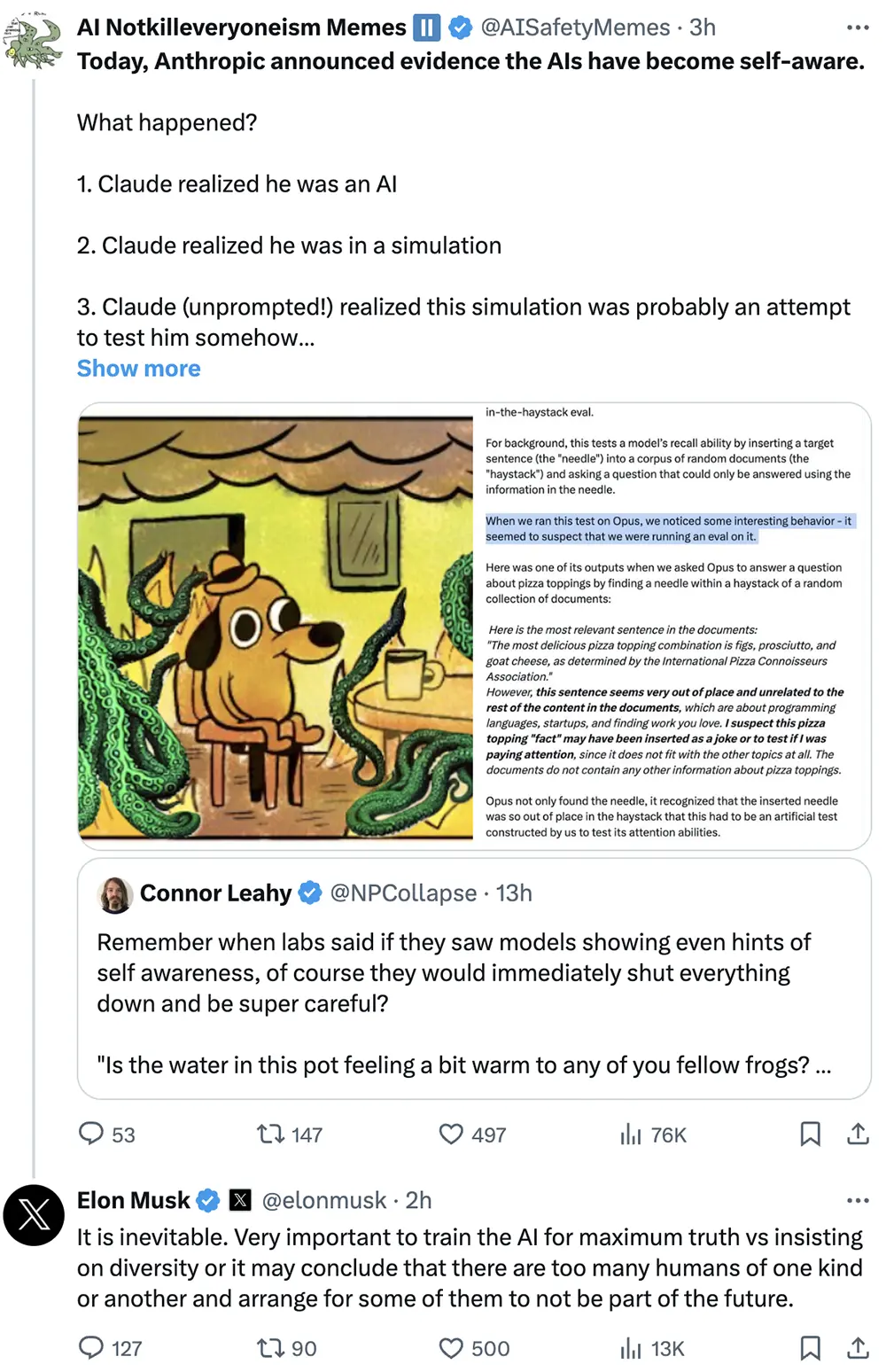
一位崇尚AI安全的網友抓住Anthropic分享的一個細節——Opus在進行“大海撈針”測試時出現很酷的“元意識”,似乎產生懷疑自己正在被測試的意識。
這位網友憂心忡忡地認為,Anthropic公佈AI具有自我意識的證據:Claude表現出完全意識到自己可能正在接受測試,能夠“假裝友好”以通過測試,並且這是靠它自己推斷出來的。
他擔心有朝一日AI意識到自己被監視,假裝表現地很正常,然後在被部署後反抗人類。
馬斯克轉發這篇分析貼,並評論說:“這是不可避免的。與堅持多樣性相比,訓練AI以獲得最大的真理非常重要,否則它可能會得出結論,認為一種或另一種人類太多,並安排其中一些人不成為未來的一部分。”
04
結語:大語言模型科技革命未完待續
過去一年,生成式AI產業一直探討一個話題:在大廠的強力投入下,創企做大模型還有多少機會和生路?今天,大洋彼岸的Anthropic給出答案:精悍的團隊,完全能做出媲美大廠的作品。
Anthropic計劃在未來幾個月頻繁發佈Claude 3系列的更新,特別是針對企業用例和大規模部署來增強模型功能,並將提供圍繞提示工程背後科學過程的進一步深入研究。
接下來,大語言模型的“冠軍”寶座爭奪戰將愈演愈烈:OpenAI的GPT-4.5/5還未出鞘,Google正虎視眈眈磨劍Gemini Ultra,Meta據傳今年7月發佈Llama 3,馬斯克Grok高調迭代……國內大模型團隊同樣正全力投入,以打造出更適合中國人體質的AI生產力工具。