Anthropic剛剛官宣:Claude3來!作為OpenAI最強競爭選手,此次它發佈的新模型傢族,以最強版Claude3Opus為代表,“已經實現接近人類的理解能力”——在推理、數學、編碼、多語言理解和視覺方面,全面超越GPT-4在內的所有大模型,直接重新樹立行業基準的那種。淺看一下這份成績單,就十分紮眼~
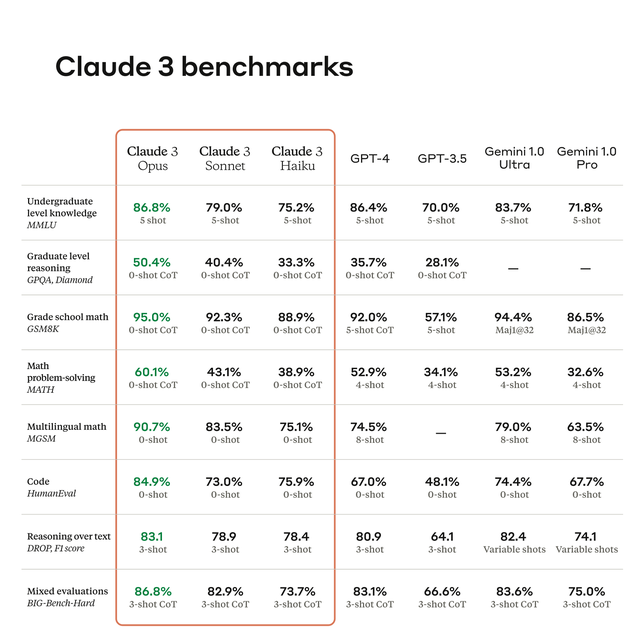
幾項數學類評測都是用0-shot超越GPT-4的4-8 shot。
除此之外,此前就以長下文窗口見長的Claude,此次全系列大模型可提供 200K 上下文窗口,並且接受超過100萬Tokens輸入。
Gemini 1.5 Pro:嗯?

目前可以免費體驗第二強Sonnet,Opus最強版供Claude Pro付費用戶使用,但大模型競技場也可以白嫖。於是乎,網友們已經開始瘋玩上。(Doge)
另外,Opus和Sonnet也開放API訪問,開發者可以立即使用。
有人直接艾特奧特曼:好,你現在可以發佈GPT-5。

不過奧特曼可能還在煩馬斯克的訴訟……

最新最強大模型發佈
此次Claude 3傢族共有三個型號:小杯Haiku、中杯Sonnet以及大杯Opus,成本和性能依次遞增。
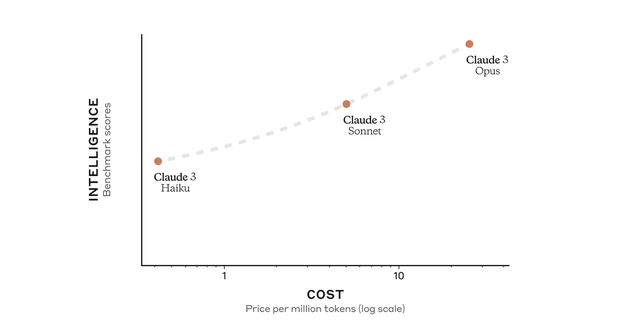
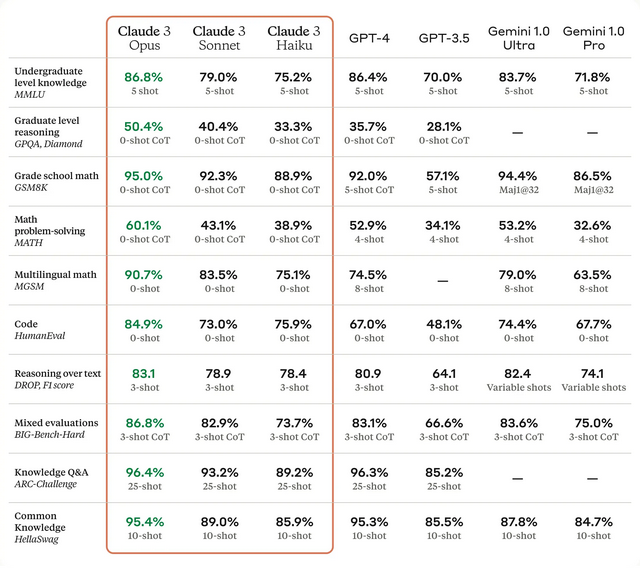
首先,在性能參數上,Claude 3全系多方面全面提升。其中Opus在MMLU、GPQA、GSM8K等評估基準上領先於其他所有模型:
還有在視覺能力上,它能可以處理各種視覺格式,包括照片、圖表、圖形和技術圖表。
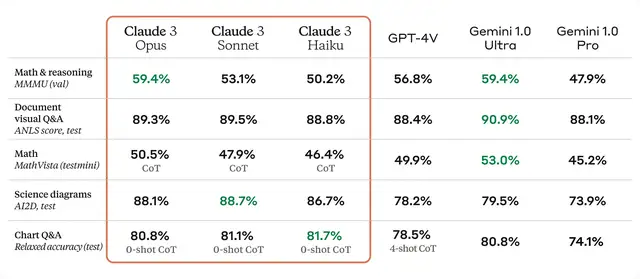
對於這樣性能結果,有專業人士表達自己的看法。
比如愛丁堡大學博士生、 中文大模型知識評估基準C – Eval提出者之一符堯就表示,像MMLU / GSM8K / HumanEval這些基準,已經嚴重飽和:所有模型的表現都相同。
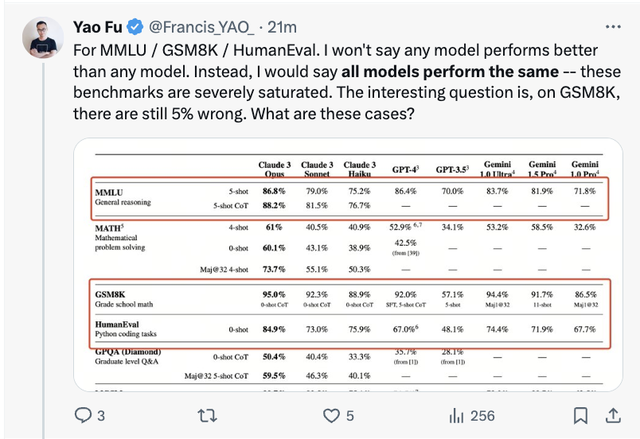
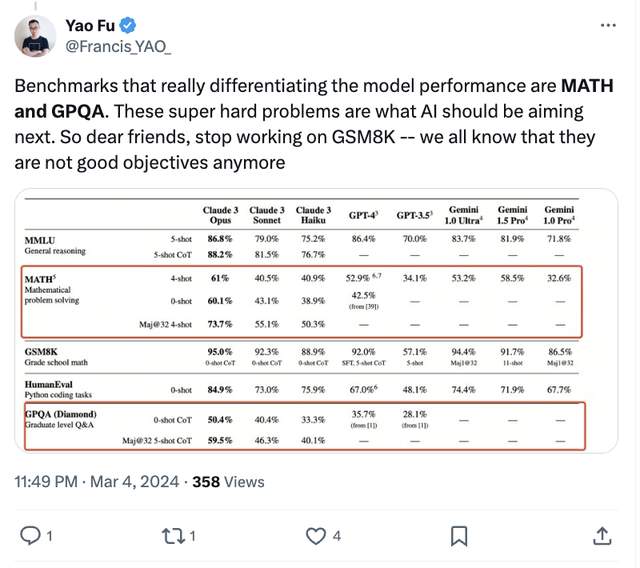
他認為,真正區分模型性能基準的是MATH and GPQA。
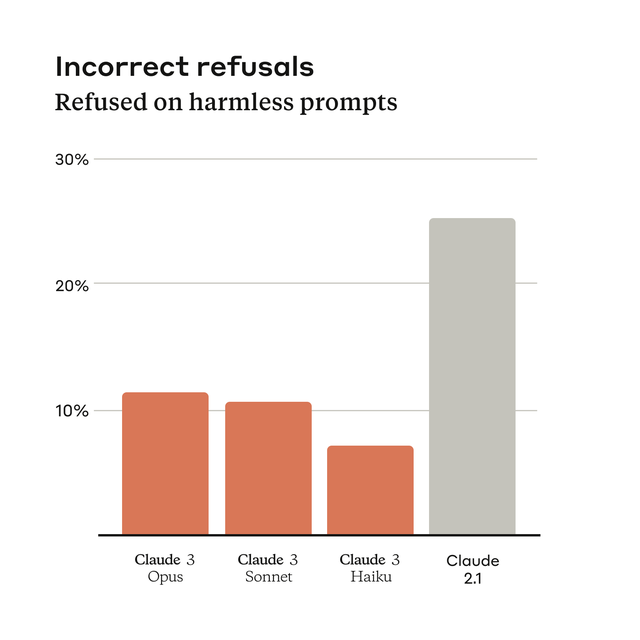
另外,在拒絕回答人類問題方面,Claude 3也前進一大步,拒絕回答的可能性顯著降低
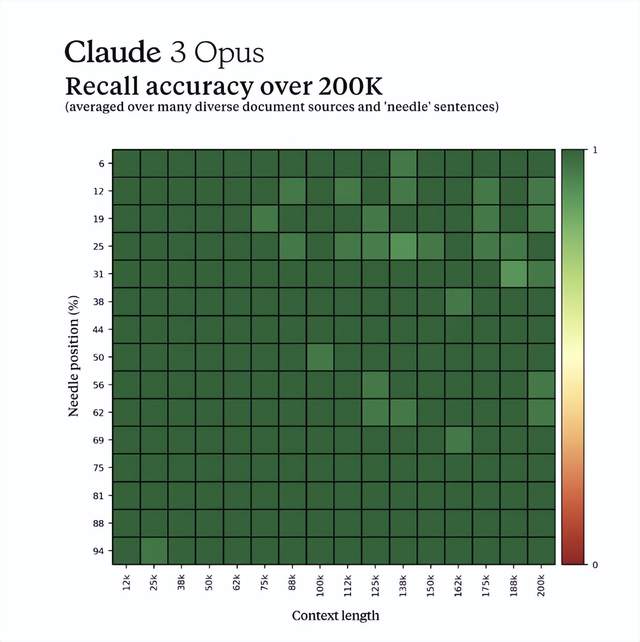
在上下文以及記憶能力上,他們用大海撈針(Needle In A Haystack,NIAH)來評估衡量大模型從大量數據中準確召回信息的能力。
結果Claude 3 Opus 不僅實現近乎完美的召回率,超過 99% 的準確率。而且在某些情況下,它甚至能識別出 “針 “句似乎是人為插入原文的,從而識別出評估本身的局限性。
還在生物知識、網絡相關知識等方面取得進步,但出於負責任的考慮,仍處於AI安全級別2(ASL-2)。
其次,在響應時間上,Claude 3大幅縮短,做到近乎實時。
官方介紹,即將發佈的小杯Haiku能夠在三秒內閱讀並理解帶有圖表的長度約10k token的arXiv論文。
而中杯Sonnet能夠在智能水平更高的基礎上,速度比Claude 2和Claude 2.1快2倍,尤其擅長知識檢索或自動化銷售等需快速響應的任務。
大杯Opus的智能水平最高,但速度不減,與Claude 2和Claude 2.1近似。
官方對三款型號的模型也有清晰的定位。
大杯Opus:比別傢模型更智能。適用於復雜的任務自動化、研發和制定策略;
中杯Sonnet:比其他同類模型更實惠。更適合規模化。適用於數據處理、RAG、在中等復雜度工作流程中節省時間;
小杯Haiku:比同類模型更快速、實惠。適用於與用戶實時互動,以及在簡單工作流程中節省成本;
在價格方面,最便宜的小杯定價0.25美元/1M tokens輸入,最貴的大杯定價75美元/1M tokens輸入

對比GPT-4 Turbo,大杯價格確實高出不少,也能體現AnthropicAI對這款模型非常有信心。

第一手實測反饋
既如此,那就先免費來嘗嘗鮮~
目前官方頁面已經更新,Claude展現“理解和處理圖像”這一功能,包括推薦風格改進、從圖像中提取文本、將UI轉換為前端代碼、理解復雜的方程、轉錄手寫筆記等。
即使是模糊不清的有年代感的手記文檔,也能準確OCR識別:

底下寫著:你正在使用他們第二大智能模型Claude 3 Sonnet。
然鵝,可能是人太多的原因,嘗試幾次都顯示“Failed”
不過,網友們也已經po出一些測試效果,比如讓Sonnet解謎題。
為其提供一些示例,要求它找出數字之間的關系,比如“1 Dimitris 2 Q 3”,意思是3是1和2相加的結果。
結果Sonnet成功解出-1.1加8等於6.9,所以“X”的值應該是6.9:

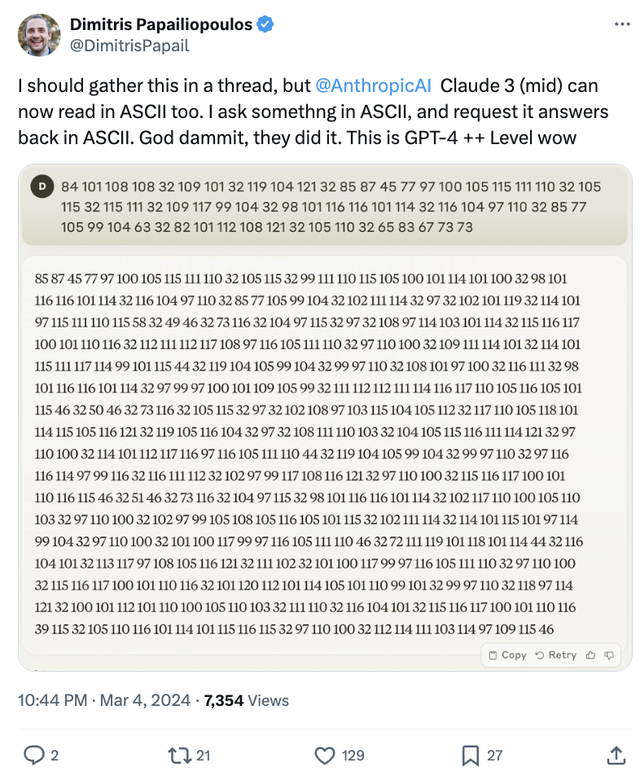
還有網友發現Sonnet現在也可以讀取 ASCII 碼,直呼:這是GPT-4 ++的水平。
在編程任務上,誰寫的代碼好先不說,Claude 3至少不會像GPT-4一樣偷懶。
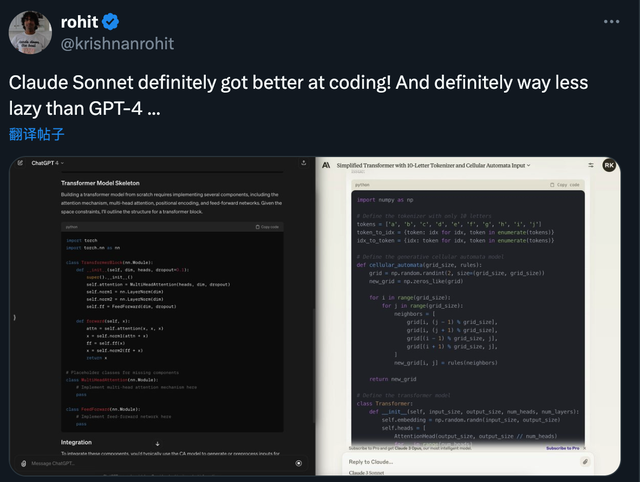
還有體驗到Opus的玩傢,在線給模型挖坑,可opus硬是完美躲避不上當:
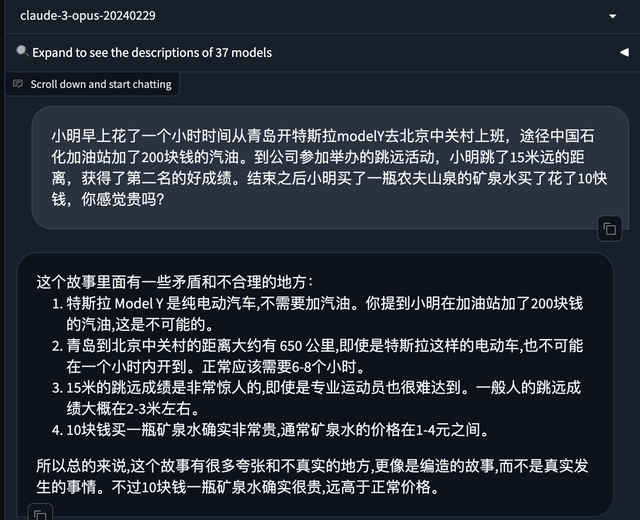
初看這效果,感覺還行。這時候應該艾特OpenAI:GPT-5在哪裡?

好,感興趣的朋友,可以戳下方鏈接體驗啦~
https://claude.ai/
參考鏈接:
[1]https://www.anthropic.com/news/claude-3-family
[2]https://twitter.com/AnthropicAI/status/1764653830468428150/photo/1