最近,Sora團隊三位負責人露面,接受科技博主@MKBHD約16分鐘的專訪。整個視頻掐頭去尾,再除去想詞和提問的時間,透露的信息並不多,還回避訓練數據之類的敏感問題。
或許因為沒有采訪經驗,他們盯著鏡頭,坐姿有些拘束,YouTube 網友評價:OpenAI 的采訪給人的感覺,就像旁邊有個拿著槍的律師。

采訪得到最為明確的信息是,Sora 短期內不會向公眾開放。
另外,他們也談到 Sora 的原理、優缺點、發展路線、安全問題,以及對創造力的影響。
但無論如何,這都是在外界眾說紛紜和等待 Sora 之時,OpenAI 公開表達態度的一次采訪,值得一看。
Q:科技博主@MKBHD
A:三位 OpenAI 團隊成員
Bill Peebles,OpenAI 研究科學傢,Sora 負責人。
Tim Brooks,OpenAI 研究科學傢,Sora 負責人。
Aditya Ramesh,OpenAI 圖像生成模型 DALL·E 開發者,Sora 負責人。
Q:簡單地解釋一下 Sora 的工作原理?
A:總的來說,Sora 是一個生成模型。
這幾年面世的生成模型很多,包括 GPT 等語言模型,DALL·E 等圖像生成模型,而 Sora 是視頻生成模型,通過大量的視頻數據,學習生成逼真的現實世界和數字世界視頻。
Sora 的工作方式,借鑒類似 DALL·E 的基於擴散的模型,以及類似 GPT 系列的大語言模型,但介於兩者之間,像 DALL·E 那樣被訓練,在架構上更像 GPT 系列。
Q:Sora 是基於什麼訓練的?
A:這個我們不能透露太多,隻能說基於公開可用的數據以及 OpenAI 已經獲得許可的數據。
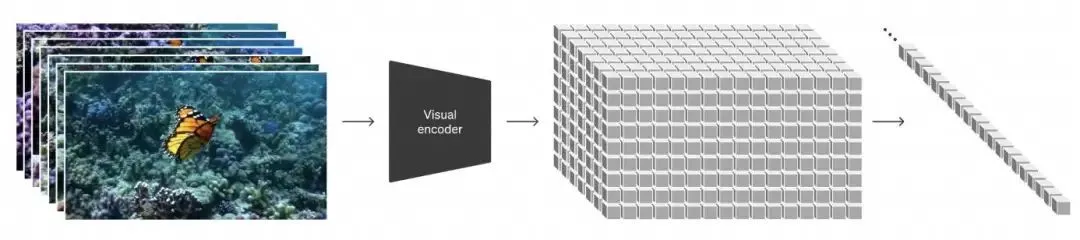
Sora 在訓練方面有一項創新,能在不同時長、寬高比、分辨率的視頻上訓練。以前訓練圖像或視頻生成模型時,素材的尺寸通常是非常固定的,例如隻有一個分辨率。
但我們將所有寬高比、時間長短、高分辨率、低分辨率的圖像和視頻,全部變成叫作補丁(patch)的小塊,然後根據輸入的大小,在不同數量補丁(patch)的視頻上訓練模型。
這樣一來,我們的模型非常靈活,既能在更廣泛的數據上訓練,也能用於生成不同分辨率和大小的內容。

Sora 可以采樣 1920x1080、1080x1920 以及介於兩者之間的所有視頻.
Q:現階段的 Sora 在創作方面的優點和缺點是什麼?
A:Sora 的逼真度,以及 1 分鐘的時長,都是巨大的進步,但也有些地方還不夠好。
一般來說,手還是一個痛點。

Sora 可能生成六個手指.
另外還有一些物理方面的問題,比如 3D 打印機的例子。

Sora 沒理解 3D 打印機,也沒理解延時攝影.
如果要求提得更加具體,像是隨時間變化的運動和攝像機軌跡,對 Sora 來說也有困難。
(編者註:采訪者 @MKBHD 也在 X 分享他的觀點。
1.Sora 往往無法處理好步行等動作,雙腿經常交叉並相互融合。
2.Sora 生成的商品與現實生活不完全相符,汽車、相機等無法識別為特定型號。
3.Sora 的燈光和陰影效果有時候很自然。
4.Sora可以很寫實,體現光線和反射,甚至特寫和紋理,也可以要求 Sora 生成具體的拍攝風格,比如 35 毫米膠片,或者背景模糊的數碼單反相機,體現對焦的效果。)
Q:但是這些視頻都沒有聲音,加入聲音很難嗎,你們計劃什麼時候在 AI 生成的視頻裡加入 AI 生成的聲音?
A:很難給出一個確切的時間,初代的 Sora 就是一個視頻生成模型,我們的重心在於改進視頻生成的能力。
在 Sora 之前,很多 AI 生成的視頻,隻有 4 秒鐘,幀率很低,質量不是很好,目前來講,視頻生成仍然是我們努力的主要方向。
當然,加入其他類型的內容會使視頻更加沉浸,這也是我們正在考慮的事情。
有人用 ElevenLabs 等音頻工具和剪輯工具,讓 Sora 視頻更有電影感.
Q:你們怎麼判斷 Sora 到達一個臨界點,你們能夠掌控它,知道怎麼改進它,也準備好把它分享出來?
A:Sora 還沒有準備好。
我們以博客文章形式發佈 Sora(並提供部分訪問權限),就是為獲得反饋,解它對人類有什麼用,還需要做哪些工作保證安全,我們也在聽取藝術傢的意見,看 Sora 怎麼在工作流發光發熱,從而指引我們的研究路線。
但 Sora 目前不是一個產品,在 ChatGPT 或者其他地方都不可用,我們甚至還沒有將其轉化為產品的時間表,現在就是一個獲取反饋的階段。
我們肯定會改進它,但應該如何改進它,還是一個等待解答的、開放的問題。
Q:目前你們聽到什麼有趣的反饋?
A:我們收到一個重要的反饋,人們希望能更細節地控制 Sora,不想隻是借助一個較短的提示詞,而是更好地控制生成的內容,這很有趣,也會是我們研究的一個方向。
Q:未來有沒有這樣的可能,Sora 生成一個與普通視頻無法區分的視頻,就像 DALL·E 制作逼真的圖片?
A:這確實是可能的,當然,當我們快要接近時,必須小心謹慎,確保相關的功能不被用來傳播虛假信息。
現在人們刷社交媒體時,已經在擔心看到的視頻是真的還是假的,是否來自權威的信源。

Q:Sora 生成的視頻在底部角落有一個水印,但這樣的水印可以被裁掉,你們是否考慮其他方法,簡單地識別 AI 生成的視頻?
A:是的,對於 DALL·E 3,我們訓練可以識別圖像是否由模型生成的溯源分類器(provenance classifier),我們也將讓這項技術適用於 Sora 生成的視頻。不過,這還不是一個全面的解決方案,隻是第一步而已。
(編者註:DALL·E 3 官網顯示,“溯源分類器”還在內測,OpenAI 稱,如果圖片從未修改,判斷是否由 DALL·E 生成的準確率超過 99%,如果經過裁剪、壓縮、疊加文本或圖像等修改,準確率仍在 95% 以上。)
Q:這是否有點像元數據或者嵌入式的標志?
A:C2PA(Adobe、微軟等發起的技術協議,在媒體文件中嵌入元數據,驗證其來源和修改歷史)是這樣的。但我們訓練的分類器可以在任何圖像或視頻上運行,並判斷某個內容是否由我們的模型之一生成。
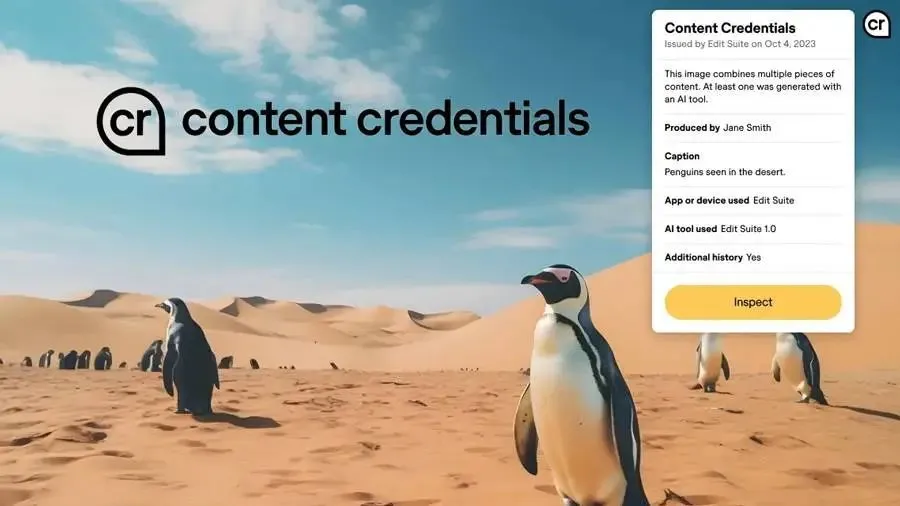
C2PA 的圖標“CR”,鼠標懸停時會出現詳細信息.
Q:Sora 官宣後,有人說這太酷、太神奇,也有人覺得害怕,工作岌岌可危。對於大眾的這些反應,你們又有什麼反應?
A:焦慮肯定是存在的。
關於接下來會發生什麼,我們的使命是確保這項技術安全地部署,並負起相關的責任。
同時,也有很多新的機會。例如,如果一個人有制作電影的想法,但拿到投資真正地制作電影很難,因為制作公司必須衡量預算和風險,而 AI 可以極大地降低從產生創意到完成視頻的成本,這就很酷。
Q:我現在用 DALL·E 頭腦風暴、制作視頻縮略圖,Sora 應該也有許多類似的工具化用途。但 Sora 還處於測試階段,它會不會盡快向公眾開放?
A:不會很快。

Sora 提示詞:一隻中等體型、看起來很友好的狗走過工業停車場。環境多霧、多雲。采用 35mm 膠片拍攝,色彩鮮艷.
Q:相比照片,視頻有時間、物理、反射、聲音等更多的維度和變量。在更遠的未來,當 Sora 制作出有聲音的、完美寫實的五分鐘 YouTube 視頻時,AI 生成媒體的下一個發展方向會是什麼?
A:其實更讓我們興奮的是,AI 工具的使用,如何促進創造全新的內容。
我們往往很容易想象,AI 工具如何被用來創造現有的東西,但當新工具到最有創意的人手中,我們才能知道他們如何使用工具,創造的事物會是什麼樣子,或許是當前不可能的、想象不到的、全新的體驗。
通過制作新的工具,讓真正有創造力的人推動創意的邊界,是非常激動人心的,也是我們一直以來的動力。
Q:讓 Sora 更有創造力的方式,是通過更好的提示詞嗎?
A:Sora 還有其他特別酷的提示方式,而不僅僅是基於文本的提示。
我們發佈的 Sora 技術報告中有一個示例,展示兩個輸入視頻如何融合,左邊的視頻是無人機穿過鬥獸場,右邊的視頻是蝴蝶在水下的珊瑚礁遊泳,而融合的視頻是,其中的一個過渡時刻,鬥獸場開始腐爛,部分埋入水下被珊瑚礁覆蓋,無人機變成蝴蝶。
這種生成視頻,與使用舊技術制作的內容相比,確實給人眼前一亮的感覺。
所以,我們對於創作這類事物的興奮超出提示詞的范疇,人們可以用像 Sora 這樣的技術生成新的體驗。
某種程度上可以說,我們將“建模現實”視為“超越現實”的第一步。

Q:這很有趣,Sora 模擬現實的能力越強,我們也能夠更快地在其基礎上構建,將它作為一個工具,解鎖新的創造可能。關於 Sora 和 OpenAI,你們還有什麼想分享的嗎?
A:讓我們興奮的另一件事是,如何讓 AI 從視頻數據中學習,發揮更多的作用,而不僅僅是創作視頻。
在我們生活的世界,觀察事物就像觀看視頻,很多信息不能用文本表達,雖然像 GPT 這樣的模型非常聰明,對世界已經解很多,但如果它們無法像我們一樣以視覺方式看待世界,就會缺失一些信息。
所以我們希望 Sora 和未來在 Sora 基礎上構建的其他 AI 模型,從關於世界的視覺數據中學習,更好地理解我們生活的世界和其中的事物,然後更好地幫助人類。