傳聞中OpenAI的Q*已經引得AI大佬輪番下場。AI2研究科學傢NathanLambert和英偉達高級科學傢JimFan都激動的寫下長文,猜測Q*和思維樹、過程獎勵模型、AlphaGo有關。人類離AGI,已是臨門一腳?

OpenAI的神秘Q*項目,已經引爆整個AI社區!
疑似接近AGI,因為巨大計算資源能解決某些數學問題,讓Sam Altman出局董事會的導火索,有毀滅人類風險……這些元素單拎出哪一個來,都足夠炸裂。
無怪乎Q*項目曝出三天後,熱度還在持續上升,已經引起全網AI大佬的探討。
AI2研究科學傢Nathan激動地寫出一篇長文,猜測Q假說應該是關於思想樹+過程獎勵模型。
而且,Q*假說很可能和世界模型有關!

幾小時後,英偉達高級科學傢Jim Fan也發出長文分析,跟Nathan的看法不謀而合,略有不同的是,Jim Fan的著重點是和AlphaGo的類比。
對於Q*,Jim Fan發出如此贊嘆:在我投身人工智能領域的十年中,我從來見過有這麼多人對一個算法有如此多的想象!即使它隻有一個名字,沒有任何論文、數據或產品。
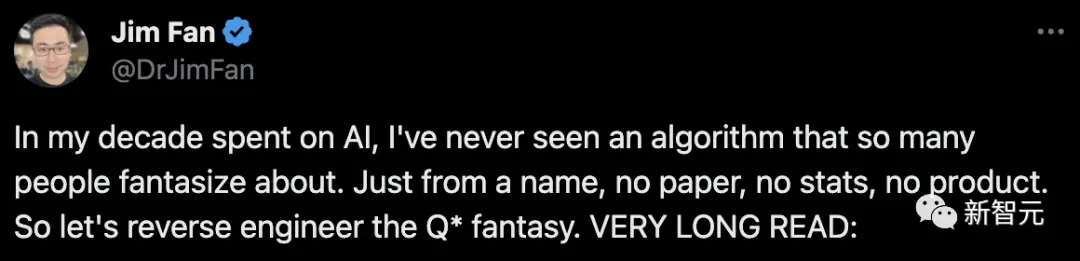
相比之下,圖靈三巨頭LeCun則認為,提升大LLM可靠性的一個主要挑戰是,利用規劃策略取代自回歸token預測。
幾乎所有頂級實驗室都在這方面進行研究,而Q*則很可能是OpenAI在規劃領域的嘗試。
以及,請忽略那些關於Q*的毫無根據的討論。
對此,Jim Fan深表贊同:擔心“通過Q*實現AGI”是毫無根據的。
“AlphaGo式搜索和LLM的結合,是解決數學和編碼等特定領域的有效方法,同時還能提供基準真相的信號。但在正式探討AGI之前,我們首先需要開發新的方法,將世界模型和具身智能體的能力整合進去。”

Q-Learning忽然大火
兩天前,外媒曝出,OpenAI的神秘Q*項目,已現AGI雛形。

突然間,一項來自1992年的技術——Q-learning,就成為大傢競相追逐的焦點。
簡單來說,Q-learning是一種無模型的強化學習算法,旨在學習特定狀態下某個動作的價值。其最終目標是找到最佳策略,即在每個狀態下采取最佳動作,以最大化隨時間累積的獎勵。
在人工智能領域,尤其是在強化學習中,Q-learning代表一種重要的方法論。

很快,這個話題引發各路網友的激烈討論:
斯坦福博士Silas Alberti猜測,它很可能是基於AlphaGo式蒙特卡羅樹搜索token軌跡。下一個合乎邏輯的步驟是以更有原則的方式搜索token樹。這在編碼和數學等環境中尤為合理。

隨後,更多人猜測,Q*指的就是A*算法和Q學習的結合!

甚至有人發現,Q-Learning竟然和ChatGPT成功秘訣之一的RLHF,有著千絲萬縷的聯系!

隨著幾位AI大佬的下場,大傢的觀點,愈發不謀而合。
AI大佬千字長文分析
對於引得眾人好奇無比的Q*假說,AI2研究科學傢Nathan Lambert寫如下一篇長文分析——《Q* 假說:思維樹推理、過程獎勵模型和增強合成數據》。

文章地址:https://www.interconnects.ai/p/q-star
Lambert猜測,如果Q*(Q-Star)是真的,那麼它顯然是RL文獻中的兩個核心主題的合成:Q值和A*(一種經典的圖搜索算法)。
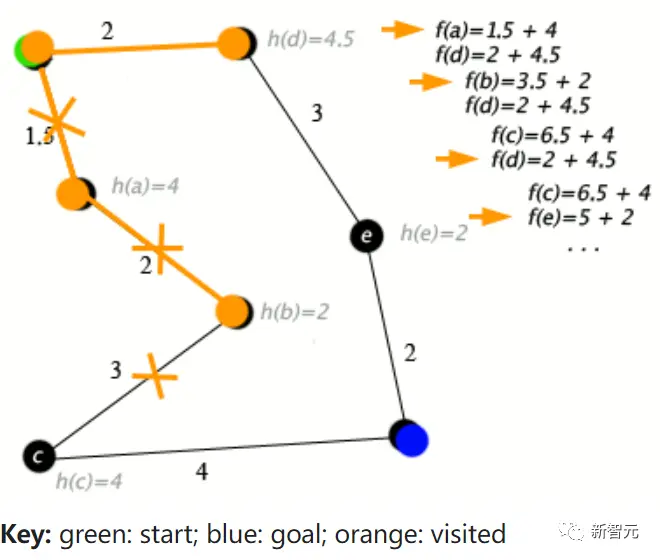
A*算法的一個例子
很多天來,坊間關於Q冒出很多猜測,有一種觀點認為,Q指的是最優策略的值函數,不過在Lambert看來這不太可能,因為OpenAI已經幾乎泄露所有內容。
Lambert將自己的猜測稱為“錫帽理論”,即Q學習和A*搜索的模糊合並。
所以,正在搜索的是什麼?Lambert相信,OpenAI應該是在通過思想樹推理來搜索語言/推理步驟,來做一些強大的事情。
如果僅是如此,為何會引起如此大的震動和恐慌呢?
他覺得Q*被誇大的原因是,它將大語言模型的訓練和使用與Deep RL的核心組件聯系起來,而這些組件,成功實現AlphaGo的功能——自我博弈和前瞻性規劃。
其中,自我博弈(Self-play)理論是指,智能體可以和跟自己版本略有不同的另一個智能體對戰,來改善遊戲玩法,因為它遇到的情況會越來越有挑戰性。
在LLM領域,自我博弈理論看起來就像是AI反饋。
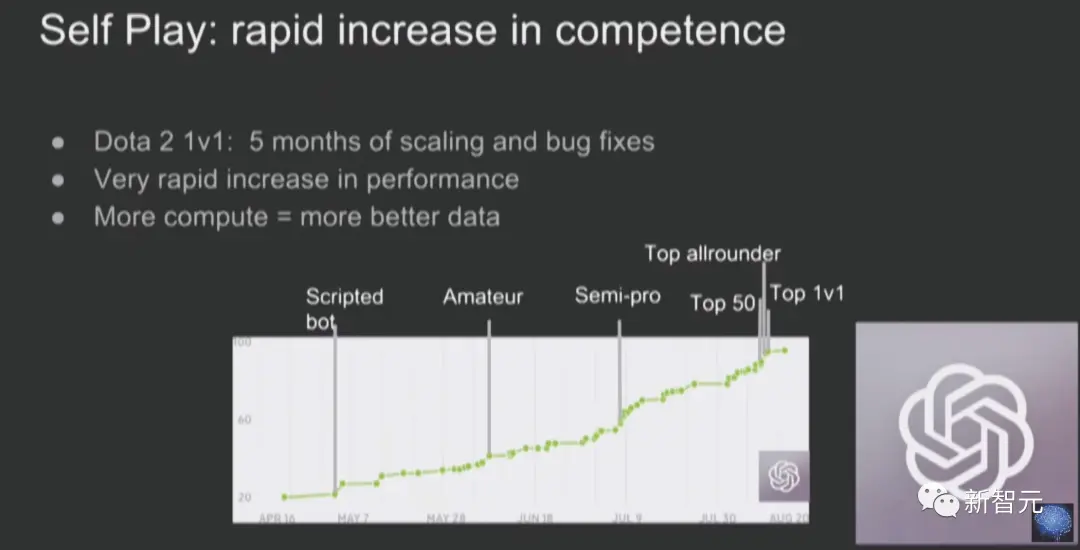
前瞻性規劃(Look-ahead planning),是指使用世界模型來推理未來,並產生更好的行動或輸出。
這種理論基於模型預測控制(MPC)和蒙特卡洛樹搜索(MCTS),前者通常用於連續狀態,後者適用於離散動作和狀態。
https://www.researchgate.net/publication/320003615_MCTSUCT_in_solving_real-life_problems
Lambert之所以做出這種推測,是基於OpenAI和其他公司最近發佈的工作。這些工作,回答這樣兩個問題——
1. 我們如何構建一個我們自己可以搜索的語言表示?
2. 在分隔和有意義的語言塊(而不是整個語言塊)上,我們怎樣才能構建一個價值概念?
如果想明白這兩個問題,我們就該清楚,應該如何使用用於RLHF的RL方法——我們用RL優化器來微調語言模型,並且通過模塊化獎勵,獲得更高質量的生成(而不是像今天那樣,完整的序列)。

使用LLM進行模塊化推理:思維樹(ToT)提示
現在,讓模型“深呼吸”和“一步步思考”之類的方法,正在擴展到利用並行計算和啟發式進行推理的高級方法上。
思維樹是一種提示語言模型創建推理路徑樹的方法,這些路徑可能會、也可能不會收斂到正確答案。
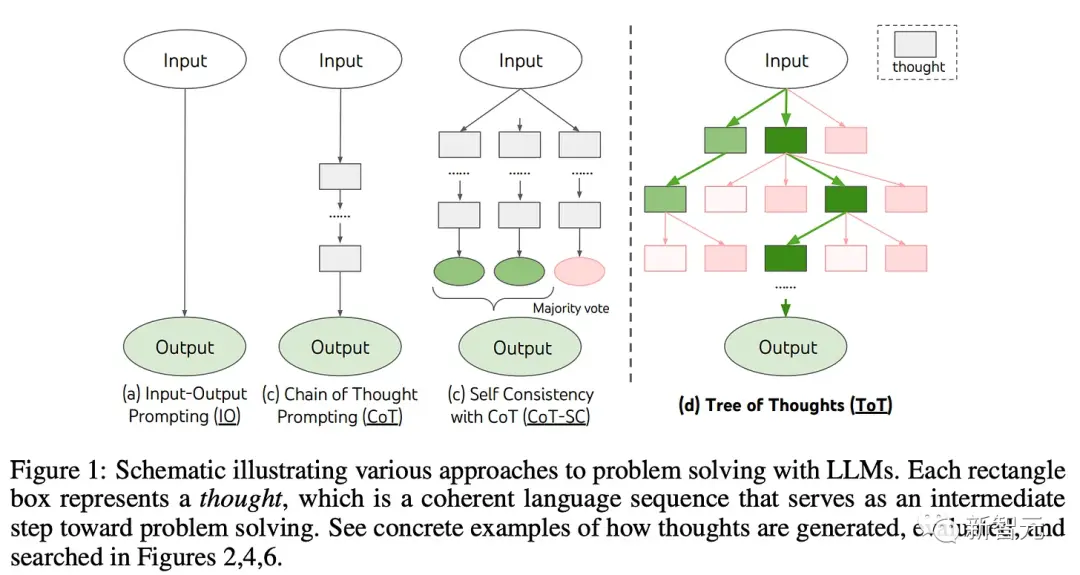
實現思維樹的關鍵創新,就是推理步驟的分塊,以及提示模型創建新的推理步驟。
思維樹或許是第一個提高推理性能的“遞歸”提示技術,聽起來非常接近人工智能安全所關註的遞歸自我改進模型。

https://arxiv.org/abs/2305.10601
使用推理樹,就可以應用不同的方法來對每個頂點或節點進行評分,或者對最終路徑進行采樣。
它可以基於最一致答案的最小長度,或者需要外部反饋的復雜事物,而這恰恰就把我們帶到RLHF的方向。
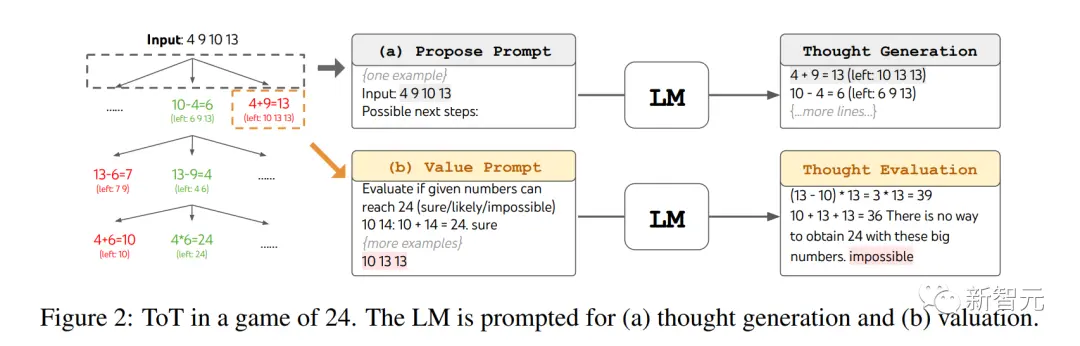
用思維樹玩24點遊戲
生成中的細粒度獎勵標簽:過程獎勵模型(PRM)
迄今為止,大多數RLHF,都是通過給模型的整個響應打分而完成的。
但對於具有RL背景的人,這種方法很令人失望,因為它限制RL方法對文本的每個子組件的值建立聯系的能力。
有人指出,在未來,這種多步驟優化將在多個對話回合的層面上進行,但由於需要有人類或一些提示源參與循環,整個過程仍然很牽強。
這可以很容易地擴展到自我博弈風格的對話上,但很難給出LLM一個目標,讓它轉化為持續改進的自我博弈動態。
畢竟,我們想用LLM做的大多數事情還是重復性任務,並不是像圍棋那樣,需要達到近乎無限的性能上限。

不過,有一種LLM用例,可以自然地抽象為包含的文本塊,那就是分步推理。而最好的例子,就是解決數學問題。
過去6個月內,過程獎勵模型(PRM)一直是RLHF人員熱烈探討的話題。
關於PRM的論文很多,但很少有論文會提到,如何將它們與RL結合使用。
PRM的核心思想,就是為每個推理步驟分配一個分數,而不是一個完整的信息。
OpenAI的論文“Let's Verify Step by Step”中,就有這樣一個例子——

在這個過程中,他們使用的反饋界面長這個樣子,非常有啟發性。

這樣,就可以通過對最大平均獎勵或其他指標進行采樣,而不是僅僅依靠一個分數,對推理問題的生成進行更精細的調整。
使用“N最優采樣”(Best-of-N sampling),即生成一系列次數,並使用獎勵模型得分最高的一次,PRM在推理任務中的表現,要優於標準RM。
(註意,它正是Llama 2中“拒絕采樣”Rejection Sampling的表兄弟。)
而且迄今為止,大多數PRM僅展示自己在推理時的巨大作用。但如果把它用於訓練進行優化,就會發揮真正的威力。
而為創建最豐富的優化設置,就需要能夠生成用於評分和學習的多種推理路徑。
這,就是思維樹的用武之地。
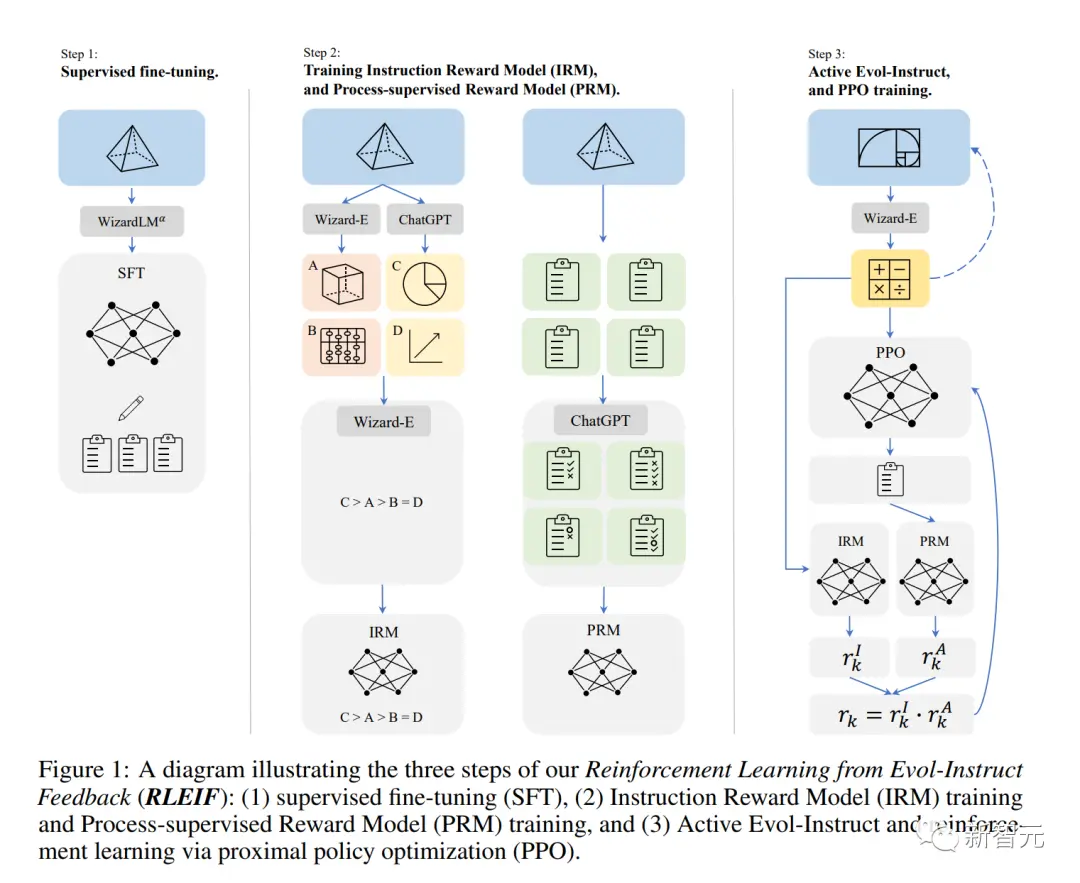
人氣極高的數學模型Wizard-LM-Math,就是使用PRM進行訓練的:https://arxiv.org/abs/2308.09583
所以,Q*可能是什麼?
Nathan Lambert猜測,Q*似乎正在使用PRM,對ToT推理數據進行評分,然後再使用Offline RL進行優化。
這與現有的RLHF工具沒有太大區別,它們用的是DPO或ILQL等離線算法,這些算法在訓練期間不需要從LLM生成。
RL算法看到的“軌跡”,就是推理步驟的序列,因此,我們得以用多步方式,而不是通過上下文,來執行RLHF。
現有的傳言顯示,OpenAI正在將離線RL用於RLHF,這似乎不是一個很重大的飛躍。
它的復雜性在於要收集正確的提示,讓模型生成出色的推理,而最重要的,就是準確地給數以萬計的響應評分。
而傳聞中的龐大計算資源,就是使用AI而非人類,來給每一步打分。
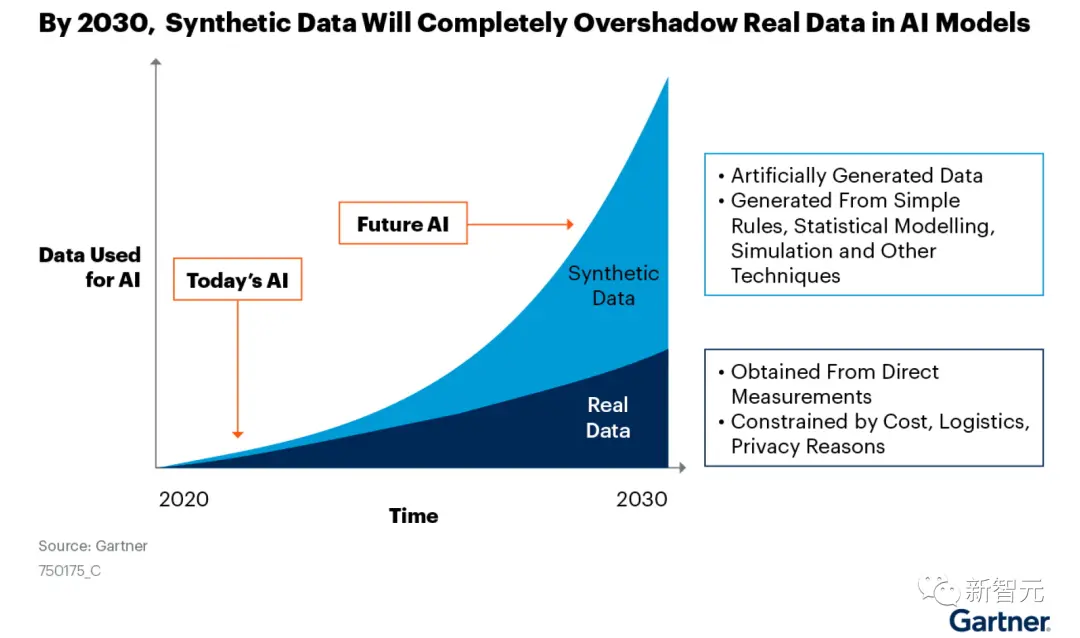
的確,合成數據才是王道,使用樹而非單一寬度路徑(思維鏈),就可以為以後越來越多的選擇,給出正確答案。
如果傳言是真的,OpenAI和其他模型的差距,無疑會很可怕。
畢竟,現在大多數科技公司,比如Google、Anthropic、Cohere等,創建預訓練數據集用的還是過程監督或類似RLAIF的方法,輕易就會耗費數千個GPU小時。
超大規模AI反饋的數據未來
根據外媒The Information的傳言,Ilya Sutskever的突破使OpenAI解決數據荒難題,這樣就有足夠的高質量數據來訓練下一代新模型。
而這些數據,就是用計算機生成的數據,而非真實世界的數據。
另外,Ilya多年研究的問題,就是如何讓GPT-4等語言模型解決涉及推理的任務,如數學或科學問題。

Nathan Lambert表示,如果自己猜得沒錯,Q*就是生成的合成推理數據。
通過類似剔除抽樣(根據RM分數進行篩選)的方法,可以選出最優秀的樣本。而通過離線RL,生成的推理可以在模型中得到改進。
對於那些擁有優質大模型和大量算力資源的機構來說,這是一個良性循環。
結合GPT-4給大傢的印象,數學、代碼、推理,都應該是最從Q*技術受益的主題。
什麼是最有價值的推理token?
許多AI研究者心中永恒的問題是:究竟哪些應用值得在推理計算上花費更多成本?
畢竟,對於大多數任務(如閱讀文章、總結郵件)來說,Q*帶來的提升可能不值一提。
但對於生成代碼而言,使用最佳模型,顯然是值得的。
Lambert表示,自己腦子中有一種根深蒂固的直覺,來自於和周圍人餐桌上的討論——使用RLHF對擴展推理進行訓練,可以提高下遊性能,而無需讓模型一步一步思考。
如果Q*中實現這一點,OpenAI的模型,無疑會顯示出重大的飛躍。
Jim Fan:Q*可能的四大核心要素
Nathan在我之前幾個小時發佈一篇博客,並討論非常相似的想法:思想樹+過程獎勵模型。他的博客列出更多的參考文獻,而我更傾向於與AlphaGo的類比。
Jim Fan表示,要理解搜索和學習結合的強大威力,我們需要先回到2016年,這個人工智能歷史上的輝煌時刻。
在重新審視AlphaGo時,可以看到它包含四個關鍵要素:
1. 策略神經網絡(Policy NN,學習部分):評估每種走法獲勝的可能性,並挑選好的走法。
2. 價值神經網絡(Value NN,學習部分):用於評估棋局,從任意合理的佈局中預測勝負。
3. 蒙特卡羅樹搜索(MCTS,搜索部分):利用策略神經網絡模擬從當前位置出發的多種可能的走法,然後匯總這些模擬的結果來決定最有希望的走法。這是一個“慢思考”環節,與大語言模型(LLM)中的快速token采樣形成鮮明對比。
4. 推動整個系統的真實信號:在圍棋中,這個信號就像“誰獲勝”這種二元標簽一樣簡單,由一套固定的遊戲規則所決定。你可以把它想象成一種能量源,持續地推動著學習的進程。
那麼,這些組件是如何相互作用的呢?
AlphaGo通過自我博弈(即與自己之前的版本對弈)來學習。
隨著自我博弈的持續,策略神經網絡和價值神經網絡都在不斷迭代中得到改善:隨著策略在選擇走法上變得更精準,價值神經網絡也能獲得更高質量的數據進行學習,進而為策略提供更有效的反饋。更強大的策略也有助於MCTS探索出更佳的策略。
這些最終構成一個巧妙的“永動機”。通過這種方式,AlphaGo能自我提升,最終在2016年以4-1的成績擊敗人類世界冠軍李世石。僅僅通過模仿人類的數據,人工智能是無法達到超越人類的水平的。
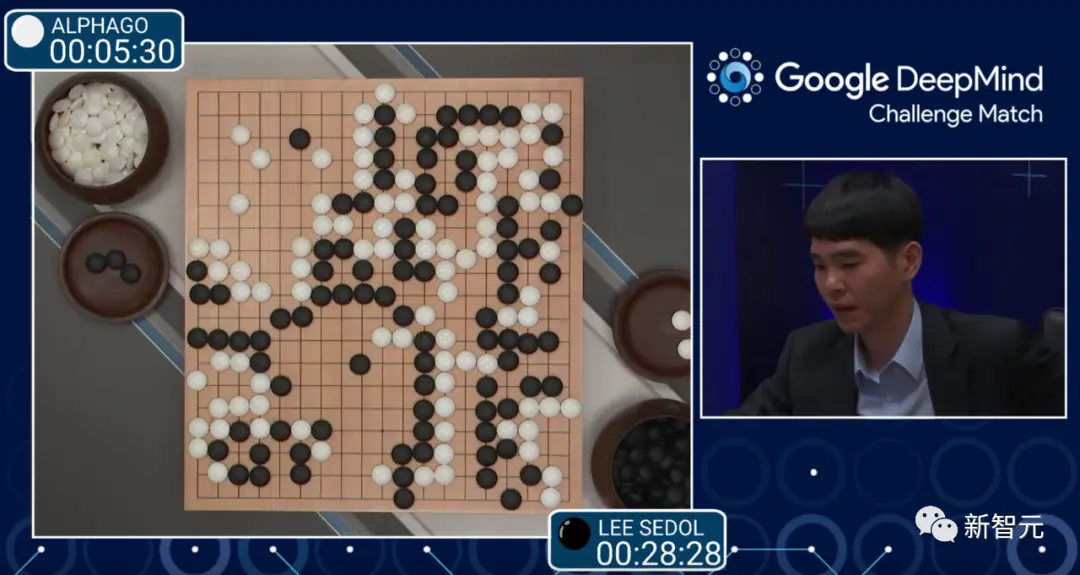
對於Q*來說,又會包含哪四個核心組件呢?
1. 策略神經網絡(Policy NN):這將是OpenAI內部最強大的GPT,負責實現解決數學問題的思維過程。
2. 價值神經網絡(Value NN):這是另一個GPT,用來評估每一個中間推理步驟的正確性。
OpenAI在2023年5月發佈一篇名為“Let's Verify Step by Step”的論文,作者包括Ilya Sutskever、John Schulman和Jan Leike等知名大佬。雖然它不像DALL-E或Whisper那樣知名,但卻為我們提供不少線索。
在論文中,作者提出“過程監督獎勵模型”(Process-supervised Reward Models,PRM),它為思維鏈中的每一步提供反饋。相對的是“結果監督獎勵模型”(Outcome-supervised Reward Models,ORM),它隻對最終的整體輸出進行評估。
ORM是RLHF的原始獎勵模型,但它的粒度太粗,不適合對長響應中的各個部分進行適當的評估。換句話說,ORM在功勞分配方面表現不佳。在強化學習文獻中,我們將ORM稱為“稀疏獎勵”(僅在最後給予一次),而PRM則是“密集獎勵”,能夠更平滑地引導LLM朝我們期望的行為發展。
3. 搜索:不同於AlphaGo的離散狀態和動作,LLM運行在一個復雜得多的空間中(所有合理字符串)。因此,我們需要開發新的搜索方法。
在思維鏈(CoT)的基礎上,研究界已經開發出一些非線性變體:
- 思維樹(Tree of Thought):就是將思維鏈和樹搜索結合在一起
- 思維圖(Graph of Thought):將思維鏈和圖結合,就可以得到一個更為復雜的搜索運算符
4. 真實信號:(幾種可能)
(a)每個數學問題都有一個已知答案,OpenAI可能已經從現有的數學考試或競賽中收集大量的數據。
(b)ORM本身可以作為一種真實信號,但這樣可能會被利用,從而“失去維持學習所需的能量”。
(c)形式化驗證系統,如Lean定理證明器,可以把數學問題轉化為編程問題,並提供編譯器反饋。
就像AlphaGo那樣,策略LLM和價值LLM可以通過迭代相互促進進步,並在可能的情況下從人類專傢的標註中學習。更優秀的策略LLM將幫助思維樹搜索發現更好的策略,這反過來又能為下一輪迭代收集更優質的數據。
Demis Hassabis之前提到過,DeepMind的Gemini將采用“AlphaGo式算法”來增強推理能力。即使Q*不是我們所想象的那樣,Google也一定會用自己的算法迎頭趕上。
Jim Fan表示,以上隻是關於推理的部分。目前並沒有跡象表明Q*在寫詩、講笑話或角色扮演方面會更具創造性。本質上,提高創造力是人的事情,因此自然數據仍將勝過合成數據。
是時候解決最後一章
而深度學習專傢Sebastian Raschka對此表示——
如果你出於任何原因,不得不在這個周末學習Q-learning,並且碰巧在你的書架上有一本“Machine Learning with PyTorch and Scikit-Learn”,那麼,現在是時候解決最後一章。

參考資料:
https://www.interconnects.ai/p/q-star
https://twitter.com/DrJimFan/status/1728100123862004105