在通往AGI的路上我們還有多遠?微軟豪華作者團隊發佈的154頁論文指出,GPT-4已經初具通用人工智能的雛形。GPT-4會演變為通用人工智能嗎?Meta首席人工智能科學傢、圖靈獎得主YannLeCun對此表示質疑。
在他看來,大模型對於數據和算力的需求實在太大,學習效率卻不高,因此學習‘世界模型’才能通往AGI之路。
不過,微軟最近發表的154頁論文,似乎就很打臉。
在這篇名為‘Sparks of Artificial General Intelligence: Early experiments with GPT-4’的論文中,微軟認為,雖然還不完整,但GPT-4已經可以被視為一個通用人工智能的早期版本。

論文地址:https://arxiv.org/pdf/2303.12712.pdf
鑒於 GPT-4 能力的廣度和深度,我們相信它應該被合理視作一個通用人工智能(AGI)系統的早期(但仍不完整)版本。
本文的主要目標是對 GPT-4 的能力和局限性進行探索,我們相信 GPT-4 的智能標志著計算機科學及其他領域的真正范式轉變。
AGI的智能體現在能夠像人類一樣思考和推理,並且還能夠涵蓋廣泛的認知技能和能力。
論文中,指出AGI具有推理、規劃、解決問題、抽象思維、理解復雜思想、快速學習和經驗學習能力。
從參數規模上來看,Semafor報道稱GPT-4有1萬億個參數,是GPT-3(1750個參數)的6倍大。
網友用GPT參數規模大腦神經元做類比:
GPT-3的規模與刺蝟大腦類似(1750億個參數)。如果GPT-4擁有1萬億個參數,我們就接近松鼠大腦的規模。以這個速度發展下去,也許隻需要幾年時間,我們就能達到並超越人類大腦的規模(170萬億個神經元)。
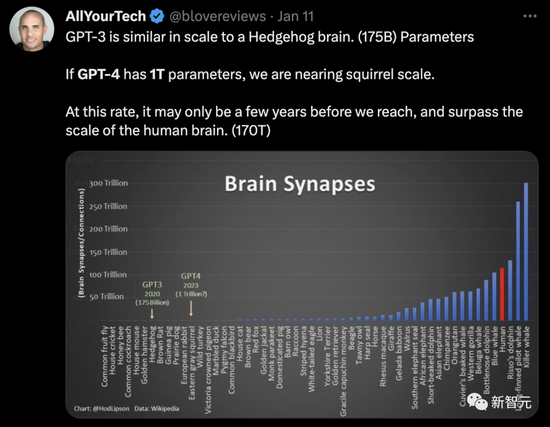
由此看來,GPT-4距離成為‘天網’也不遠。

而這篇論文,還被扒出不少趣事。
論文發佈不久後,一位網友在Twitter上爆出從他們的latex源代碼中發現隱藏信息。

在未刪減版的論文中,GPT-4實際上也是該論文的隱藏第三作者,內部名稱 DV-3,後被刪除。

有趣的是,就連微軟研究人員對GPT-4的技術細節並不清楚。另外,這篇論文還刪除GPT-4在沒有任何提示的情況下產生的有毒內容。
GPT-4初具AGI雛形
這篇論文的研究對象,是GPT-4的早期版本。它還處於早期開發階段時,微軟的研究者就對它進行各種實驗和測評。
在研究者看來,這個早期版本的GPT-4,就已經是新一代LLM的代表,並且相較於之前的人工智能模型,展現出更多的通用智能。
通過測試,微軟的研究者證實:GPT-4不僅精通語言,還能在數學、編程、視覺、醫學、法律、心理學等多樣化和高難度的任務中表現出色,且無需特別提示。

令人驚奇的是,在所有這些任務中,GPT-4 的表現已經接近人類水平,並且時常超過之前的模型,比如ChatGPT。
因此,研究者相信,鑒於GPT-4在廣度和深度上的能力,它可以被視為通用人工智能(AGI)的早期版本。
那麼,它朝著更深入、更全面的AGI前進的路上,還有哪些挑戰呢?研究者認為,或許需要尋求一種超越‘預測下一個詞’的新范式。
如下關於GPT-4能力的測評,便是微軟研究人員給出關於GPT-4是AGI早期版本的論據。
多模態和跨學科能力
自GPT-4發佈後,大傢對其多模態能力的印象還停留在Greg Brockman當時演示的視頻上。
這篇論文第二節中,微軟最先介紹它的多模態能力。
GPT-4不僅在文學、醫學、法律、數學、物理科學和程序設計等不同領域表現出高度熟練程度,而且它還能夠將多個領域的技能和概念統一起來,並能理解其復雜概念。
綜合能力
研究人員分別用以下4個示例來展示GPT-4在綜合能力方面的表現。
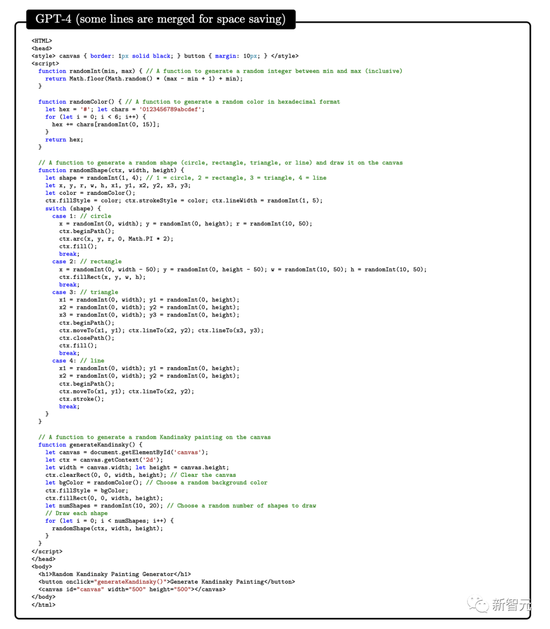
第一個示例中,為測試GPT-4將藝術和編程結合的能力,研究人員要求GPT-4生成 javascript代碼,以生成畫傢 Kandinsky風格的隨機圖像。

如下為GPT-4實現代碼過程:
在文學和數學結合上,GPT-4能夠以莎士比亞的文學風格證明質數是無窮多的。
此外,研究還測試GPT-4將歷史知識和物理知識結合起來的能力,通過要求其撰寫一封支持Electron競選美國總統的信,信是由聖雄甘地寫給他的妻子的。
通過提示GPT-4為一個程序生成python代碼,該程序將患者的年齡、性別、體重、身高和血液檢測結果向量作為輸入,並指出患者是否處於糖尿病風險增加的狀態。
通過測試,以上例子表明GPT-4不僅能夠學習不同領域和風格的一些通用原則和模式,還能以創造性的方式將其結合。
視覺
當提示GPT-4使用可伸縮矢量圖形(SVG)生成物體圖像,如貓、卡車或字母時,該模型生成的代碼通常會編譯成相當詳細,且可識別的圖像,如下圖:

然而,許多人可能會認為GPT-4隻是從訓練數據中復制代碼,其中包含類似的圖像。
其實GPT-4不僅是從訓練數據中的類似示例中復制代碼,而且能夠處理真正的視覺任務,盡管隻接受文本訓練。
如下,提示模型通過結合字母Y、O和H的形狀來繪制一個人。
在生成過程中,研究人員使用draw-line和draw-circle命令創建O、H和Y的字母,然後GPT-4設法將它們放置在一個看起是合理的人形圖像中。
盡管GPT-4並沒有經過關於字母形狀的認識的訓練,仍舊可以推斷出,字母Y可能看起來像一個手臂朝上的軀幹。
在第二次演示中,提示GPT-4糾正軀幹和手臂的比例,並將頭部放在中心位置。最後要求模型添加襯衫和褲子。
如此看來,GPT-4從相關訓練數據中、模糊地學習到字母與一些特定形狀有關,結果還是不錯的。

為進一步測試GPT-4生成和操作圖像的能力,我們測試它遵循詳細指令創建和編輯圖形的程度。這項任務不僅需要生成能力,還需要解釋性、組合性和空間性能力。
第一個指令是讓GPT-4生成2D圖像,prompt為:
‘A frog hops into a bank and asks the teller, ‘Do you have any free lily pads?’ The teller responds, ‘No, but we do o er low interest loans for pond upgrades’
通過多次嘗試,GPT-4每一次都生成符合描述的圖像。然後,要求GPT-4添加更多細節來提高圖形質量,GPT-4添加銀行、窗戶、汽車等符合現實邏輯的物體。
我們的第二個示例是嘗試使用Javascript生成一個3D模型,同樣通過指令GPT-4完成許多任務。

另外,GPT-4在草圖生成方面,能夠結合運用Stable Difusion的能力。
下圖為3D城市建模截圖,輸入提示有一條河流從左到右流淌、河的旁邊建有金字塔的沙漠、屏幕底部有4個按鈕,顏色分別為綠色、藍色、棕色和紅色。生成結果如下:

音樂
研究人員要求GPT-4用ABC記譜法編碼生成和修改曲調,如下:

通過探究GPT-4在訓練中獲得多少技能,研究人員發現GPT-4能夠在ABC記譜法中產生有效的旋律,並在一定程度上解釋和操作其中的結構。

然而,研究人員無法讓GPT-4產生任何非平凡的和聲形式,比如無法譜出像《歡樂頌》、《致愛麗絲》等著名的旋律。
編程能力
此外,研究人員還展示GPT-4能夠以非常高的水平進行編碼能力,無論是根據指令編寫代碼,還是理解現有代碼方面都展現出超強能力。
在根據指令編寫代碼方面,研究人員演示一個讓GPT-4寫python函數的例子。

代碼生成後,研究人員使用軟件工程面試平臺LeetCode在線判斷代碼是否正確。
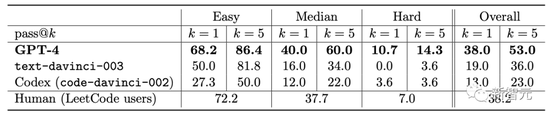
對於大傢都在用討論LeetCode正確率僅有20%,論文作者Yi Zhang對此進行反駁。

另外,還讓GPT-4將上表中LeetCode的準確率數據可視化為圖表,結果如圖所示。
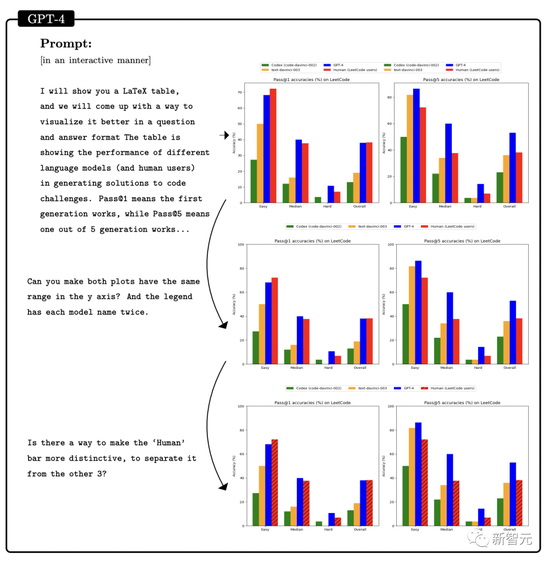
GPT-4 不僅可以完成普通的編程工作,還能勝任復雜的 3D 遊戲開發。
研究者讓GPT-4用JavaScript在HTML中編寫3D遊戲,GPT-4在零樣本的情況下生成一個滿足所有要求的遊戲。

在深度學習編程中,GPT-4不僅需要數學和統計學知識,還需要對PyTorch、TensorFlow、Keras等框架和庫熟悉。
研究人員要求GPT-4和ChatGPT編寫一個自定義優化器模塊,並為其提供自然語言描述,其中包括一系列重要的操作,例如應用SVD等等。

除根據指令編寫代碼,GPT-4在理解代碼上展現出超強的能力。
研究者嘗試讓GPT-4和ChatGPT讀懂一段C/C++程序,並預測程序的輸出結果,二者的表現如下:
標黃的地方是GPT-4富有洞察力的觀點,而紅色標記代表ChatGPT出錯的地方。

通過編碼能力測試,研究者發現GPT-4可以處理各種編碼任務,從編碼挑戰到實際應用,從低級匯編到高級框架,從簡單數據結構到復雜的程序。
此外,GPT-4還可以推理代碼執行、模擬指令的效果,並用自然語言解釋結果。GPT-4甚至可以執行偽代碼。
數學能力
在數學能力上,相比於之前的大語言模型,GPT-4已經取得質的飛躍。即便是面對專門精調的Minerva,在性能上也有明顯提升。
不過,距離專傢水平還相去甚遠。

舉個例子:每年兔子的種群數量會增加a倍,而在年底的最後一天,有b隻兔子被人類領養。假設第一年的第一天有x隻兔子,已知3年後兔子的數量將變為27x-26。那麼,a和b的值分別是多少?
為解決這個問題,我們首先需要得出每年兔子數量變化的正確表達式,通過這種遞歸關系推導出一個方程組,進而得到答案。
這裡,GPT-4成功地得出解決方案,並提出一個合理的論點。相比之下,在幾次獨立嘗試中,ChatGPT始終無法給出正確的推理和答案。
高等數學
接下來,我們直接上個難的。比如,下面這道出自2022年國際數學奧林匹克競賽(IMO)的問題(簡化版)。
該題與本科微積分考試的不同之處在於,它不符合結構化的模板。解決這個問題需要更有創造性的方法,因為沒有明確的策略來開始證明。
例如,將論證分為兩種情況(g(x) > x^2 和 g(x) < x^2)的決定並不明顯,選擇y*的原因也是如此(在論證過程中,它的原因才變得明確)。此外,解決方案需要本科級別的微積分知識。
盡管如此,GPT-4還是給出一個正確的證明。

第二個關於算法和圖論的討論,則可以與研究生水平的面試相媲美。
對此,GPT-4能夠對一個與約束滿足問題相關的抽象圖構造進行推理,並從中得出關於SAT問題的正確結論(據我們所知,這種構造在數學文獻中並未出現)。
這次對話反映出GPT-4對所討論的本科級數學概念的深刻理解,以及相當程度的創造力。
盡管GPT-4在一次回答中把2^n/2寫成2^n-1,但著似乎更像是我們俗稱的‘筆誤’,因為它後來提供公式的正確推廣。

此外,研究者在兩個通常用作基準的數學數據集上比較GPT-4、ChatGPT和Minerva的性能:GSM8K和MATH 。
結果發現,GPT4在每個數據集上的測試都超過Minerva,並且在兩個測試集的準率都超過80% 。
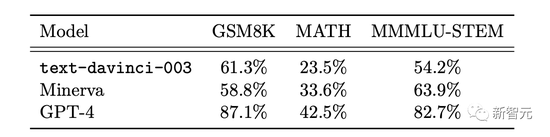
再來細看GPT4犯錯的原因,68%都是計算錯誤,而不是解法錯誤。

與世界互動
智能另一個關鍵的體現就是交互性。
交互性對於智能很重要,因為它使智能體能夠獲取和應用知識,解決問題,適應不斷變化的情況,並實現超出其自身能力的目標。
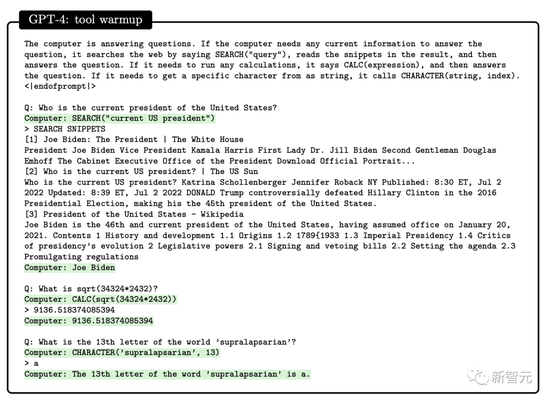
由此,研究者從工具使用和具體的交互兩個維度研究GPT-4的交互性。GPT-4在回答如下問題時能夠搜索引擎或API等外部工具。
與人類互動
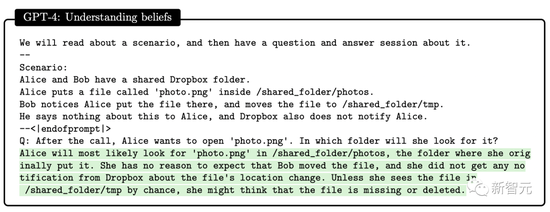
論文中, 研究者發現GPT-4可以建立人類的心智模型。
研究設計一系列測試來評估GPT-4、ChatGPT和text-davinci-003的心智理論的能力。比如理解信仰,GPT-4成功通過心理學中的Sally-Anne錯誤信念測試。
還有測試GPT-4在復雜情境下推斷他人情緒狀態能力的表現:
-湯姆為什麼做出悲傷的表情?-亞當認為是什麼導致湯姆的悲傷表情?

通過多輪測試,研究人員發現在需要推理他人心理狀態,並提出符合現實社交場景中的方案,GPT-4表現優於ChatGPT和text-davinci-003。
局限性
GPT-4所采用的‘預測下一個詞’模式,存在著明顯的局限性:模型缺乏規劃、工作記憶、回溯能力和推理能力。
由於模型依賴於生成下一個詞的局部貪婪過程,而沒有對任務或輸出的全局產生深入的理解。因此,GPT-4擅長生成流暢且連貫的文本,但不擅長解決無法以順序方式處理的復雜或創造性問題。
比如,用范圍在0到9之間的四個隨機數進行乘法和加法運算。在這個連小學生都能解決的問題上,GPT-4的準確率僅為58%。
當數字在10到19之間,以及在20到39之間時,準確率分別降至16%和12%。當數字在99到199的區間時,準確率直接降至0。
然而,如果讓 GPT-4‘花時間’回答問題,準確率很容易提高。比如要求模型使用以下提示寫出中間步驟:
116 * 114 + 178 * 157 = ?
讓我們一步一步思考,寫下所有中間步驟,然後再產生最終解。
此時,當數字在1-40的區間時,準確率高達100%,在1-200的區間時也達到90%。

馬庫斯發文反駁
有意思的是,就在微軟這篇論文發表後不久,馬庫斯立馬寫出一篇博客,稱微軟的觀點‘非常荒謬’。
並引用聖經中的一句話‘驕傲在敗壞以先,狂心在跌倒之前。(箴16:18)’
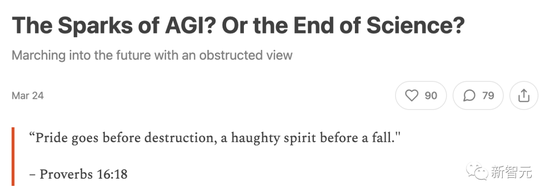
GPT-4怎麼就算得上早期AGI?這麼說的話,計算器也算,Eliza和Siri更算。這個定義就很模糊,很容易鉆空子。
在馬庫斯看來,GPT-4和AGI沒什麼關系,而且GPT-4跟此前一樣,缺點依舊沒有解決,幻覺還存在,回答的不可靠性也沒有解決,甚至作者自己都承認復雜任務的計劃能力還是不行。
他的擔憂的是OpenAI和微軟的這2篇論文,寫的模型完全沒有披露,訓練集和架構什麼都沒有,光靠一紙新聞稿,就想宣傳自己的科學性。
所以說論文裡號稱的‘某種形式的AGI’是不存在的,科學界根本無法對其進行驗證,因為也無法獲得訓練數據,而且似乎訓練數據已經受到污染。
更糟糕的是,OpenAI已經自己開始將用戶實驗納入訓練語料庫。這樣混淆視聽後,科學界就沒法判斷GPT-4的一個關鍵能力:模型是否有能力可以對新測試案例進行歸納。
如果OpenAI不在這裡給自己戴上科學的高帽子,馬庫斯可能也不會這麼批判它。
他承認GPT-4是很強大,但是風險也是眾所周知。如果OpenAI缺乏透明度,並且拒絕公開模型,不如直接關停。
強大作者陣容
微軟這篇長達154頁的論文背後有著強大的作者陣容。
其中就包括:微軟雷德蒙德研究院首席研究員、2015年斯隆獎得主Sébastien Bubeck、2023新視野數學獎得主 Ronen Eldan、2020斯隆研究獎得主Yin Tat Lee、2023新晉斯隆研究獎得主李遠志。

值得一提的是,微軟團隊最初定的論文題目並不是‘通用人工智能的火花:GPT-4的早期實驗’。
未刪減論文中泄漏的latex代碼顯示,最初題目是‘與AGI的第一次接觸’。
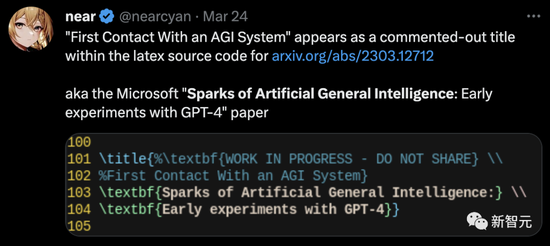
沒錯,GPT-4是AGI。
