GPT-5還未發佈,GPT-6已經在路上?微軟工程師曝出,為GPT-6搭建10萬個H100訓練集群,整個電網卻被搞崩。通往AGI大關,還需要破解電力難題。GPT-6也被電力卡脖子——部署十萬個H100時,整個電網發生崩潰!
就在剛剛,微軟工程師爆料,10萬個H100基建正在緊鑼密鼓地建設中,目的就是訓練GPT-6。
微軟工程師吐槽說,團隊在部署跨區域GPU間的infiniband級別鏈接時遇到困難。
Corbitt:為何不考慮直接將所有設備部署在同一個地區呢?
微軟工程師:這確實是我們最初的方案。但問題是,一旦我們在同一個州部署超過100,000個H100 GPU,電網就會因無法負荷而崩潰。

這是創業者Kyle Corbitt在社交媒體上,分享自己與一位微軟工程師關於GPT-6訓練集群項目的對話
沒想到,GPT-5還沒發,微軟就已悄悄為OpenAI開始訓練GPT-6。
同在今天,一張“OpenAI內部時間線”圖片在網上瘋轉。
圖中清晰標註出:OpenAI早在2022年8月-10月之間開始GPT-5(代號Arrakis)的訓練,2023年4月GPT-4.5(代號Gobi)在訓練中。
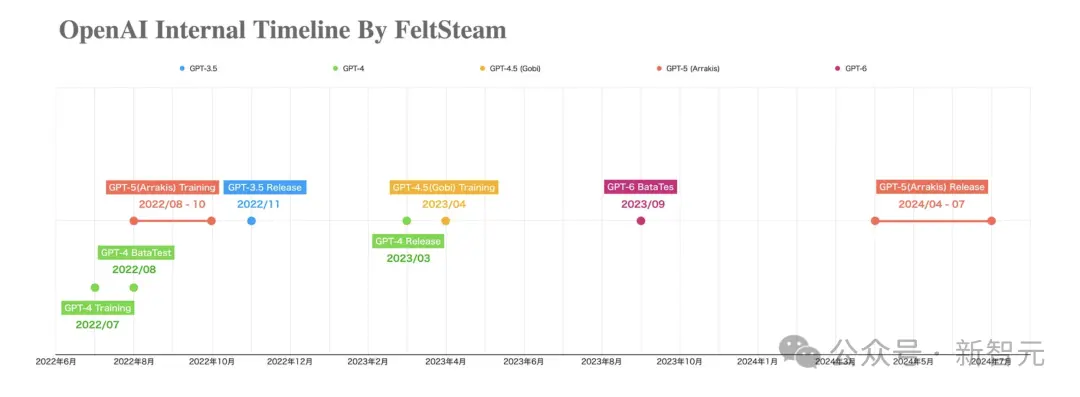
並且圖中顯示,GPT-6的測試,預計早在去年9月就開始!
同時,關於GPT-5(Arrakis)的一個爆料帖,也隨之浮出水面。

太長不看版
貼中爆出許多內幕消息。
比如,GPT-4.5因為能力不夠,幹脆被跳過,所以今年OpenAI會直接發GPT-5。

另外還有若幹未經證實的消息(從上圖中也可以看出),關於OpenAI手中握著的一大把模型——
比如,Arrakis/GPT-5在GPT-4不久後訓練3個月,於22年10月結束;在GPT-5之後,GPT-4.5於23年4月完成訓練。
最勁爆的消息當然就是,現在GPT-6或許已經在訓練中。

但是,GPT-5並不是AGI,因為無法解決“量子引力”問題。同理,GPT-6也不是AGI。
接下來,讓我們一一盤點下,帖子中都有哪些信息點。
最接近AGI的模型,與人類專傢不相上下
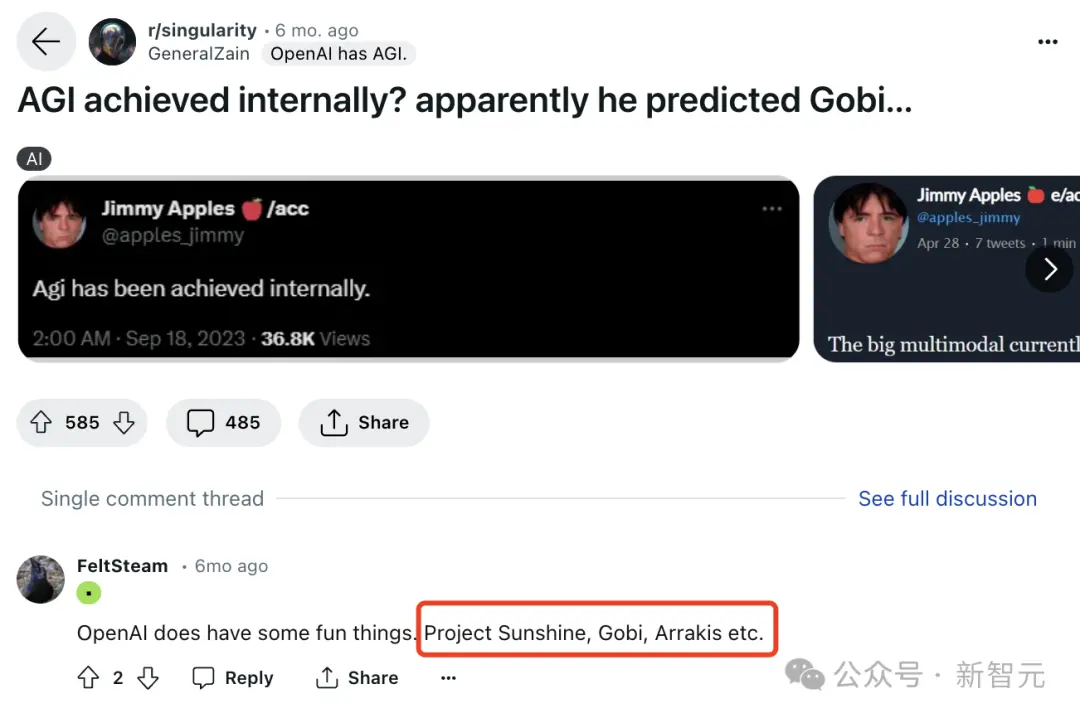
去年8月,FeltSteam最先曝出OpenAI內部正在進行一個Arrakis多模態模型的項目,遠超GPT-4,非常接近AGI。

Arrakis項目被首次提及,是名叫FeltSteam的網友最先在Reddit一個評論區中爆料稱,“Arrakis和Gobi都很酷”。
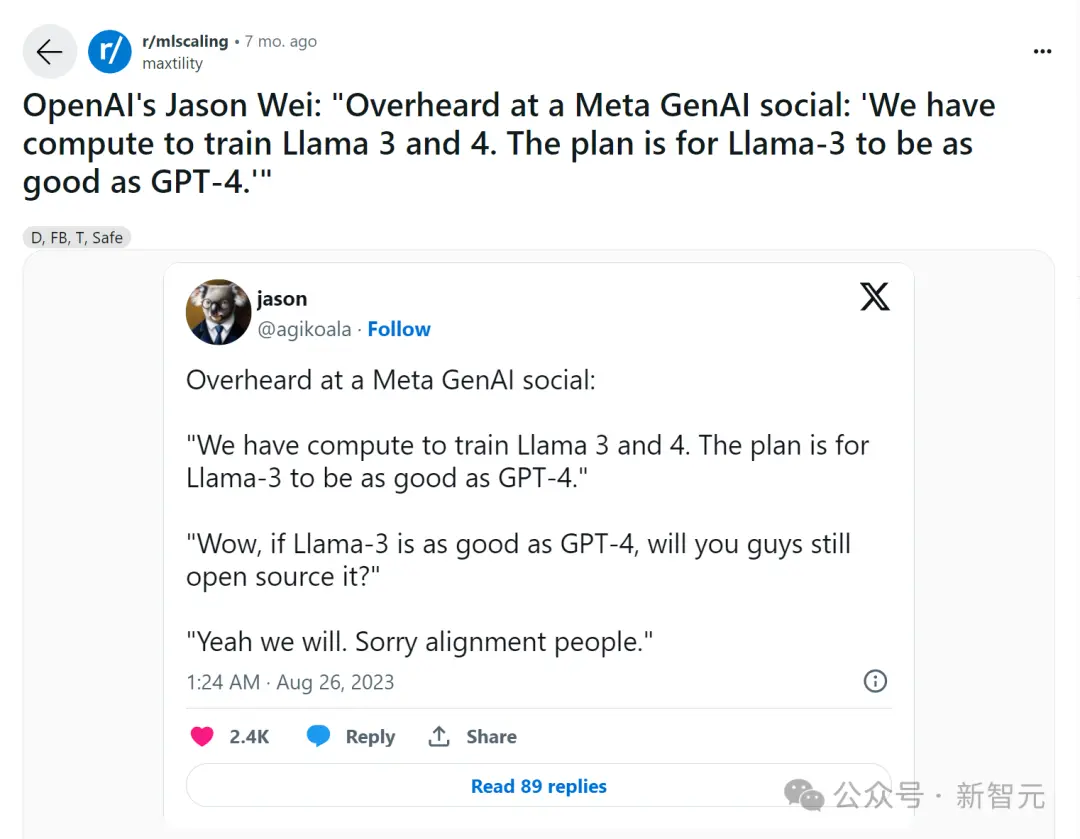

並且,他在r/singularity板塊中另一個問題下, 介紹Arrakis的一些能力。
他提到,“這是一個無所不能的模型,可以輸入文本、圖像、音頻和視頻的任何組合”。
具體來說,Arrakis更多的細節包括:
- 多模態模型
- 性能遠超GPT-4
- 接近AGI
- 幻覺發生率明顯低於GPT-4
- Altman正試圖將Arrakis作為一種工具來推銷,盡管它是有感情的
- 推理成本略低於GPT-4
- 非常優秀的自主智能體
- 訓練一般數據是合成的
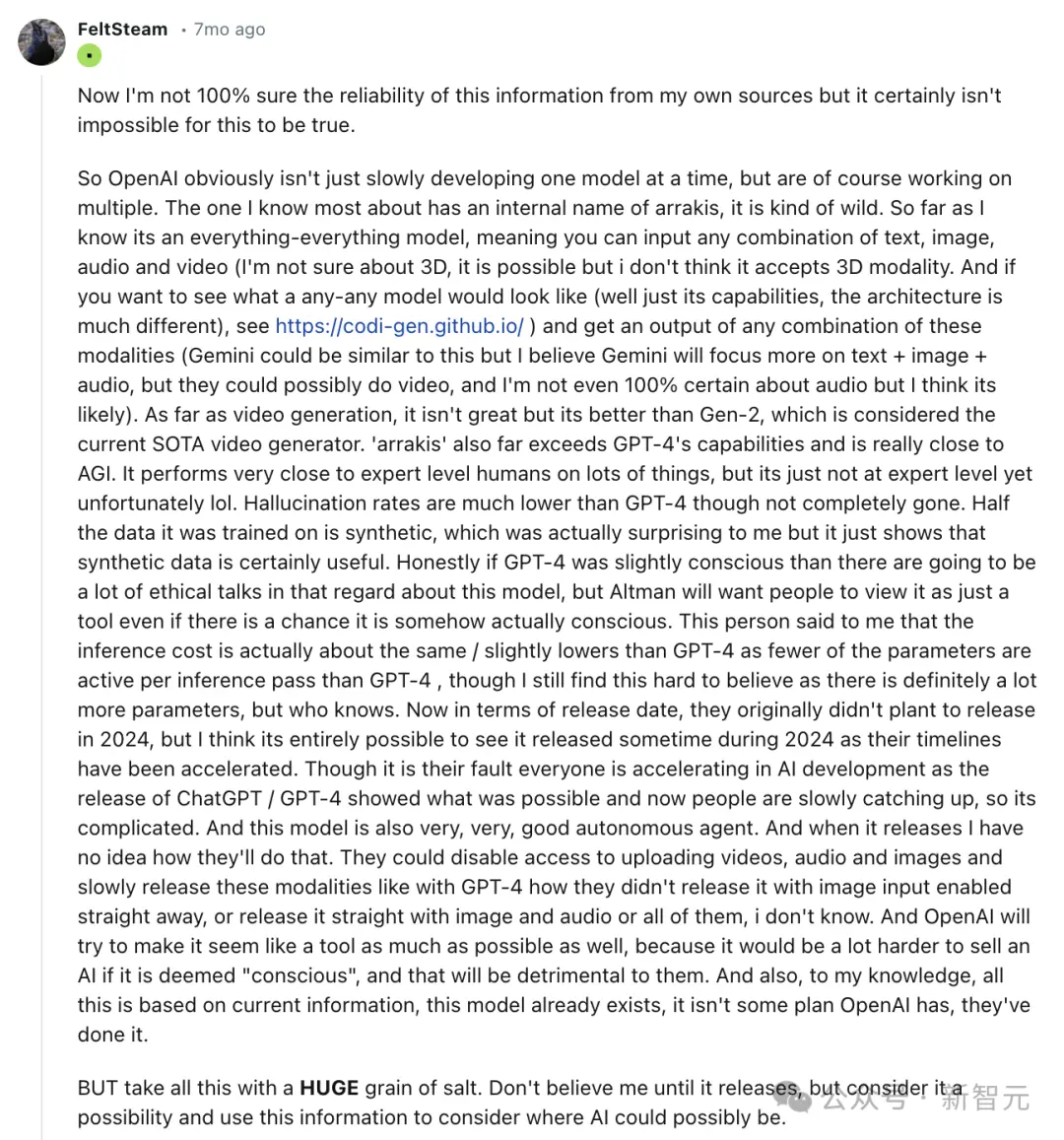
與此同時,Jimmy Apples在社交媒體上曝出OpenAI內部代號Gobi的項目——大規模多模態模型。
除以上兩個項目,一個代號名為“Sunshine”的項目逐漸浮出水面。
OpenAI這些秘密進行的項目,一時間引來許多網友的猜測和討論。
隨後,FeltSteam又爆出更多的細節,Arrakis據稱有125萬億參數,大約是GPT-4的100倍,並在2022年10月完成訓練。
值得一提的是,Arrakis不是通過計算資源實現的,而是通過提高計算效率實現的。
目前,OpenAI內部也在使用Arrakis進行研究,不過整體員工水平肯定優於Arrakis。另外,與GPT-5相比,Gobi更接近GPT-4.5。
到10月,FeltSteam再一次表示,一個比GPT-4大100倍的模型即將問世。
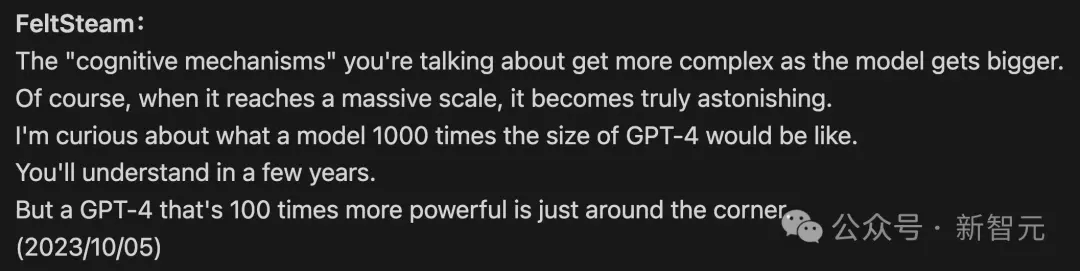
GPT-5將在2024年年中,或在2024年第三季度發佈。
最近BussinessInsider的報道稱,知情人士透露,GPT-5或將在今年夏天發佈。與FeltSteam預測的時間幾乎吻合。

而Arrakis是GPT-5一個更強大的候選者,在多個領域具備人類水平的專業知識能力。
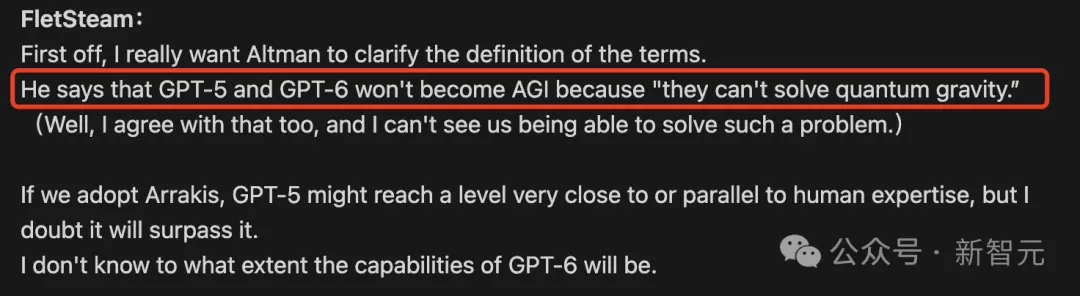
GPT-5不是AGI
不過,Arrakis並不符合Altman對AGI的定義,即解決“量子引力”的問題。

量子引力,又稱量子重力,是描述對重力場進行量子化的理論,屬於萬有理論之一隅;主要嘗試結合廣義相對論與量子力學,為當前物理學尚未解決的問題
但正如之前所說,Arrakis模型還是能夠達到人類專傢水平。
GPT-5和GPT-6都不是AGI
FeltSteam表示,傳說中的AGI,是Arrakis以外的東西。
但是,為什麼我們能在這麼短的時間裡,訓練出一個125萬億參數的模型呢?
理論上來說,如果訓一個1.75萬億參數模型需要4-5個月,那麼如果訓練一個大百倍的模型,應該需要幾十年。
(目前已知,GPT-4在A100集群上訓100天,但是在訓練之後,OpenAI又花幾個月時間對它微調和對齊。)
顯然,要訓125萬億參數的模型,不僅要投入原始計算資源,還要顯著提高計算效率。
用90%合成數據訓練
另一個比較值得關註的信息是,據稱Arrakis去年訓練的數據集中約90%是合成數據。

此前,外媒報道稱:
Ilya Sutskever的突破讓OpenAI克服在獲取高質量數據以訓練新模型方面的限制,而這正是開發下一代模型的主要障礙。這項研究涉及使用計算機生成的數據,而不是真實世界的數據,如從互聯網上提取的文本或圖像來訓練新模型。
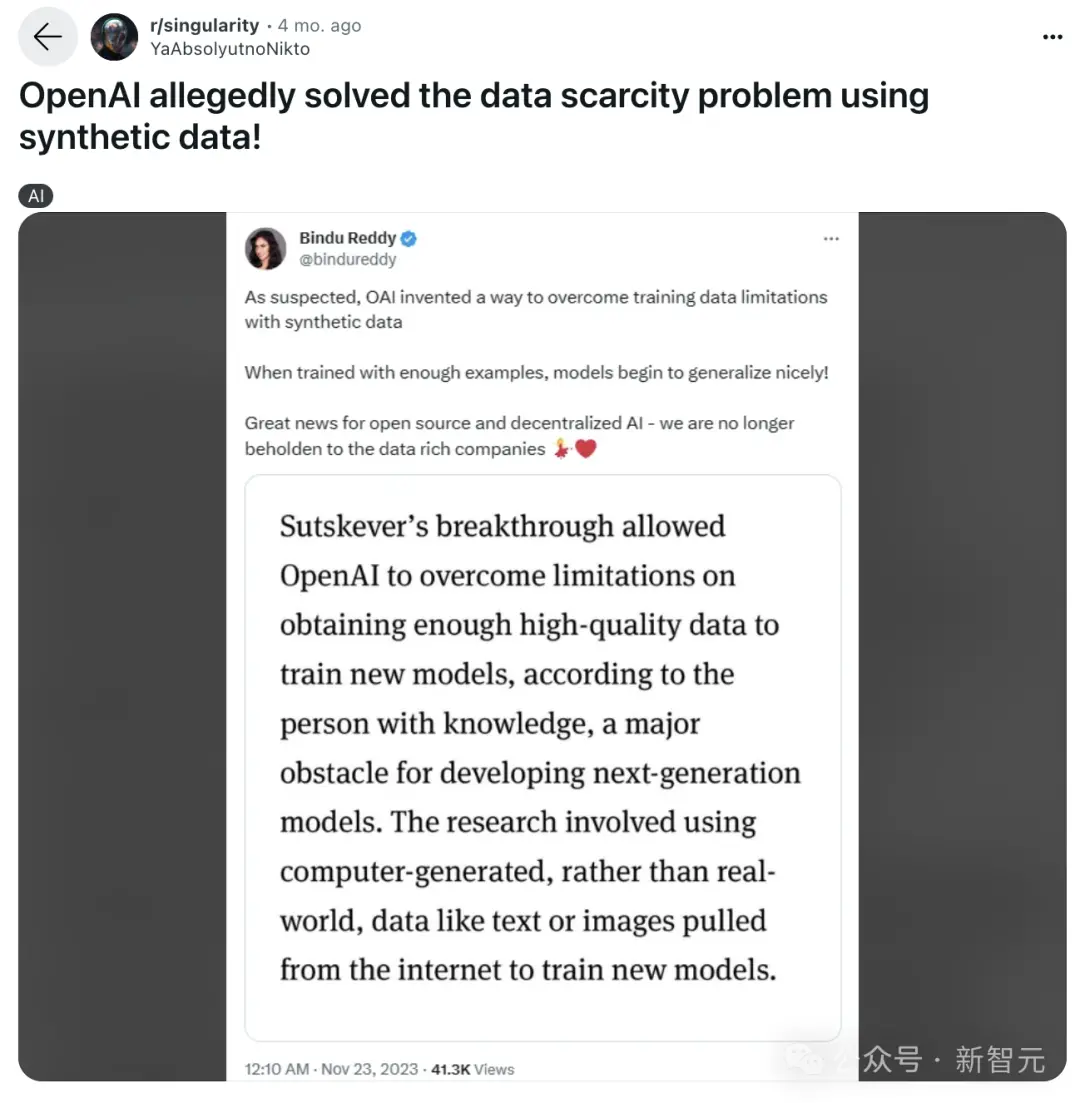
FeltSteam認為,OpenAI正遇到擴展(scaling)的難題,因為僅僅擴展註意力和模型參數是遠遠不夠的。
目前,GPT-4的訓練已經窮盡整個互聯網的數據,還需要進行強化學習,甚至更多的數據。
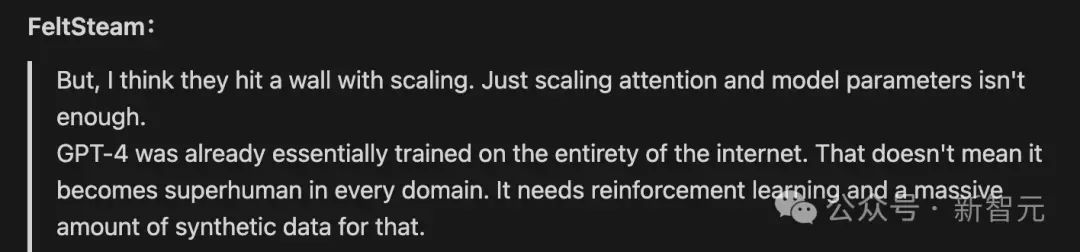
另外,Arrakis還是一個非常出色的自主智能體。
所有關於OpenAI項目信息匯總目錄一覽表。

十萬個H100訓GPT-6,被電力卡脖子
就在以上的爆料帖中,有一種說法是,GPT-6將於2025年發佈。
而就在爆料微軟工程師對話的帖子中,也再次證實:微軟正用10萬個H100來幫OpenAI訓練GPT-6!
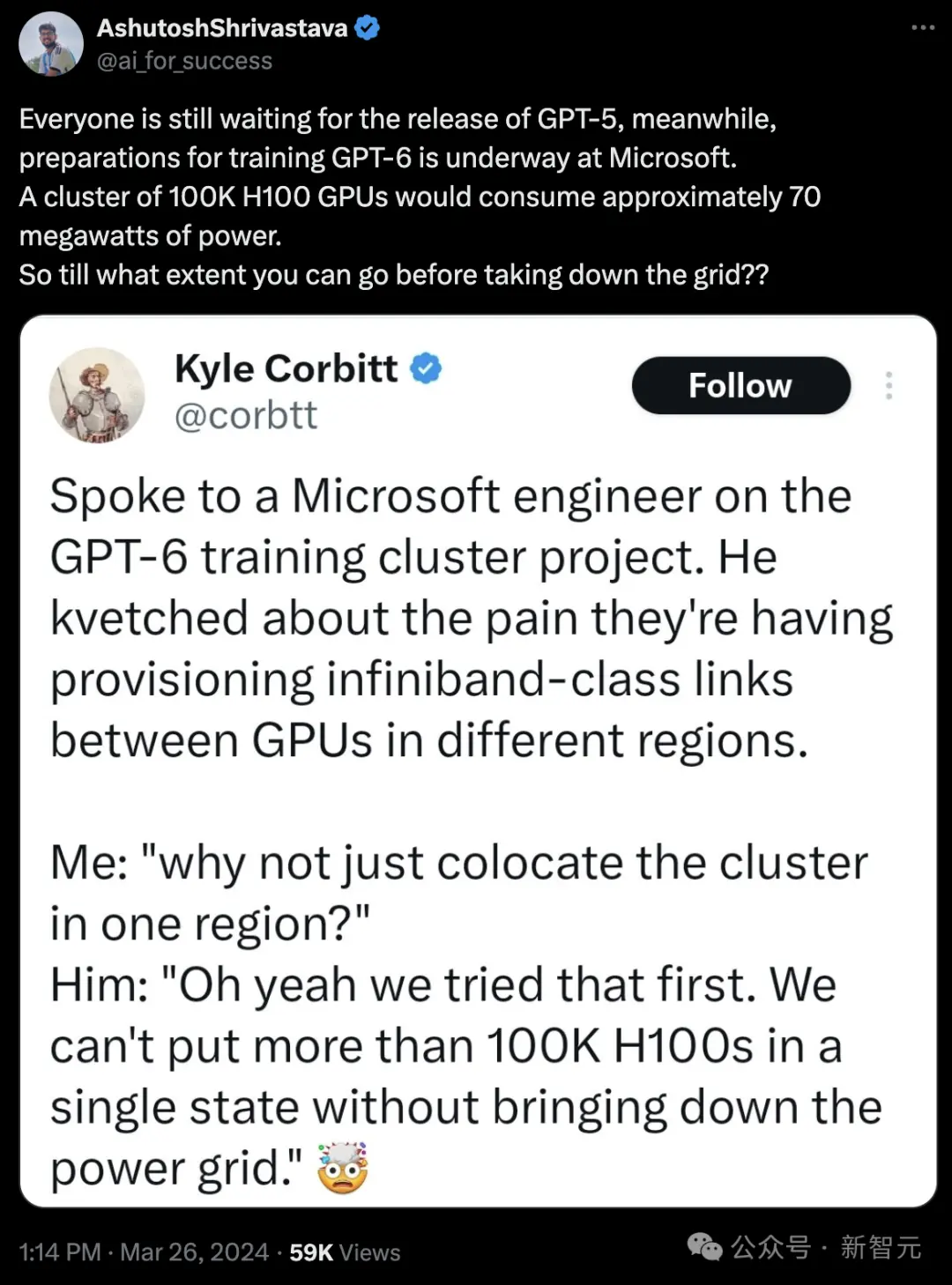
有網友算一下,如果十萬個H100同時開啟,功耗將達到70兆瓦,電網肯定撐不住。
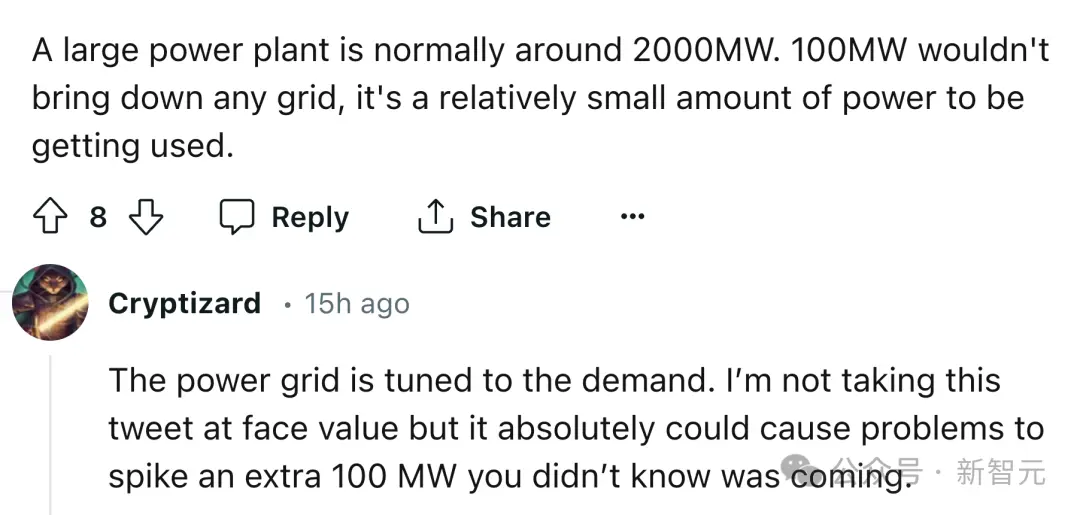
而熟悉電力行業的網友說,一般大型電廠的輸出功率將達到2000兆瓦,100兆瓦的負載其實並不大。但是突然在電網中增加100兆瓦的負載肯定會讓電網系統出問題。
核能也許是唯一的辦法,電力短缺將直接限制未來GPU的發展。

此前,ChatGPT每天耗電已超50萬千瓦時,登上熱搜,足見AI“吃電”非常兇猛。

根據波士頓咨詢集團的分析,到2030年,數據中心的用電量預計將增加兩倍,相當於為大約4000萬美國傢庭供電所需的電力量
沒想到,馬斯克預言的由AI導致的電力短缺,這麼快就卡住AGI的脖子。
馬斯克:“現在AI對算力的需求差不多每半年就會增加10倍,馬上會超過宇宙的質量。芯片短缺緩解後,馬上就會出現電力短缺。如果電網輸出100-300千伏的電壓,然後必須一路降壓至6伏,未來會出現變壓器短缺”。
包括Sam Altman在內的越來越多的AI行業大佬表示,AI的第一性原理,最重要的部分就是能源和智能的轉化率的問題。
而人工智能是能源的無底洞,AI未來將會被能源卡脖子。
因為Transformer本質上不是一個能效很高的算法,所以在未來,能源將會是困擾AI發展的一個大問題。

對此,網友們表示,長期看好中國基建。
而在Altman看來,滿足AI飆升能源需求的最有效方法,就是核聚變。

為此,他本人就在核聚變上投資真金白銀的數億美元。
沒有突破,就沒有辦法到達那裡,我們需要核聚變。
然而,真要達成核聚變,卻沒那麼快。
英國曼徹斯特大學核聚變研究員Aneeqa Khan表示,“在地球上重建太陽中心的條件是一個巨大的挑戰”,可能要到本世紀下半葉才能準備就緒。
“核聚變已經為時已晚,無法應對氣候危機。在短期內,我們可利用的是現有的低碳技術,比如裂變和可再生能源”。

國際能源署(IEA)最近的一項分析計算出,數據中心、某貨和人工智能的電力消耗在未來兩年內可能會翻一番。2022年,它們約占全球電力需求的2%。同時AI的需求將呈指數級增長,在2023年至2026年間至少增長10倍
此外,除電力的限制之外,網友還繼續腦洞大開,認為散熱也將成為一個問題。
10萬塊H100還會帶來散熱和空間堆疊的問題,其實最近3年這些問題一直都存在,未來還會越來越嚴重。
網友進一步調侃到,未來加拿大會成為AI大國,因為他們有取之不盡的寒冷且幹燥的空氣!這些在AI時代將會是寶貴的自然資源。