Meta的第二代自研芯片正式投產!小紮計劃今年部署ArtemisAI芯片為AI提供算力,以減少對英偉達GPU的依賴。據悉,新的芯片將被用於數據中心的推理(Inference)任務,並與英偉達等供應商的GPU一起協同工作。
對此,Meta的發言人表示:“我們認為,我們自主開發的加速器將與市面上的GPU相得益彰,為Meta的任務提供最佳的性能與效率平衡。”
除更高效地運行的推薦模型外,Meta還需要為自傢的生成式AI應用,以及正在訓練的GPT-4開源競品Llama 3提供算力。
Meta的AI貼紙功能,此前在Messenger、Instagram和WhatsApp上都處於測試階段
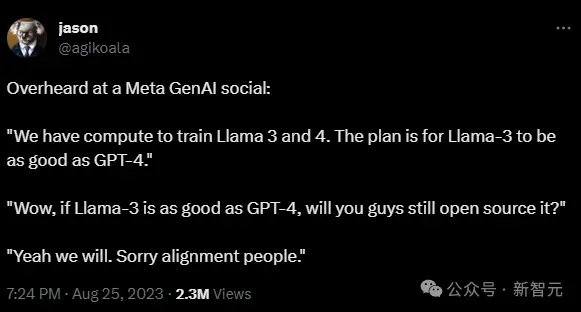
OpenAI工程師Jason Wei在Meta的一次AI活動中聽到,Meta現在有足夠的算力來訓練Llama 3和4。Llama 3計劃達到GPT-4的性能水平,但仍將免費提供
不難看出,Meta的目標非常明確——在減少對英偉達芯片依賴的同時,盡可能控制AI任務的成本。
Meta成英偉達大客戶
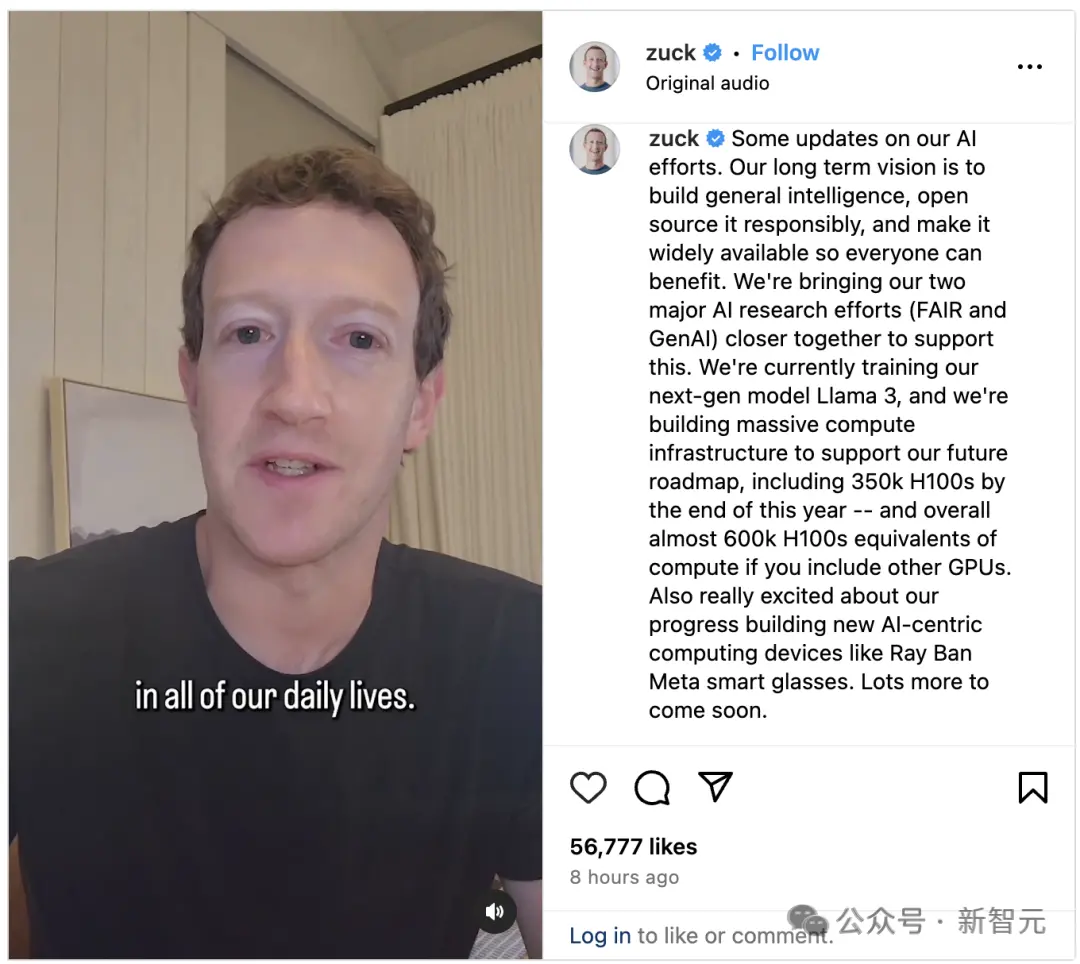
Meta CEO小紮最近宣佈,他計劃到今年年底部署35萬顆英偉達H100 GPU,總共將有約60萬顆GPU運行和訓練AI系統。
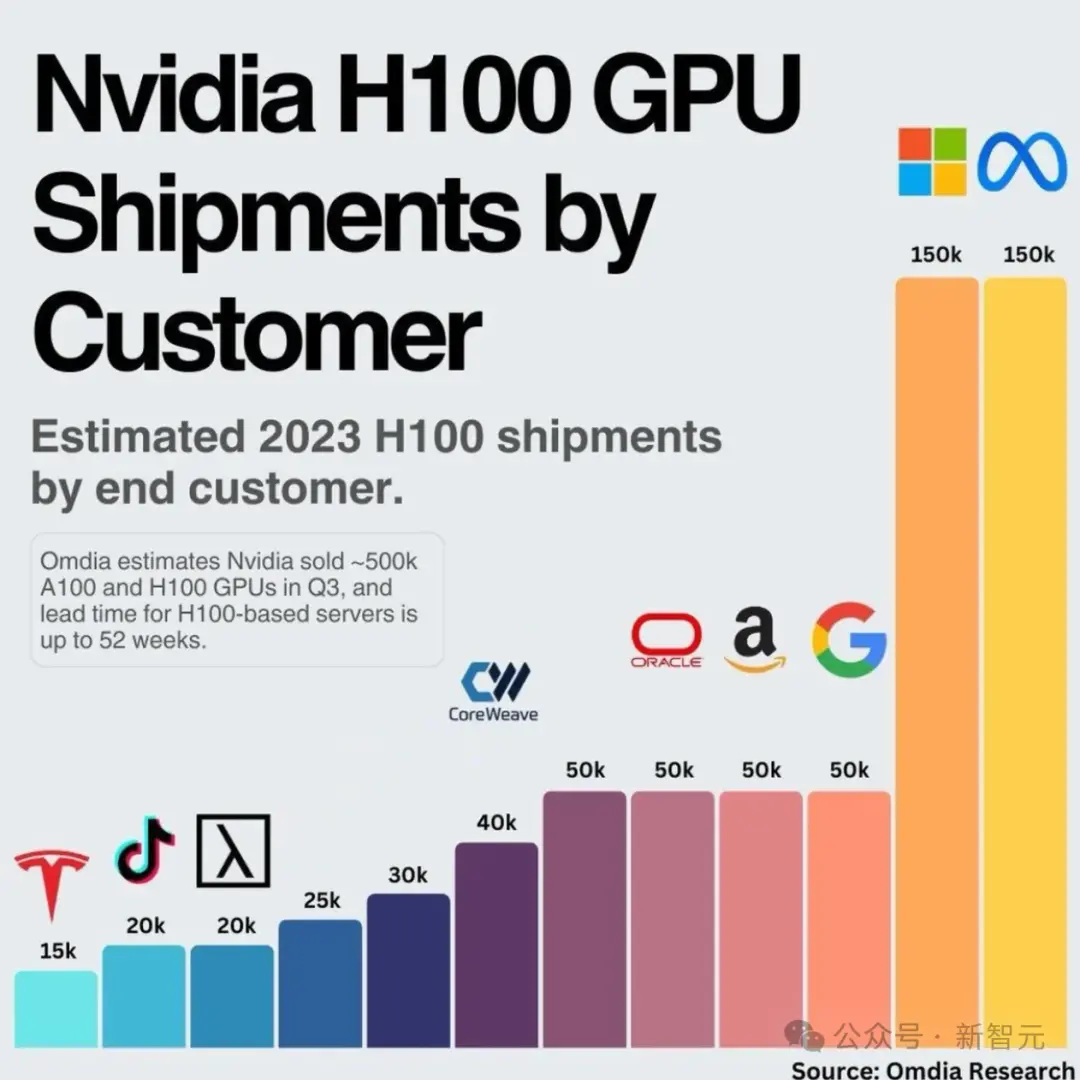
這也讓Meta成為繼微軟之後,英偉達最大的已知客戶。
小紮表示,目前Meta內部正在訓練下一代模型Llama 3。
在35萬塊H100上訓練的Llama 3,無法想象會有多大!


Omdia的研究數據顯示,Meta在2023年H100的出貨量為15萬塊,與微軟持平,且是其他公司出貨量的3倍。
小紮稱,“如果算上英偉達A100和其他AI芯片,到2024年底,Meta將擁有近60萬個GPU等效算力”。
性能更強、尺寸更大的模型,導致更高的AI工作負載,讓成本直接螺旋式上升。
據《華爾街日報》的一位匿名人士稱,今年頭幾個月,每有一個客戶,微軟每月在Github Copilot上的損失就超過20美元,甚至某些用戶每月的損失高達80美元,盡管微軟已經向用戶收取每月10美元的費用。
之所以賠錢,是因為生成代碼的AI模型運行成本高昂。如此高的成本,讓大科技公司們不得不尋求別的出路。
除Meta之外,OpenAI和微軟也在試圖打造自己專有的AI芯片以及更高效的模型,來打破螺旋式上升的成本。

此前外媒曾報道,Sam Altman正計劃籌集數十億美元,為OpenAI建起全球性的半導體晶圓廠網絡,為此他已經在和中東投資者以及臺積電談判
專為大模型定制AI芯
去年5月,Meta首次展示最新芯片系列——“Meta訓練和推理加速器”(MTIA),旨在加快並降低運行神經網絡的成本。
MTIA是一種ASIC,一種將不同電路組合在一塊板上的芯片,允許對其進行編程,以並行執行一項或多項任務。

內部公告稱,Met首款芯片將在2025年投入使用,同時數據中心開啟測試。不過,據路透社報道,Artemis已經是MTIA的更高級版本。
其實,第一代的MITA早就從2020年開始,當時MITA v1采用的是7nm工藝。
該芯片內部內存可以從128MB擴展到128GB,同時,在Meta設計的基準測試中,MITA在處理中低復雜度的AI模型時,效率要比GPU還高。
在芯片的內存和網絡部分,Meta表示,依然有不少工作要做。
隨著AI模型的規模越來越大,MITA也即將遇到瓶頸,因此需要將工作量分擔到多個芯片上。
當時,Meta團隊還設計第一代MTIA加速器,同樣采用臺積電7nm,運行頻率為800MHz,在INT8精度下提供102.4 TOPS,在FP16精度下提供51.2 TFLOPS。它的熱設計功耗(TDP)為25W。

2022年1月,Meta還推出超算RSC AI,並表示要為元宇宙鋪路。RSC包含2000個英偉達DGX A100系統,16000個英偉達A100 GPU。
這款超算與Penguin Computing、英偉達和Pure Storage合作組裝,目前已完成第二階段的建設。