微軟可能已經與OpenAI及其GPT大型語言模型合作,幫助創建生成式人工智能服務,如Copilot(前身為必應聊天工具)。不過,該公司也在開發自己的語言模型。本周,微軟研究院宣佈發佈Orca2,這是其Orca語言的第二個版本。
微軟在一篇博文中表示,Orca 2 是專為小規模 LM 設計的,但仍可用於回答 LLM 等復雜問題。Orca 2有兩種大小(70億和130億個參數),部分是利用今年早些時候微軟幫助Meta推出的Llama 2 LLM制作的。該公司"根據量身定制的高質量合成數據"對基於 Llama 2 的模型進行微調。
微軟表示,這使得Orca 2模型在處理問題時能夠與其他"5-10倍大"的語言模型相媲美:
Orca 2 使用擴展的、高度定制的合成數據集進行訓練。這些訓練數據的生成,向 Orca 2 傳授各種推理技術,如逐步處理法、回憶然後生成法、回憶-推理-生成法、提取-生成法和直接回答法,同時還教會它針對不同的任務選擇不同的解決策略。
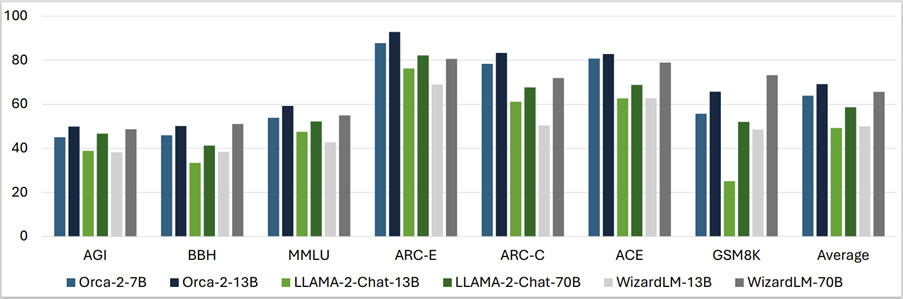
Orca 2 模型與 Llama 2 和 WizardLM 等大型語言模型進行一系列基準測試,測試內容包括"語言理解、常識推理、多步驟推理、數學問題解決、閱讀理解"等。
微軟官方博客稱:我們的初步測試結果表明,Orca 2 的性能大大超越類似規模的模型。它還達到類似或優於至少比它大 10 倍的模型的性能水平,展示為更小的模型配備更好的推理能力的潛力。
雖然微軟承認Orca 2確實存在局限性,但迄今為止的測試顯示"未來進步的潛力"。微軟將把 Orca 2 作為一個開源項目發佈,以便其他人也能對其進行開發。