據anandtech報道,高性能計算(HPC)領域越來越明顯的一個趨勢是,每個芯片和每個機架單元的功耗不會因空氣冷卻的限制而停止。由於超級計算機和其他高性能系統已經達到——並且在某些情況下超過瞭這些限制——功率要求和功率密度不斷擴大。根據臺積電最近一年一度的技術研討會的消息,隨著臺積電為更密集的芯片配置奠定基礎,我們應該期待看到這種趨勢繼續下去。
手頭的問題並不是一個新問題:晶體管功耗的縮小速度幾乎沒有晶體管尺寸那麼快。由於芯片制造商不會放棄性能(並且無法為客戶提供半年增長),因此在 HPC 空間中,每個晶體管的功率正在迅速增長。另一個問題是,chiplet正在為構建具有比傳統標線限制更多矽的芯片鋪平道路,這對性能和延遲有好處,但在冷卻方面更成問題。
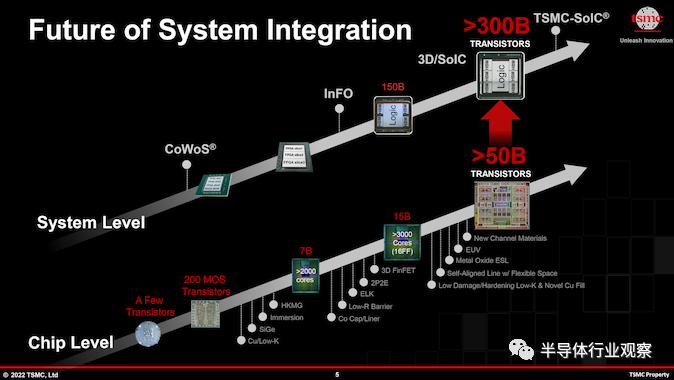
支持這種矽和功率增長的是 臺積電 CoWoS 和 InFO等現代技術,它們允許芯片制造商構建集成的多芯片系統級封裝 (SiP),其矽量是臺積電的兩倍。受到標線(reticle )限制。到 2024 年,臺積電 CoWoS 封裝技術的進步將使構建更大的多芯片 SiP 成為可能,臺積電預計將超過四個標線大小的芯片縫合在一起,這將實現巨大的復雜性(每個 SiP 有可能超過 3000 億個晶體管)臺積電及其合作夥伴正在關註)和性能,但自然是以巨大的功耗和發熱為代價的。
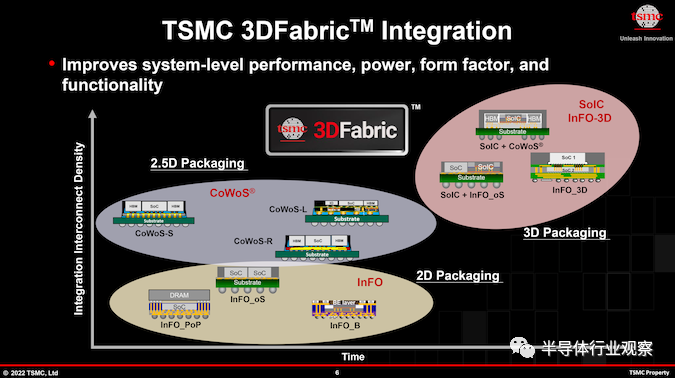
NVIDIA 的 H100 加速器模塊等旗艦產品已經需要超過 700W 的功率才能實現峰值性能。因此,在單個產品上使用多個 GH100 大小的chiplet的前景令人大跌眼鏡 - 以及功率預算。臺積電預計,幾年後將出現功耗約為 1000W 甚至更高的多芯片 SiP,從而帶來冷卻挑戰。
在 700W 時,H100 已經需要液冷;英特爾的基於chiplet的 Ponte Vecchio 和 AMD 的 Instinct MI250X 的故事大致相同。但即使是傳統的液體冷卻也有其局限性。當芯片累計達到 1 kW 時,臺積電設想數據中心將需要為這種極端的 AI 和 HPC 處理器使用浸入式液體冷卻系統。反過來,浸入式液體冷卻將需要重新構建數據中心本身,這將是設計上的重大變化,也是連續性方面的重大挑戰。
撇開短期挑戰不談,一旦數據中心設置為浸入式液體冷卻,它們將為更熱的芯片做好準備。液浸式冷卻在處理大型冷卻負載方面具有很大潛力,這也是英特爾大力投資這項技術以使其更加主流化的原因之一。
除瞭浸沒式液體冷卻,還有另一種技術可以用來冷卻超熱芯片——片上水冷。去年,臺積電透露它已經嘗試過片上水冷,並表示甚至可以使用這種技術冷卻 2.6 kW 的 SiP。但當然,片上水冷本身就是一項極其昂貴的技術,它將把那些極端的 AI 和 HPC 解決方案的成本推到前所未有的水平。
盡管如此,雖然未來不是一成不變的,但似乎它已經用矽鑄造瞭。臺積電的芯片制造客戶有客戶願意為這些超高性能解決方案(想想超大規模雲數據中心的運營商)支付高昂的費用,即使這需要高成本和技術復雜性。讓事情回到我們開始的地方,這就是臺積電首先開發 CoWoS 和 InFO 封裝工藝的原因——因為有客戶準備好並渴望通過chiplet技術打破標線限制。今天,我們已經在 Cerebras 的大型晶圓級引擎處理器等產品中看到瞭其中的一些,並且通過大型小芯片,臺積電正準備讓更廣泛的客戶群更容易獲得更小的(但仍然是標線斷裂)設計。
對性能、封裝和冷卻的這種極端要求不僅將半導體、服務器和冷卻系統的生產商推向瞭極限,而且還需要對雲數據中心進行修改。如果用於 AI 和 HPC 工作負載的大規模 SiP 確實變得普遍,那麼未來幾年雲數據中心將完全不同。