雖然摩爾定律已經逐漸走到盡頭,但我們卻來到一個更加看點十足的時代,不同於以往每隔18個月靠工藝迭代帶來的常規演變,以英特爾、英偉達和AMD為首的芯片巨頭之間的競爭變得異常激烈。從英特爾、英偉達、AMD三傢的產品佈局來看,三傢幾乎都集齊CPU、GPU甚至是DPU產品線。如今,他們正在醞釀更大的規劃!
隨著近日AMD推出CPU和GPU組合的下一代數據中心APU——Instinct MI300,自此,三傢的“多PU組合”爭鬥戰已然打響。
在此之前,英特爾的Falcon Shores XPU混合搭配CPU + GPU,英偉達的Grace Hopper Superchip是Grace CPU + H100 GPU的組合,都是如出一轍。
他們都在做一件偉大的事情:在一個芯片中集成CPU、GPU和AI加速器,最終成為一個類似APU的產品,目標是更廣闊的超級計算市場。
但是在實現方式上,英偉達落後?
英特爾的XPU計劃之一:Falcon Shores
首先來說下英特爾的XPU計劃?XPU是指使用多種計算架構以最好地滿足單個工作負載的執行需求的想法,這是英特爾過去幾年來最感興趣的一個方向。
英特爾希望將X86和Xe結合起來用於超級計算/HPC市場。這也導致英特爾開始研發從CPU、GPU個一些ASIC產品(如IPU、VPU、FPGA)等等各種產品。
在英特爾2022年年度投資者會議上,英特爾披露一個代號為Falcon Shores的處理器新架構,它將x86 CPU和Xe GPU硬件組合到單個Xeon插槽芯片中,利用下一代封裝、內存和 I/O 技術,為計算大型數據集和訓練巨大 AI 模型的系統提供巨大的性能和效率改進。
不過英特爾的目標似乎不僅僅是將CPU和GPU集成在一起,英特爾正在尋求為擁有絕對海量數據集HPC用戶開辟市場——這種數據集無法輕松適應獨立GPU相對有限的內存容量。
Falcon Shores的目標是在2024年推出,采用埃米級制程,這意味著它可能會使用Intel 20A或Intel 18A制造工藝制造。
英特爾預計Falcon Shores在多個指標上比當前一代產品增長5倍,包括每瓦性能提高5倍,單個 (Xeon) 插槽的計算密度提高5倍,內存容量增加5倍,內存帶寬增加5倍。

英特爾表示,Falcon Shores的混合設計是通過使用tile(也稱為小芯片)實現的,通過提供x86和Xe內核之間的靈活比例,這將使芯片制造商在設計過程的後期配置芯片方面具有更大的靈活性。
AMD發佈Instinct MI300 APU
近日,AMD在CES 2023上披露其下一代數據中心處理器Instinct MI300,被AMD稱之為下一代數據中心APU。它采用13個Chiplet,共有1460億個晶體管,MI300可以說是AMD迄今為止最大的芯片。
該芯片的計算部分由九個5nm小芯片組成,它們包含CPU或GPU內核,但AMD沒有詳細說明每個小芯片的使用數量。
這九個裸片被3D堆疊在四個6nm基礎裸片之上,而且這些裸片是有源的中介層,可以處理 I/O和各種其他功能。從下圖中可以清晰的看到,Instinct MI300中心芯片側面的八個HBM3堆棧。

圖源:Future
MI300的關鍵優勢除將CPU內核和GPU內核放在同一設計中的操作簡單性之外,還在於它可以讓兩種處理器類型共享一個高速、低延遲的統一內存空間。
這將使在CPU和GPU兩個核之間快速且輕松的傳遞數據,能讓每個核處理他們最擅長的計算方面。此外,它還可以通過讓兩種處理器類型直接訪問同一內存池,簡化插槽級別的HPC編程。
但是MI300芯片並不是批量產品,因為其價格昂貴且相對稀缺,所以它們不會像EPYC Genoa數據中心CPU那樣得到廣泛部署。AMD預計將在2023年下半年交付Instinct MI300。
但是,這一Chiplet的設計技術將會衍生出更多的變體。
英偉達Grace Hopper Superchip
不同於英特爾和英偉達采用Chiplet架構的做法,英偉達首款GPU+CPU組合——Grace Hopper Superchip還是單芯片的方式,下圖是渲染圖。

Nvidia對其Grace Superchip的渲染圖:兩個帶有RAM的處理器合二為一
NVIDIA?Grace Hopper架構將NVIDIA Hopper GPU與NVIDIA Grace? CPU結合在一起,在單個超級芯片中連接高帶寬和內存一致的NVIDIA NVLink Chip-2-Chip(C2C)?互連,並支持新的NVIDIA NVLink開關系統。
NVLink C2C是NVIDIA為超級芯片開發的內存相幹、高帶寬和低延遲互連。它是Grace Hopper超級芯片的核心,提供高達900 GB/s的總帶寬。這比加速系統中常用的x16 PCIe Gen5通道的帶寬高7倍。
結合NVIDIA NVLink切換系統,所有運行在最多256個NVLink連接的GPU上的GPU線程現在都可以以高帶寬訪問高達150TB的內存。
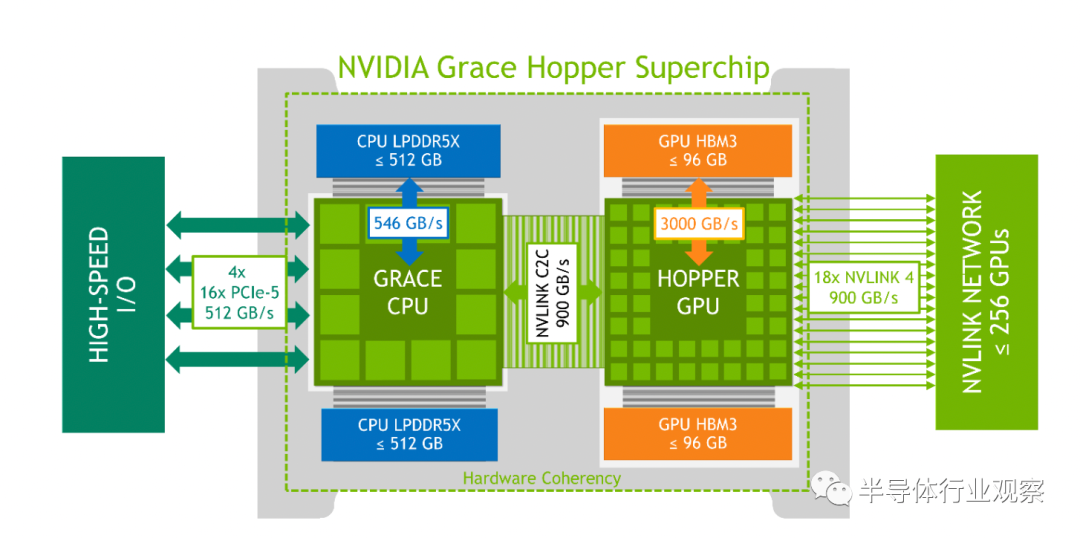
NVIDIA Grace Hopper超級芯片邏輯一覽(圖源:英偉達)
英偉達表示,該超級芯片將為運行TB級數據的應用程序提供高達10倍的性能提升,英偉達已承諾在2023年上半年推出其超級芯片。
可以看出,英特爾、英偉達和AMD都開始在CPU+GPU組合上發力,他們所采用的方式:要麼芯片繼續平鋪做大,要麼拼3D堆疊、Chiplet、拼架構。
目前從各傢的CPU+GPU組合型產品推出的時間上來看,AMD和英偉達都在2023年,而英特爾將在2024年。軟件支持方面,英特爾有oneAPI,英偉達有CUDA,AMD似乎還稍遜一些。
而在架構方面,英特爾、AMD均已奔向3D Chiplet,但英偉達似乎仍在單芯片上努力。
英偉達何時擁抱Chiplet?
Chiplet用於CPU已經不是新聞,AMD多年來一直在其Ryzen和Epic等CPU處理器中使用Chiplet設計並取得巨大成功。
英特爾也於2023年1月11日正式發佈基於Chiplet設計的第四代至強CPU-Sapphire Rapids,它通過內置加速器將目標工作負載的平均每瓦性能提升2.9倍,在優化電源模式下每個CPU節能可高達70瓦,將總體成本降低52%-66%。
但是就目前的情況來看,GPU也已邁入Chiplet時代。
如今英特爾和AMD已經均已發佈3D Chiplet CPU和GPU中的產品。
而英偉達無論是GPU還是CPU似乎還在單芯片上努力,英偉達要落後嗎?
2023年1月11日,英特爾發佈其首款Chiplet小芯片封裝的GPU,代號Ponte Vecchio,GPU Max系列單個產品整合47個小芯片,集成超過1000億個晶體管。
這是英特爾性能最高、密度最高的通用獨立GPU。英特爾的這一芯片的具體性能對比情況暫未可知,但是我們暫且可以看看AMD與英偉達的GPU性能對比。
AMD最新一代的GPU Navi 31,是AMD第一款、也可以說是歷史上第一個基於Chiplet設計的GPU,AMD的兩款最新顯卡Radeon RX 7900 XTX和Radeon RX 7900 XT均是基於Navi 31。
其中,XTX是旗艦機型,擁有更多的shader處理器,更高的內存帶寬,更多的顯存,而XT則是有些弱化的版本。
如果我們將AMD的顯卡和英偉達的RTX 4080作對比,AMD的GPU的性能非常接近英偉達的RTX 4080。
據chipsandcheese的評測對比數據,如下圖所示,英偉達的4080采用4nm制程,晶體管密度比AMD的低一些,面積也更大一些,但英偉達4080具有更高的SM數量,這意味著寄存器文件和FMA單元相比AMD要有更多的邏輯控制。
英偉達還具有更簡單的緩存層次結構的優勢,它仍然提供相當大的緩存容量。
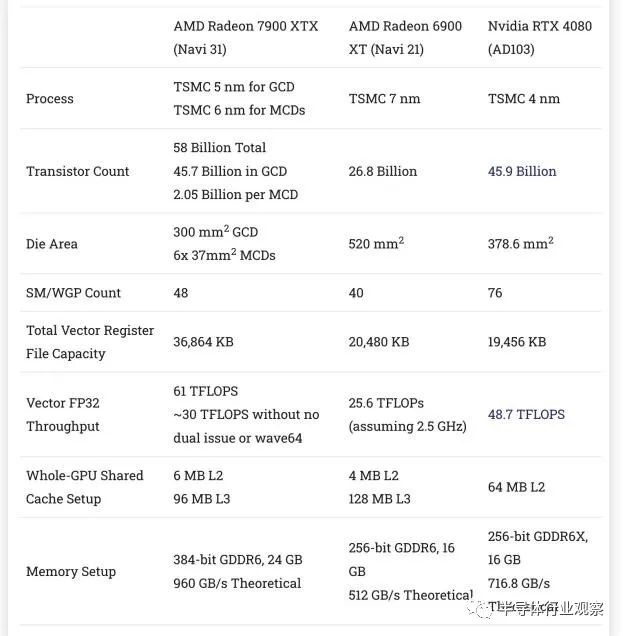
AMD 7900/6900與英偉達4080的比較(圖源:chipsandcheese)
英偉達的GPU目前做法還是將所有的晶體管,都放在一個更大的單芯片上,采用尖端工藝4納米節點。
而AMD的Navi 31基於Chiplet設計和先進的RDNA3架構。其裸片由GCD核(圖形計算芯片)和 MCD內存小芯片(內存緩存芯片)組成。
從下圖可以清晰的看到,中間部分是5nm制程的GCD核,周圍分別是6顆6nm制程的MCD,包含內存控制器和Infinity緩存。
這說明,著色器處理器和其他單元比較獲益於先進工藝,而對於內存控制器和緩存來說則不必需要使用最先進的工藝。

AMD Navi 31裸片(圖源:AMD)
兩種不同工藝的芯片組裝在一起,所使用的尺寸更小,與此同時,Chiplet的設計方式使得晶圓的缺陷芯片數量也少的多,從這個意義上來說,Chiplet架構的使用降低成本。
Chiplet的設計還助於通過在圖形芯片上使用更少的區域來實現VRAM連接,從而實現更高帶寬的 VRAM 設置。但是也不是萬利的,代價就是AMD必須支付更昂貴的封裝解決方案,因為簡單的封裝走線在處理GPU的高帶寬要求方面表現不佳。
此外,AMD Navi 31 GPU很重要的一項創新是Infinity Link總線,為何要說到這個呢?
因為Chiplet的設計方式肯定會產生更多的延遲,而GPU是對延遲極其敏感的,所以AMD特意為此開發全新的Infinity Link總線(即 Infinity Fanout Links 系統)來連接GDC和MCD部件,從而在GCD和MCD小芯片部件之間實現5.3 TB/s的帶寬,這種超級先進的互連系統無疑是小芯片GPU設計的關鍵決定因素。
可以說,AMD的Navi 31為圖形處理器世界帶來真正革命性的小芯片GPU設計,如果這一設計取得成功,那麼未來GPU就可以不用依賴先進工藝來提升性能,而是通過堆疊更多的GCD來實現。GPU市場迎來新的戰爭。
寫在最後
3D IC設計逐漸成為主流,Chiples也進一步崛起,在芯片大廠的推動下,基於Chiplet的3D IC設計進一步展示其說服力。Chiplet將徹底改變這個行業。
英偉達何時采用Chiplet,備受業界關註,不過估計也快,畢竟黃仁勛已指出,"Moore's Law is dead" 。