對於每一個看過漫威的人來說,鋼鐵俠的頭盔無疑是大傢都想擁有的一個裝備。透過這個頭盔,你可以一眼識別並標記出眼前所有的人和物品,並且看到這些事物獨特的數據和特點。而現在,Meta正在把這一科幻設想推向現實。
當最近巨頭們正在AIGC領域上激戰之時,Meta默默的在人工智能的另一個重要分支搞起大動作——計算機視覺。
本周三,Meta研究部門發佈一篇名為其“Segment Anything(分割一切)”的論文,文中介紹一個全新的Segment Anything Model(即SAM),可以用於識別圖像和視頻中的物體,甚至是人工智能從未被訓練過的物品。
所謂的“分割”,用最通俗的話來說就是摳圖。但Meta此次所展示的人工智能摳圖能力,可能遠比你想象的要更加強大,甚至在人工智能領域被認為是計算機視覺的“GPT-3時刻”。
01.圖片、視頻一鍵識別,哪裡喜歡點哪裡
雖然智能摳圖這件事並不算是個新鮮事物,但如果你嘗試過用P圖軟件來摳圖換背景,就會發現想把照片摳得快、摳得準、摳得自然其實是一件費時又費力的事。
從技術的角度來說,數字圖像的“摳圖”一直就是計算機視覺領域的一項經典且復雜的任務,其中關鍵的難點在於識別的時間和精準度。而Meta此次發佈的SAM可以說給出近乎完美的解決方案。
對於任何一張照片,Meta都可以快速識別照片中的所有物體,並智能地將其分割成不同的形狀和板塊。你可以點擊圖中的任意物品進行單獨處理。

此次SAM的一大突破還在於即使是在訓練過程中從未遇到過的物品和形狀,人工智能也能將其準確識別並分割出來。

而除簡單的識別圖片中的物品之外,此次SAM還支持用戶使用各種交互性的方式來分離出想要的物體。
比如你可以通過將鼠標懸浮在該物體之上,就能自動定位出物體的輪廓。即使是顏色非常相近或者有連人眼都很難快速分辨出的倒影的圖片之中,SAM都能非常準確的找出輪廓邊線。

再比如,你也可以直接通過輸入文字查詢,AI就可以幫你找到並標記出這個圖片中的你想找的這個文字對象。

不僅僅是靜態圖片,對於視頻中的物體,SAM也能準確識別並且還能快速標記出物品的種類、名字、大小,並自動用ID給這些物品進行記錄和分類。Meta表示未來這一技術會跟AR/AR頭顯進行廣泛結合。這聽上去是不是確實有點鋼鐵俠頭盔的味道?

看到這裡是不是已經覺得很厲害?別著急,Meta這次還有大招。
除能把物品從圖像中精準地分離出來,SAM還能支持對這個物品的編輯。也就是說,你可以把這個衣服從這個模特身上換下來,或許再換個顏色改個大小,放在另一模特身上。

你也可以把你從靜態圖片中“摳”出來的椅子,進行3D渲染和編輯,讓它從一個圖片立刻動起來,接著你還可以改變形狀或者進行更多的創意操作。

02.計算機視覺領域的 GPT-3 時刻,打開更大應用想象空間
Meta發佈SAM之後,立刻吸引大量關註,甚至在很多人工智能業內人士的眼中,SAM的出現可以說是計算機視覺領域的GPT-3時刻。
英偉達人工智能科學傢 Jim Fan 表示此次SAM最大的一點突破是它已經基本能夠理解“物品”的一般概念,即使對於未知對象、不熟悉的場景(例如水下和顯微鏡裡的細胞)它都能比較準確的理解。因此他表示相信SAM的出現會是在計算機視覺領域裡的GPT-3時刻。
不僅是Jim有這樣的觀點,一些AI研究專傢甚至也表示,SAM之於計算機視覺,就像是GPT之於大語言模型。

而就在SAM昨天發佈之後,很多人也在第一時間上手進行實測。矽星人瀏覽一圈,發現不僅基本滿屏都是驚嘆,一些網友還結合自身的工作領域打開SAM更廣的應用想象空間。
有人將包含眾多復雜元素的圖片上傳之後,SAM識別起來毫無壓力,無論是近景還是遠景,大量的復雜細微的元素都可以基本準確找出。

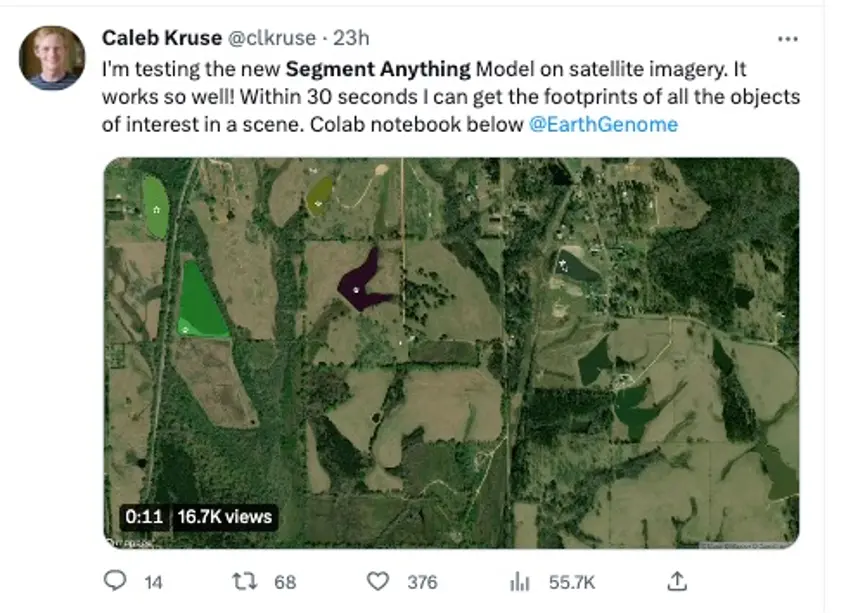
有自然科學研究者將SAM和衛星圖像結合在一起,表示SAM能夠很好的識別和找到他標記的風貌類型。
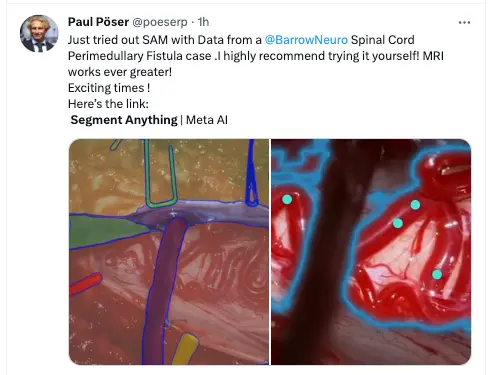
有神經外科影像學的專傢將SAM用到一個脊髓血管病的病例文件之中,認為SAM在幫助判斷和分析病情上有很大幫助。
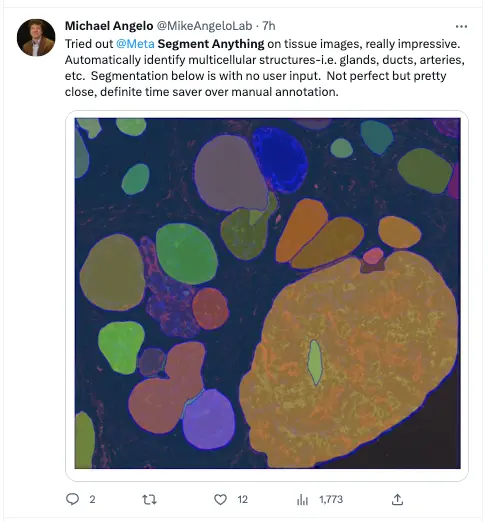
有生物學傢輸入一張顯微鏡下的組織圖片,即使圖中形狀特征毫無規律,但憑借著Zero-shot技術,SAM也能夠自動識別多細胞結構中的腺體、導管、動脈等。該生物學傢認為SAM的產出結果已經非常接近完美,未來能夠節省大量手動註釋的時間。
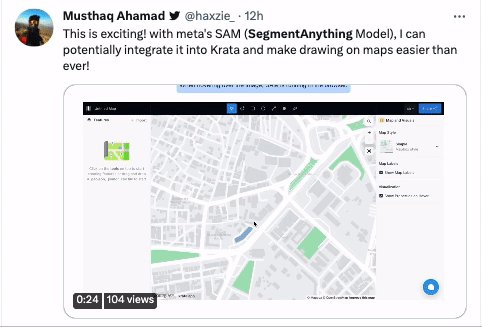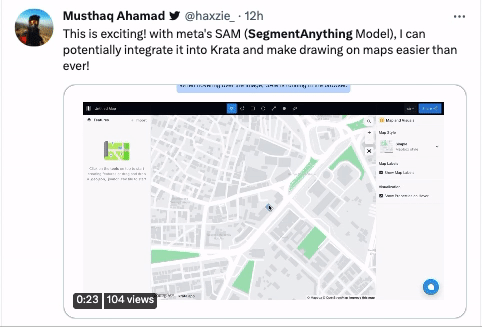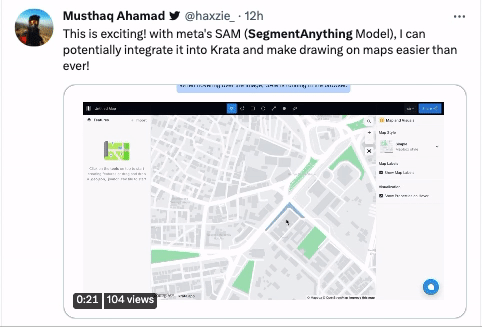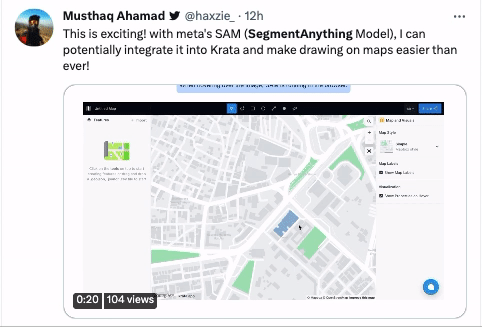
還有有騎行愛好者將地圖和SAM結合起來,認為能夠幫助自己未來更快更高效地給地圖做標記。
03.基於1100萬張照片訓練,模型和數據全部開源
總體來看,跟過去的一些計算機視覺模型相比,SAM 在幾個方面有著顯著的提升和不同。
首先,SAM 開創性地跟Prompt結合起來。它可以接受各種輸入提示,例如點擊、框選或指定想要分割的對象,這種輸入並不是一次性指令,你可以不停地對圖像下達不同的指令達到最終的編輯效果,這也意味著此前在自然語言處理的Prompt模式也開始被應用在計算機視覺領域。
此外,SAM基於1100 萬張圖像和 11 億個掩碼的海量數據集上進行訓練,這是迄今為止最大的分割數據集。該數據集涵蓋廣泛的對象和類別,例如動物、植物、車輛、傢具、食物等,這些圖像的分辨率達到1500×2250 pixels,平均每張圖像約有100個掩碼。此次SAM采用輕量級掩碼解碼器,可以在每次提示僅幾毫秒內在網絡瀏覽器中運行。
SAM 在各種分割任務上具有很強的零樣本性能。零樣本意味著 SAM 可以在不對特定任務或領域進行任何額外訓練或微調的情況下分割對象。例如,SAM 可以在沒有任何先驗知識或監督的情況下分割人臉、手、頭發、衣服和配飾。SAM 還可以以不同的方式分割對象,例如紅外圖像或深度圖等。
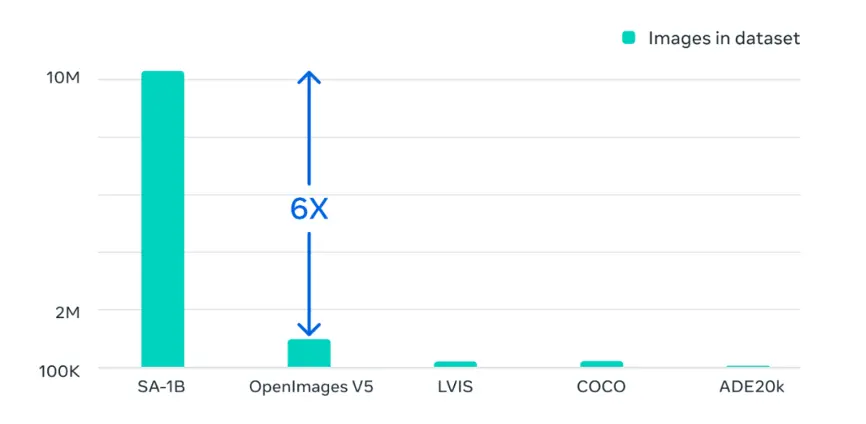
SAM的訓練數據集是OpenImage V5的6倍
Meta表示,目前公司內部已經開始使用SAM相關技術,用於在Facbook、Instagram等社交平臺上照片的標記、內容審核和內容推薦等。而之後,生成人工智能作為"創意輔助工具"也將被作為今年的重點優先事項被納入到Meta更多的應用程序中。
此次,可能最讓很多業內人士驚喜的地方在於,無論是SAM模型還是巨大的訓練數據集都是開源的!也就是說,目前任何人都可以在非商用許可下載和使用SAM及數據。
Meta表示,此舉是希望進一步加速整個行業對圖像分割以及更通用圖像與視頻理解的研究。‘Meta也預計,隨著SAM的演進和發展,該技術可能會成為未來AR/VR、內容創作、設計更多領域的強大的輔助工具。