百度搜索目前已經收錄小紅書網站上7億9807萬個網頁,谷歌則隻索引小紅書網站的首頁,為什麼呢?因為小紅書早已禁止所有搜索引擎抓取小紅書的內容。小紅書的robots.txt文件已經明確禁止所有搜索引擎抓取內容,不過藍點網檢索後發現實際上小紅書是在2023年4月2日修改robots.txt文件的,轉眼間這都修改1年。
目前並不清楚小紅書為什麼禁止搜索引擎抓取內容,從 SEO 角度來說,允許搜索引擎抓取有助於給小紅書帶來更多流量,畢竟現在百度都索引 7 億多個網頁。
而且小紅書是去年 4 月修改的,所以估計也不是因為防止被抓取內容訓練 AI 吧?但小紅書目前的內容庫拿去訓練 AI 確實很有價值,畢竟巨量文字和圖片內容。
不過 robots.txt 文件隻是君子協定,屬於防君子不妨小人的那種,除會導致用戶無法從搜索引擎直接查詢小紅書內容外,其實幫助也不大,畢竟其他非搜索引擎的爬蟲也會繼續抓取內容,小紅書肯定也做反爬措施。
現在國內的網站禁止搜索引擎抓取已經是個很常見的事情,或者專門預留一些層級目錄供搜索引擎抓取想要獲得一些流量,更有甚者甚至別說搜索引擎,就連正常的用戶訪問也會被攔截,必須註冊賬號登錄後才能繼續訪問,這顯然不是一個好事情。
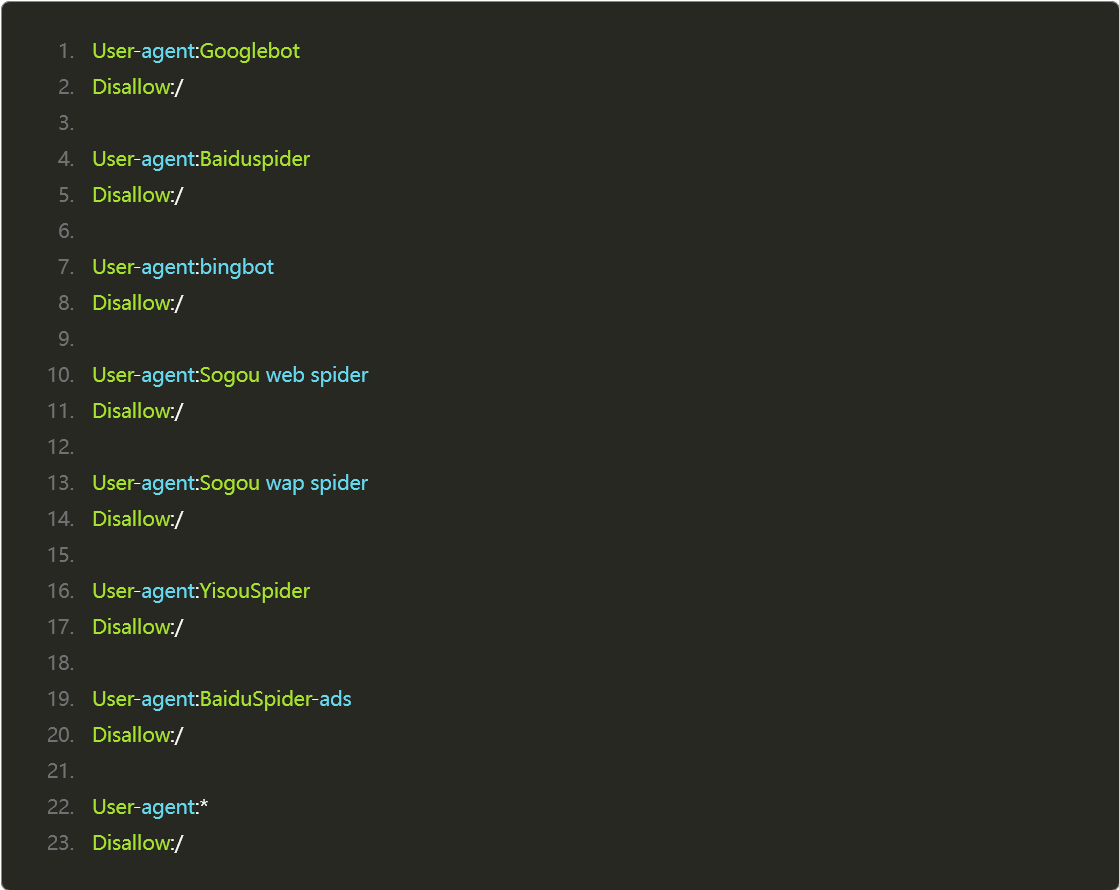
附小紅書 2023 年 4 月 2 日的 robots.txt 信息:
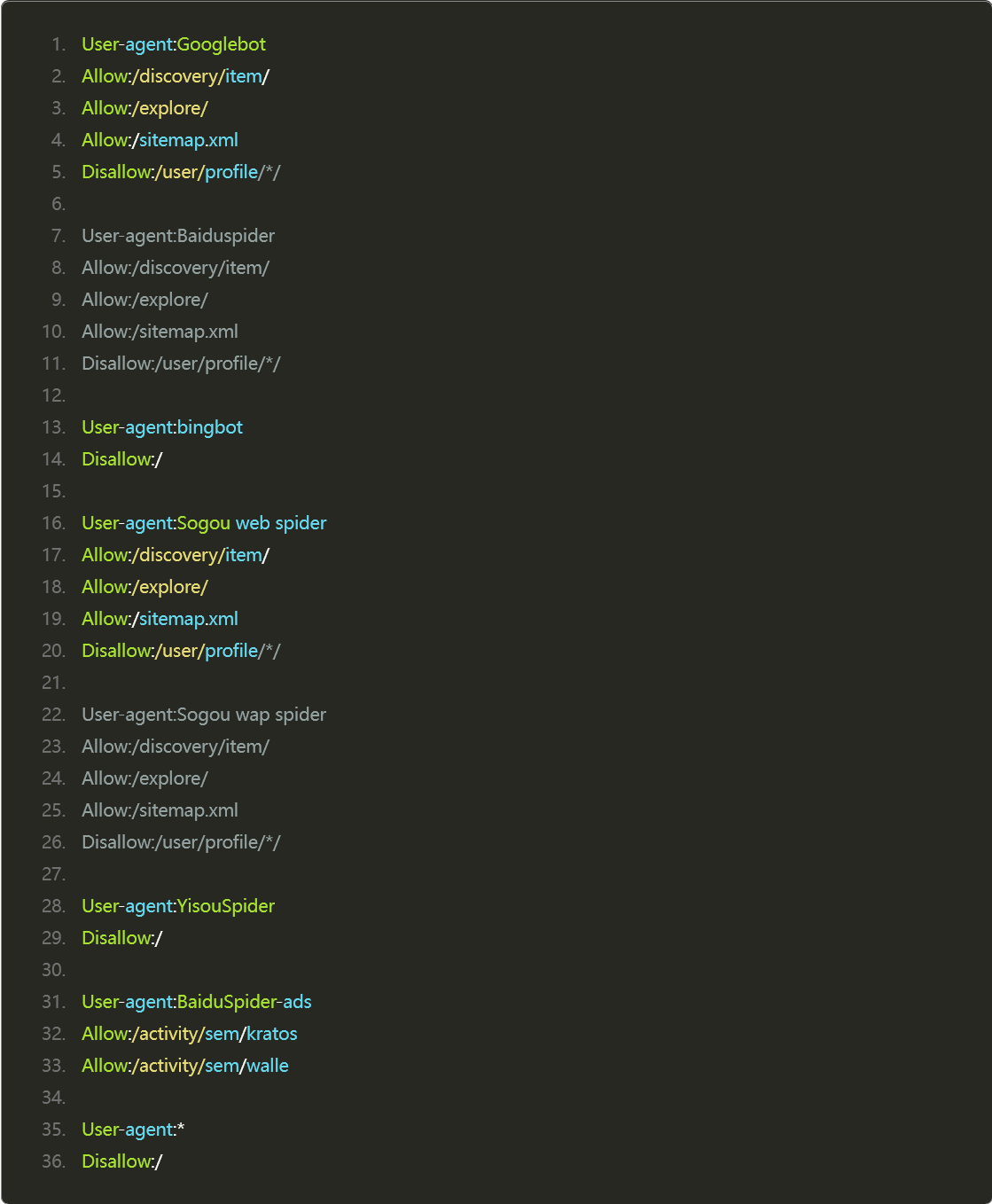
下面是小紅書最新的 robots.txt 信息: