當芯片制造商都在試圖將芯片往小設計時,而這傢公司卻反其道而行之。半導體初創公司CerebrasSystems公司周三(3月13日)推出一款新的芯片WSE-3,而它的尺寸卻類似晶圓大小,或者說比一本書還要大,單體面積達到約462.25平方厘米。它是目前最大GPU面積的56倍。
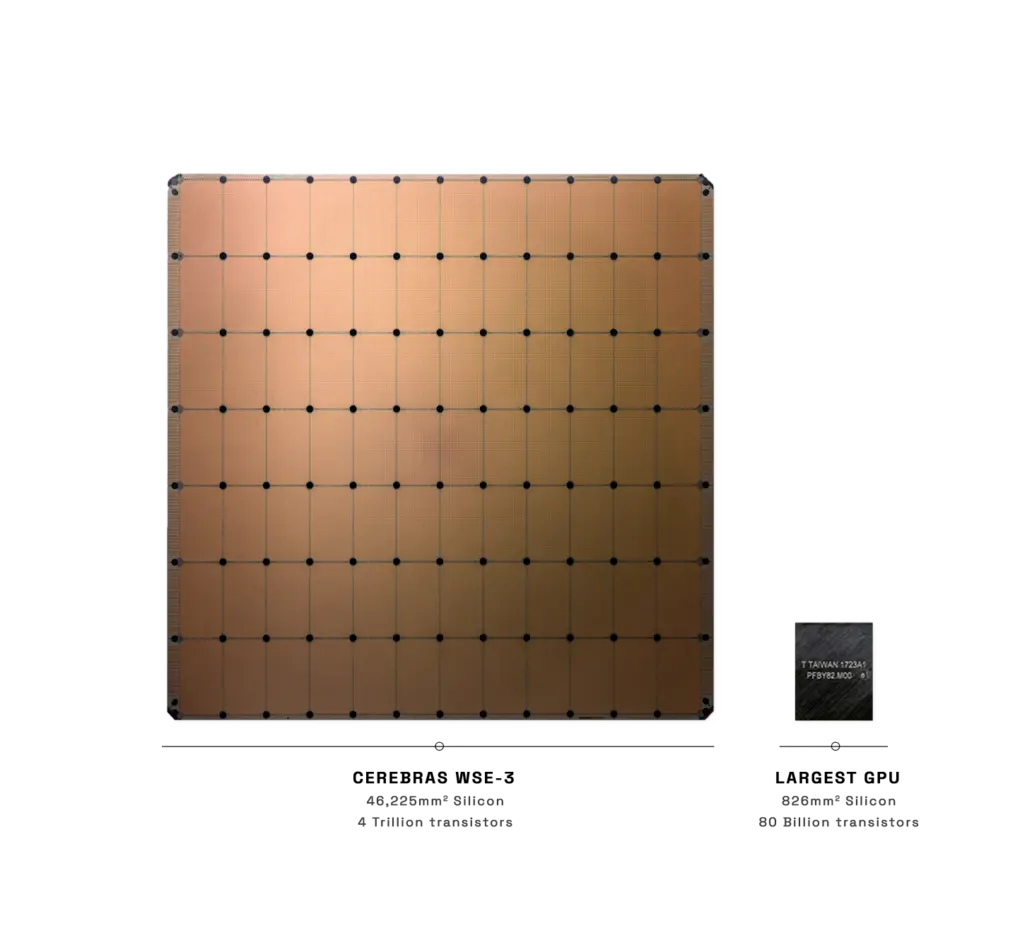
據悉,該款芯片將4萬億個晶體管組織在90萬個核心中。
該芯片針對人工智能訓練的工作負載進行優化。Cerebras公司聲稱,配備2048個WSE-3芯片的服務器集群可以在一天內訓練出市場上最先進的開源語言模型之一Llama 2 70B。
替代英偉達
Cerebras是一傢美國人工智能芯片的獨角獸企業,它背後的投資團隊也都實力夠硬。最新一筆融資是在2021年由Alpha Wave Venture和阿佈紮比增長基金領投,融資金額2.5億美元,其他的投資人士包括:OpenAI創始人山姆·奧特曼、AMD前首席技術官Fred Weber等。
2021年,Cerebras公司首次亮相WSE-2芯片,集成1.2萬億個晶體管、40萬個核心。在同行都在將晶圓分割成數百顆獨立芯片之時,Cerebras公司則是選擇將整個晶圓做成一顆芯片。
而最新發佈的WSE-3則是從WSE-2改進而來的。它較WES-2又增加1.4萬億個晶體管,並擁有90萬個計算核心、44GB的板載SRAM內存。強化部分是通過從7納米制造工藝更新到5納米節點所實現的。
據該公司稱,WSE-3在人工智能工作負載方面的性能是其前身的兩倍,它的峰值速度可以達到每秒125千萬億次計算。
Cerebras還將WSE-3定位為比英偉達顯卡更為高效的替代品。根據Cerebras官網的數據,該芯片4萬億個晶體管數完全碾壓英偉達H100 GPU的800億個;核處理器數是單個英偉達H100 GPU的52倍;片上存儲量是H100的880倍。

WSE-3芯片為Cerebras公司的CS-3超級計算機提供動力,CS-3可用於訓練具有多達24萬億個參數的人工智能模型,對比由WSE-2和其他常規人工智能處理器驅動的超級計算機,這一數據是個重大飛躍。
加速數據傳輸
雖說將晶圓大小的芯片和單個英偉達H100 GPU相比較並不公平,不過若從數據傳輸速度的角度來看,不將晶圓切割成單獨的芯片確實有它的優勢。
根據Cerebras公司的說法,使用單一的大型處理器可以提高人工智能訓練工作流程的效率。當WSE-3上的4萬億個晶體管在晶圓上互連時,將會大大加快生成式人工智能的處理時間。
人工智能模型就是相對簡單的代碼片段的集合,這些代碼片段被稱為人工神經元。這些神經元被重新組織成集合(稱為層)。當人工智能模型接收到一個新任務時,它的每一層都會執行任務的一部分,然後將其結果與其他層生成的數據結合起來。
由於神經網絡太大,無法在單個GPU上運行,因此,這些層需要分佈在數百個以上的GPU上,通過頻繁地交換數據來協調它們的工作。
基於神經網絡架構的具體特性,隻有獲得前一層的全部或部分激活數據,才能在開始分析數據,並提供給下一層。也就意味著,如果這兩層的數據運行在不同的GPU上,信息在它們之間傳輸可能需要很長時間。芯片之間的物理距離越大,數據從一個GPU轉移到另一個GPU所需的時間就越長,這會減慢處理速度。
而Cerebras的WSE-3有望縮短這一處理時間。如果一個人工智能模型的所有層都在一個處理器上運行,那麼數據隻需要從芯片的一個角落傳輸到另一個角落,而不是在兩個顯卡之間傳輸。減少數據必須覆蓋的距離可以減少傳輸時間,從而加快處理速度。
該公司指出,在如今的服務器集群中,數以萬計的GPU被用來處理一個問題,而若是將芯片數量減少50倍以上,就可以降低互連成本以及功效,同時或許也可以解決消耗大量電力的問題。
Cerebras聯合創始人兼CEO Andrew Feldman稱,“當我們八年前開始這一旅程時,每個人都說晶圓級處理器是白日夢…WSE-3是世界上最快的人工智能芯片,專為最新的尖端人工智能工作而打造。”
對於新推出地WSE-3芯片,分析公司Intersect360 Research首席執行官Addison Snell認為,Cerebras的WSE-3人工智能芯片和CS-3系統可以使部分高性能計算用戶受益。
他指出,“該芯片在相同的成本和功率下將性能提高一倍。”
不過,Tirias Research創始人Jim McGregor則較為現實地指出,盡管這傢初創公司增長迅速,並且有能力提高其平臺的可擴展性,但與占主導地位的人工智能供應商英偉達相比,它仍然是一傢規模較小的公司。
他還指出,Cerebras專註於人工智能的一個方面,那就是訓練,不過訓練隻是大型語言模型市場的一個利基市場。而英偉達提供許多其他方面產品。