使用MetalAPI的應用程序和遊戲以AppleSiliconGPU的特定功能為目標,M3和A17Pro的並行處理能力得到顯著提升,使其性能更上一層樓。蘋果公司發佈關於這些新的AppleSiliconGPU功能的開發者講座,詳細介紹實現改進效果的具體過程。該視頻介紹大量技術細節,但也提供足夠的基本解釋。

使用 Metal API 構建應用程序的開發者無需對其應用程序做任何修改,就能看到 M3 和 A17 Pro 的性能提升。這些芯片組利用動態緩存、硬件加速光線追蹤和硬件加速網格映射技術,使 GPU 的性能空前提高。
動態著色器核心內存
新一代著色器核心讓動態緩存成為可能。利用 A17 Pro 和 M3 中的最新 GPU 內核,這些著色器可以比以前更高效地並行運行,從而大幅提高輸出性能。

虛線表示浪費的寄存器內存
通常情況下,GPU 隻能根據一個已執行動作中帶寬最高的進程來分配寄存器內存,並持續該動作。因此,如果一個動作的某個部分比其他部分需要更多的寄存器內存,那麼該動作的某個進程就會占用更多的寄存器內存。
動態高速緩存允許 GPU 為其正在執行的每個操作精確分配適量的寄存器內存。以前不可用的寄存器內存被釋放出來,從而可以並行執行更多的著色器任務。
靈活的片上內存
以前,片上內存會為寄存器、線程組和帶有緩沖緩存的磁貼內存分配固定的內存。這意味著,如果某項操作使用的內存類型多於另一種,就會有很大一部分內存被閑置。
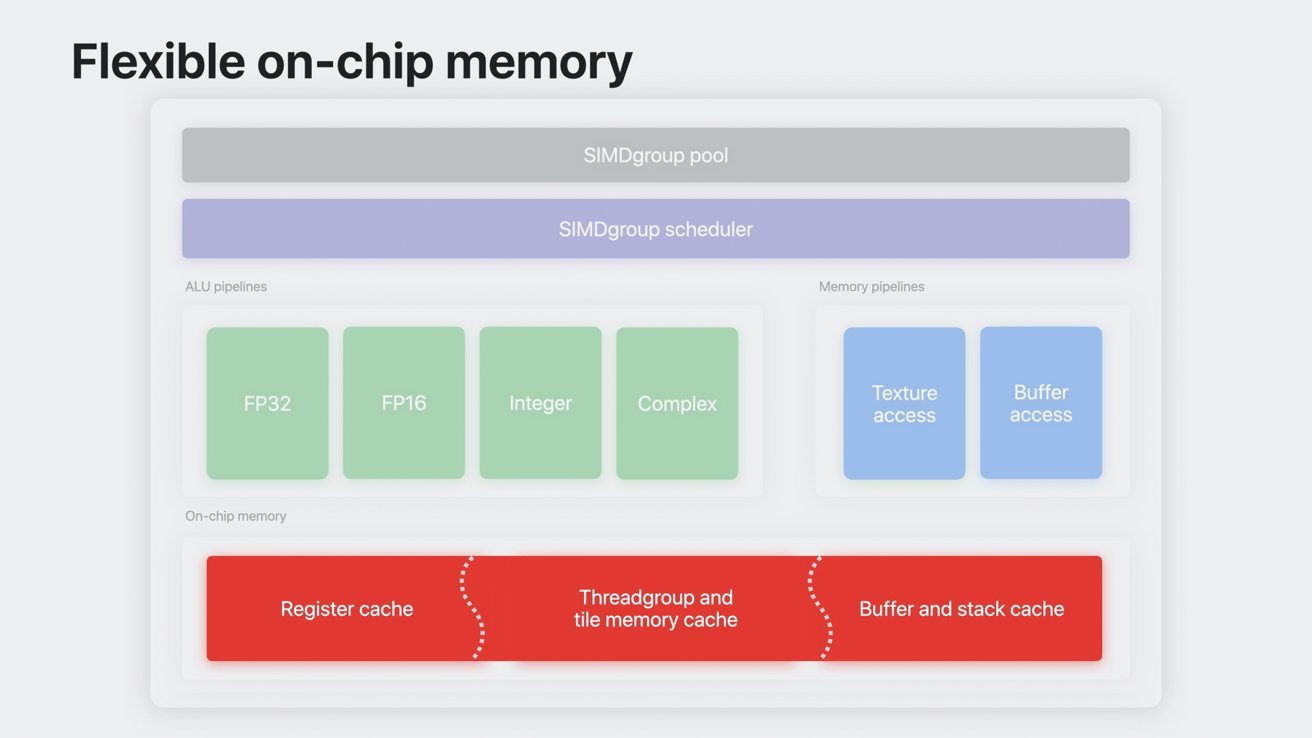
整個芯片內存都可用作高速緩存
有靈活的片上內存,所有片上內存都是緩存,可用於任何內存類型。因此,嚴重依賴線程組內存的操作可以利用整個片上內存,甚至溢出到主內存中。
著色器內核可動態調整片上內存占用率,以最大限度地提高性能。這意味著開發人員可以花更少的時間來優化占用率。
著色器內核的高性能 ALU 管線
Apple 建議開發人員在程序中執行 FP16 數學運算,但高性能 ALU 可並行執行整數、FP32 和 FP16 的不同組合。指令在並行執行的不同操作中執行,這意味著 ALU 利用率會隨著占用率的提高而提高。

利用高性能 ALU 流水線增加並行操作
基本上,如果不同的操作包含相同的 FP32 或 FP16 指令,而這些指令將在不同的時間點執行,則可以重疊執行以提高並行性。
硬件加速圖形流水線
硬件加速的光線追蹤可將重要的交點計算從 GPU 功能中移除,從而大大加快處理速度。由於部分計算由硬件完成,因此可以並行進行更多操作,從而通過硬件組件加速光線追蹤。
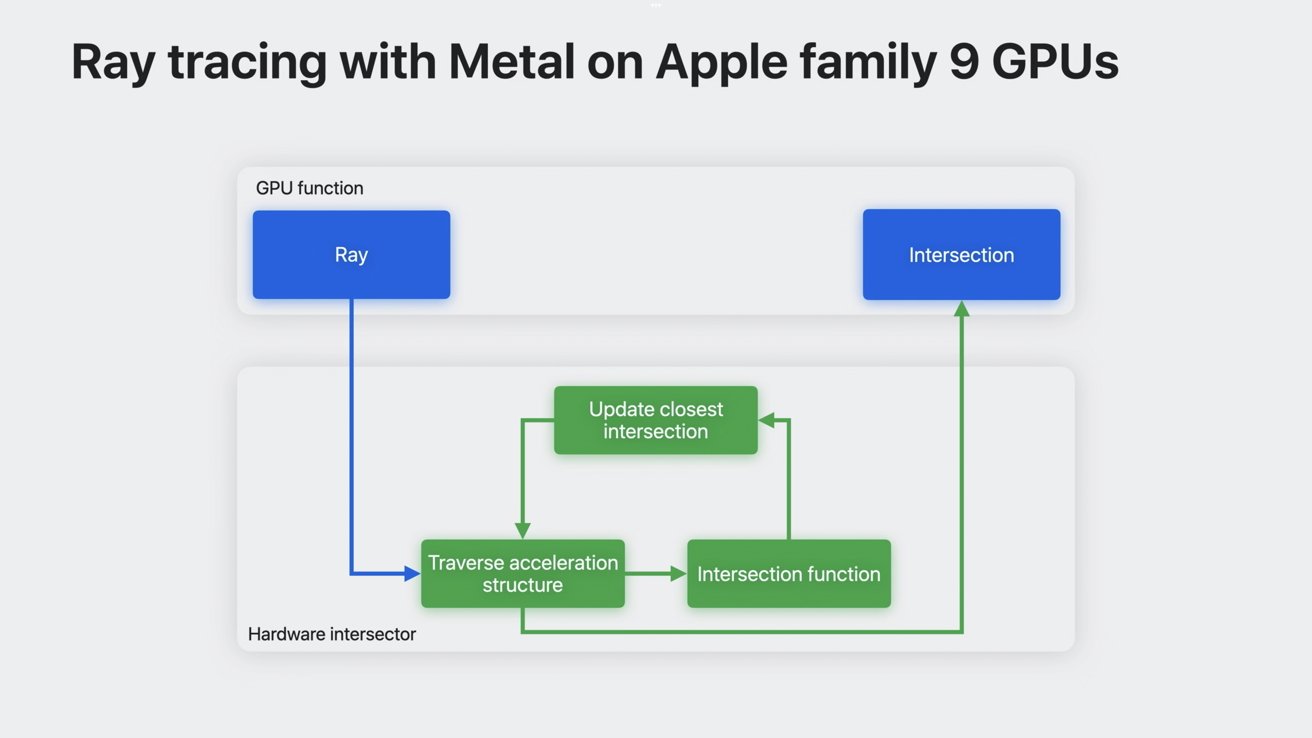
硬件加速取代片上進程
硬件加速網格著色采用類似的方法。它將幾何計算流水線的中間部分交給一個專用單元,從而實現更多並行操作。
這些都是復雜的系統,不是幾段文字就能說清楚的。我們建議大傢觀看視頻《Explore GPU advancements in M3 and A17 Pro》解所有細節,並牢記一點--A17 Pro 和 M3 專註於計算並行性,以加快任務執行速度。
https://developer.apple.com/videos/play/tech-talks/111375?time=39
M3 可用於 MacBook Pro 和 24 英寸 iMac。A17 Pro 可用於 iPhone 15 Pro。