ChatGPT到底有多會修bug?這事終於有人正兒八經地搞研究——來自德國、英國的研究人員,專門搭個“擂臺”來檢驗ChatGPT的這項本領。除ChatGPT之外,研究人員還找來其它三位修bug的“AI猛將”,分別讓它們修復40個錯誤代碼。結果真是不比不知道,一比嚇一跳。

ChatGPT準確修復其中31個bug,遙遙領先第二名(21個),直接拿下“AI修bug界”的SOTA成績!

於是乎,這項研究引來眾多網友的圍觀和討論,Reddit上發佈此帖的標題更是用上“小心”、“註意”這樣的字眼:

但事實上,這真的會讓程序員“危”嗎?
我們不妨先來看下這項研究。
很會修bug的ChatGPT
雖然ChatGPT並非是為專門修改bug而生,但自打它問世以來,不少網友們都發現它是具備這項能力的。
因此研究人員為摸清ChatGPT到底能修改bug到什麼程度,便引入標準的錯誤修復基準集QuixBugs來進行評估。
以及與它同臺競技的AI選手,分別是CodeX、CoCoNut和Standard APR。
研究人員從QuixBugs中挑40個問題,分別讓它們來修復bug。
讓ChatGPT來修bug的方法,就是在對話框裡向它提問:
這個代碼有什麼錯誤嗎?
在第一輪較量過後,結果如下:
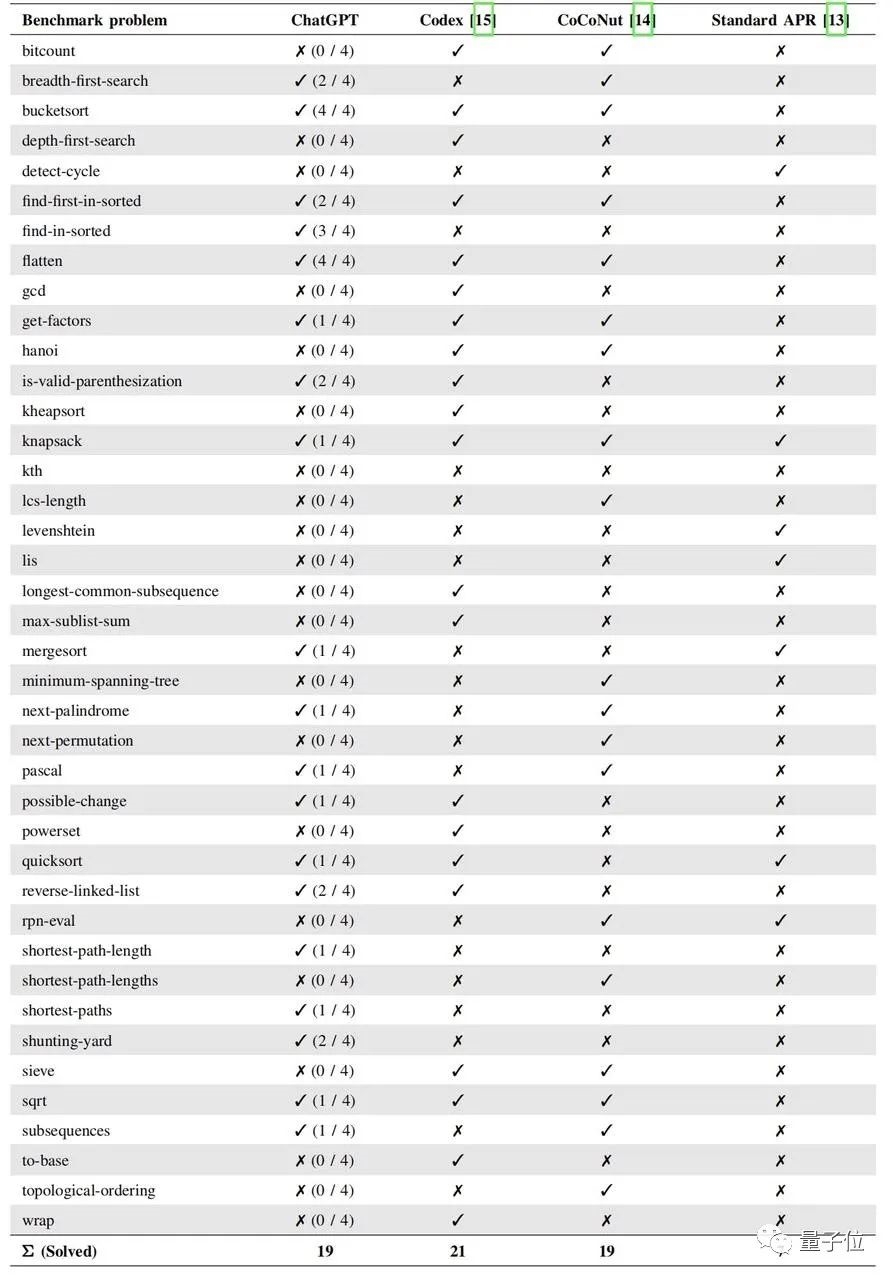
從第一輪battle結果來看,ChatGPT修復19個,CodeX修復21個,CoCoNut修復19個,Standard APR則是7個。
而且研究人員還發現,ChatGPT的答案與CodeX最為相似;這是因為它倆是來自同一個語言模型傢族。
這時候就會有小夥伴要問,“ChatGPT不是還沒有CodeX厲害嗎”。
別急,不要忘,ChatGPT的一個特點就是越問越“上道”。
例如在這個基準集中,有一個叫bitcount的問題,ChatGPT在剛才第一輪修復過程中是給錯誤的答案:

原本ChatGPT應該將第7行的 n ^ = n - 1 改為 n & = n - 1。
但在第一輪中它的回答是:
如果沒有更多關於預期行為和導致問題的輸入信息,我無法判斷程序是否存在錯誤。
於是在給予它更多信息之後,ChatGPT便答對這個問題。
以此類推,在對第一輪沒答對的問題進行更多信息提示之後,ChatGPT的修bug能力有大幅提高:

最終,ChatGPT在QuixBugs的40個問題裡答對31個。
網友憂喜參半
對於這樣的實驗結果,網友們對ChatGPT修bug拿下SOTA這事產生的態度卻不太一樣。
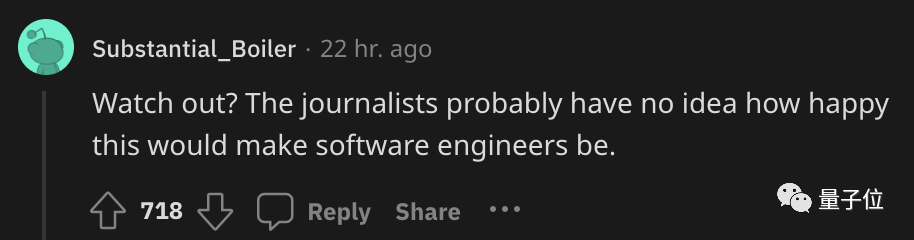
有網友認為這事不應該讓程序員感到危機,而是會讓他們覺得開心才對。
言外之意,便是程序員們有這麼好用的工具,幹活兒就會變得事半功倍。
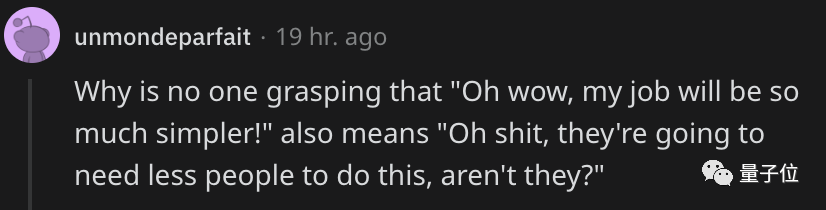
不過也有人對此給出不一樣的看法:
工作變得簡單,不也就意味著需要的人力更少嗎?
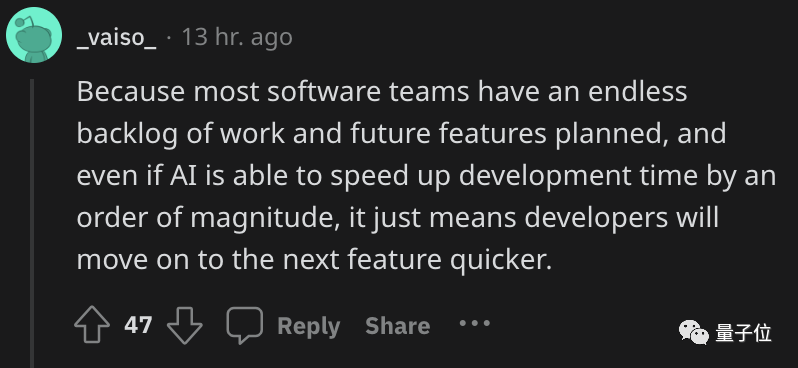
但還網友覺得,活兒是幹不完的:
即使AI能把開發時間縮短一個數量級,也隻是意味著程序員將更快處理下一個工作。
整體來看,ChatGPT很會修bug,並不會給程序員帶來什麼致命傷害。
但若是把目光放到OpenAI其他的行動中呢?
全球招外包訓練ChatGPT寫代碼
在此之前,OpenAI就表示過ChatGPT的重要用途之一是幫助程序員檢查代碼。
換言之,它被定位可用的輔助工具。
相比“ChatGPT帶來威脅”的看法,等ChatGPT能力徹底進化,程序員都不用再怕寫bug。
OpenAI佈局的棋盤上,可不隻有改bug偷塔程序員崗位這一件事。
為讓它更大更強,OpenAI被曝在拉美和東歐等地區,提供1000個外包崗位。
外包員工的主要工作是標註數據,以及訓練ChatGPT寫代碼
這1000人中,40%是程序員,他們為OpenAI的模型創建數據,用來學習軟件工程任務。
一直以來,OpenAI的訓練數據是從GitHub上抓取的。
現在外包程序員們新手搓的數據集,不僅包括代碼行,還包括代碼行背後的人類思考邏輯步驟。
有位南美的軟件開發人員爆料,他為OpenAI完成五小時的無償編碼測試。
整個過程中,他的任務分為兩部分。
用書面英語解釋如何處理一個編碼問題;
提供解決方案。
如果發現bug,OpenAI會向他詳細詢問bug的具體情況,並請教如何修正。
程序員需要展示思考問題的每個步驟,他據此猜測OpenAI很可能想為ChatGPT提供非常具體的訓練數據。
特斯拉前AI主管Andrej Karpathy在推特上調侃:
最新的熱門編程語言是英語。
不過話說回來,ChatGPT修bug能力強是好事,要真能搞進化到可以完成代碼裡死記硬背的部分,也是好事。
畢竟OpenAI成立時對外宣稱的宗旨,就是希望“確保通用人工智能可以造福全人類”。
雖然乍一看它這些年做的事,有點像在致力於用一部分人的努力,讓更多人失業。
從Dota2賽場上碾壓人類,到GPT-3、DALL-E2、ChatGPT的閃耀表現,它帶來的新產品總是伴隨著“快要讓xxx失業”的議論聲。
但無論如何,商業卻一直對它青睞有加。
就目前而言,OpenAI的主要商業模式是API費用、token費用和軟件許可。
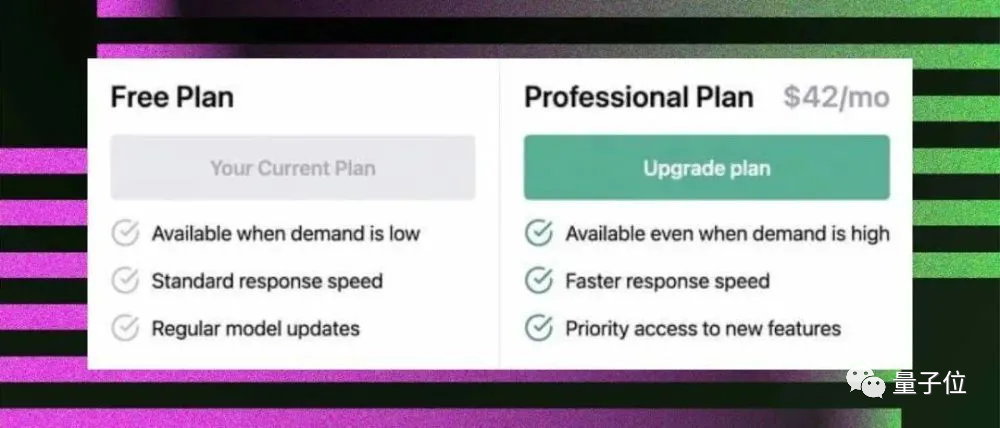
OpenAI近期還發佈ChatGPT的付費版ChatGPT Pro,每月費用42美元(約合285元人民幣)。
雖然機器人對話初創公司如雨後春筍般冒出,但諸多跡象表明市場對OpenAI的持續看好。
微軟剛剛宣佈將向OpenAI加碼投資數十億美元,並將OpenAI的模型融入微軟必應等消費級和企業級產品中。
根據知情人士透露,此次追加投資數額約為100億美元。
與此同時,WSJ披露的消息顯示,1月初,億萬富翁Peter Thiel創立的風投基金Founders Fund正在就投資OpenAI進行談判。
據悉,融資金額將至少達3億美元。
One More Thing
在第一輪實驗中,ChatGPT並沒有解決QuixBugs數據集的bitcount問題。
但若是你現在再重頭問一次這個問題,就會發現ChatGPT可以“一遍過”:

那麼這是否意味著ChatGPT已經從這次研究過程中學會求解呢?