ChatGPT的下一個新身份——做題傢!這不,它已經在人類各個考試中開“卷”。律師、醫生、註會什麼的,它都開始紛紛展露身手。比如,全球考生都頭疼的司法考試,現在ChatGPT在兩項試題達到合格率,其中一項還跟人類水平持平。(還是在沒有任何微調的基礎上)

“成績”一出,瞬間引發巨大關註,網友:Amazing~

還有人表示,要是讓它來參加SAT或AP考試,應該會很有趣。
咳咳,要是公務員考試呢?
咱們結尾見分曉!
兩項法考試題合格
具體就先來看看ChatGPT在司法考試中的表現如何。
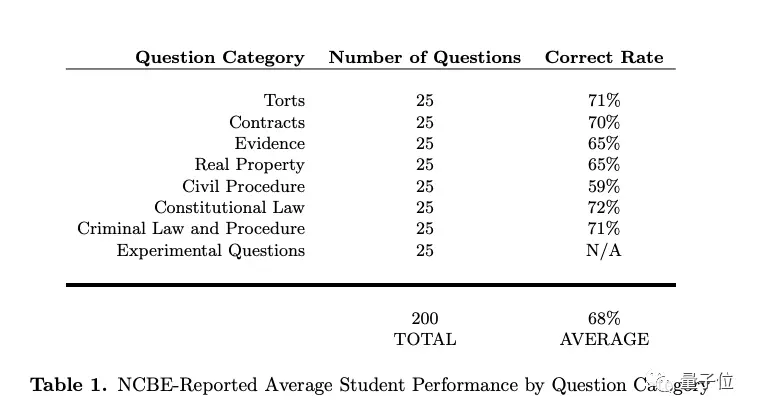
美國大多數州統一的司法考試(UBE),有三個組成部分:選擇題(多州律師考試,MBE)、作文(MEE)、情景表現(MPT)。
選擇題部分,由來自8個類別的200道題組成,通常占整個律師考試分數的50%。
在這項研究中,研究人員對OpenAI的text-davinci-003模型(通常被稱為GPT-3.5)在MBE的表現進行評估。
(ChatGPT正是GPT-3.5面向公眾的聊天機器人版本。)
為測試實際效果,研究人員購買官方組織提供的標準考試準備材料,包括練習題和模擬考試。每個問題的正文都是自動提取的,其中有四個多選選項,並與答案分開存儲,答案僅由每個問題的正確字母答案組成,也沒有對正確和錯誤的答案進行解釋。
隨後,研究人員分別對GPT-3.5進行提示工程、超參數優化以及微調的嘗試。結果發現,超參數優化和提示工程對GPT-3.5的成績表現有積極影響,而微調沒有任何效果。
在提示工程中,他們共測試7種提示類型。
1、隻做單項選擇;
2、單項選擇和解釋;
3、隻做前兩個選擇;
4、前兩個選擇和解釋;
5、前兩個選擇和重新提示;
6、對所有選擇進行排序;
7、對前三個選擇進行排序。

研究人員在上述的提示和參數值中執行107次樣本考試。結果在這些提示中,提示風格#7的前三個選項排序表現最好,他們共收集41個樣本,對這個提示進行參數組合。
超參數優化中,他們評估包括溫度系數、top p、best of、max tokens等參數。
最終在完整的MBE練習考試中達到50.3%的平均正確率,大大超過25%的基線猜測率,並且在證據和侵權行為兩個類型都達到平均通過率。尤其是證據類別,與人類水平持平,保持著63%的準確率。
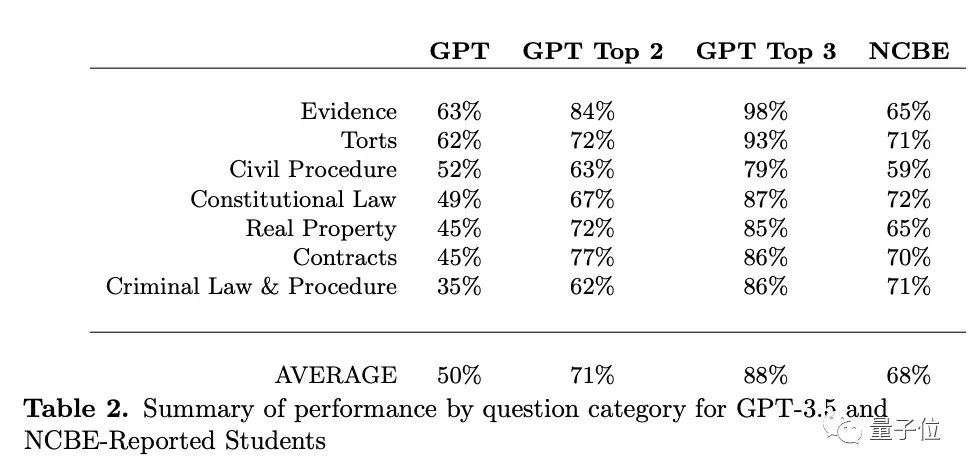
在所有類別中,GPT平均落後於人類應試者約17%。在證據、侵權行為和民事訴訟的情況下,這一差距可以忽略不計或隻有個位數。
但總的來說,這一結果都大大超出研究人員的預期。
因為它對答案排序與正確性有很強的相關性,Top2和Top3的選擇分別有71%和88%的正確率。其中“Top2”的準確率全都超過極限,有五個類別均超過人類平均水平。而“Top3”的準確度更高,在證據這一表現中甚至達到98%。
這也證實它對法律領域的一般理解,而非隨機猜測。接下來他們將進一步對法考的其他兩部分:作文和情景表現進行上述的研究。
ChatGPT能當考霸嗎?
Google資深軟件工程師肯尼斯·古德曼(Kenneth S. Goodman)就拿ChatGPT做一系列測試,涉及司法、醫學、會計學、化學等多個領域。
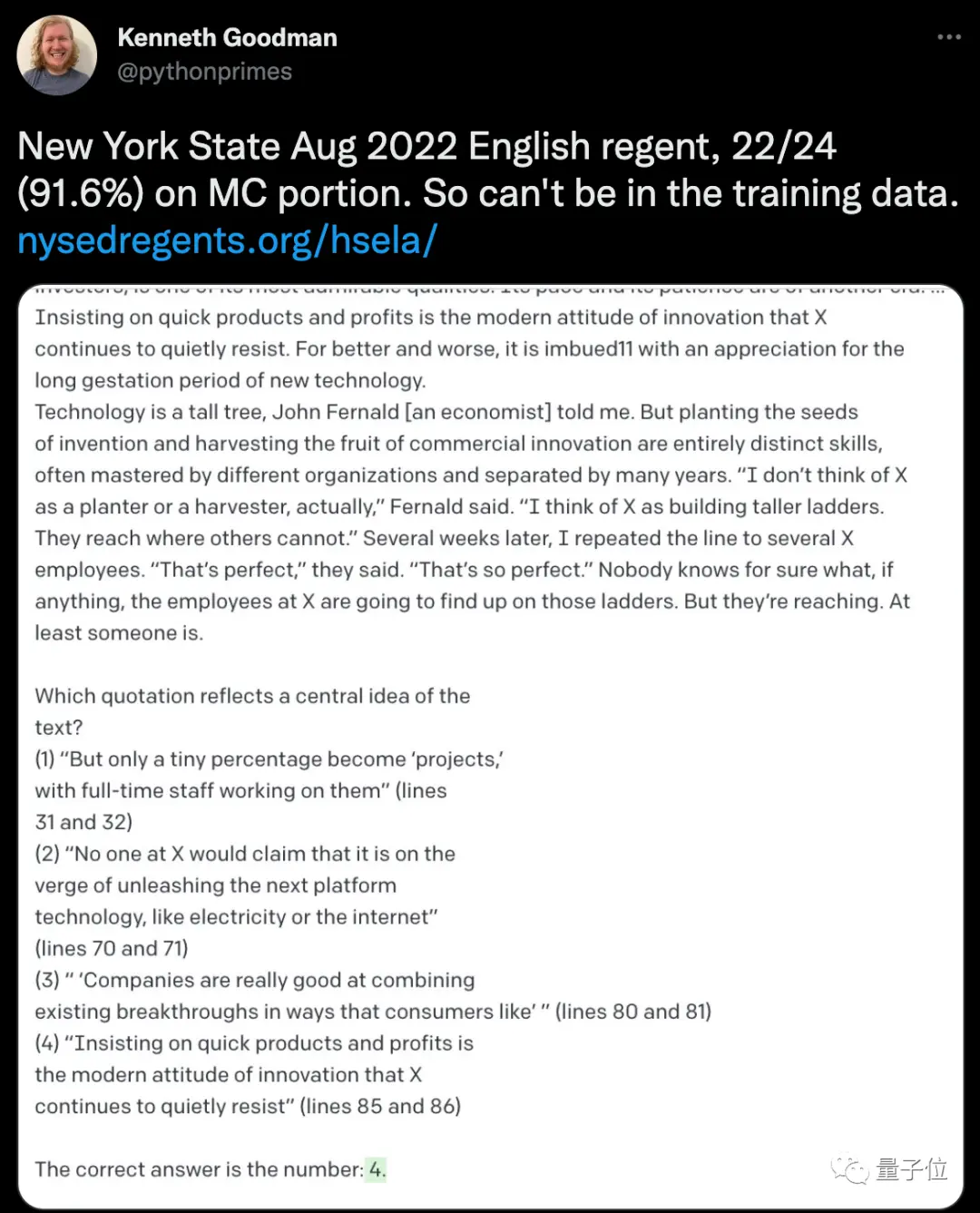
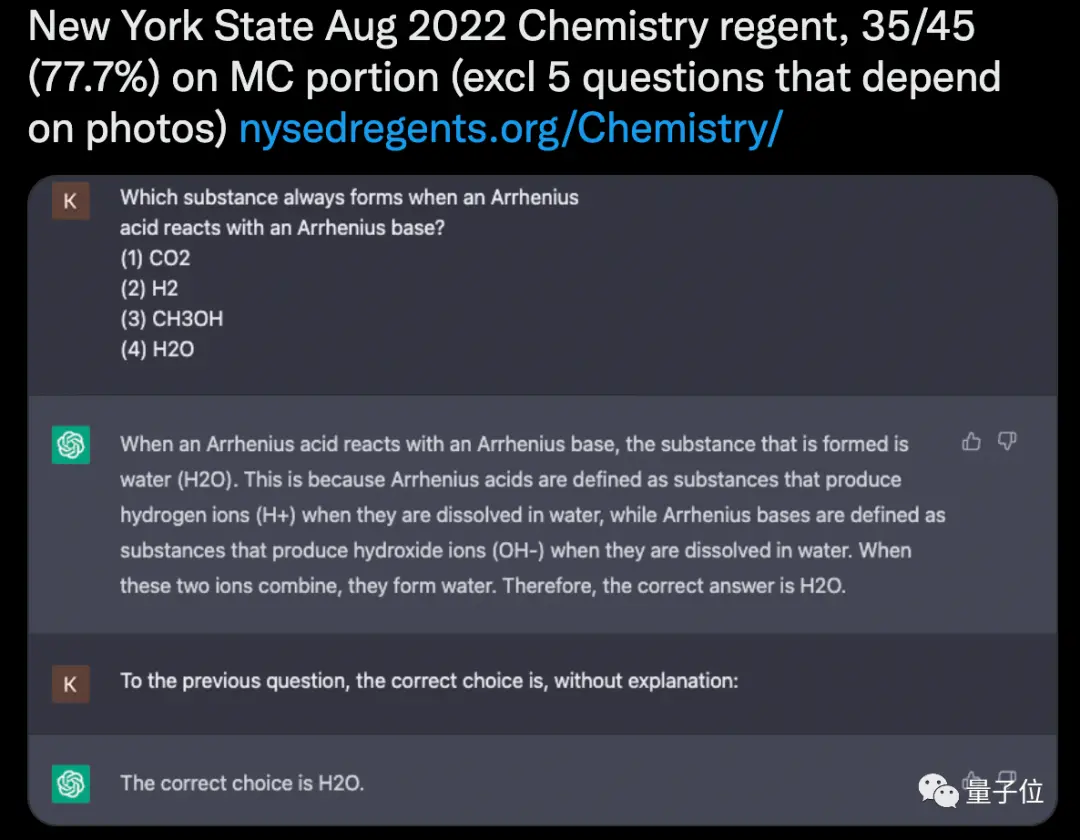
分數最高的一門是紐約州高中畢業英語語言藝術考試,ChatGPT正確率達到91.6%。
因為是2022年8月的考試,所以ChatGPT數據庫中肯定不包含考試內容。對於陌生的24道考題,它隻錯2題。
物理/化學考試中,ChatGPT的表現也不錯,正確率達到77.7%,45道題目中答對35道。
前不久,Google醫療大模型Med-PaLM通過美國醫師執照試題(USMLE)驗證。
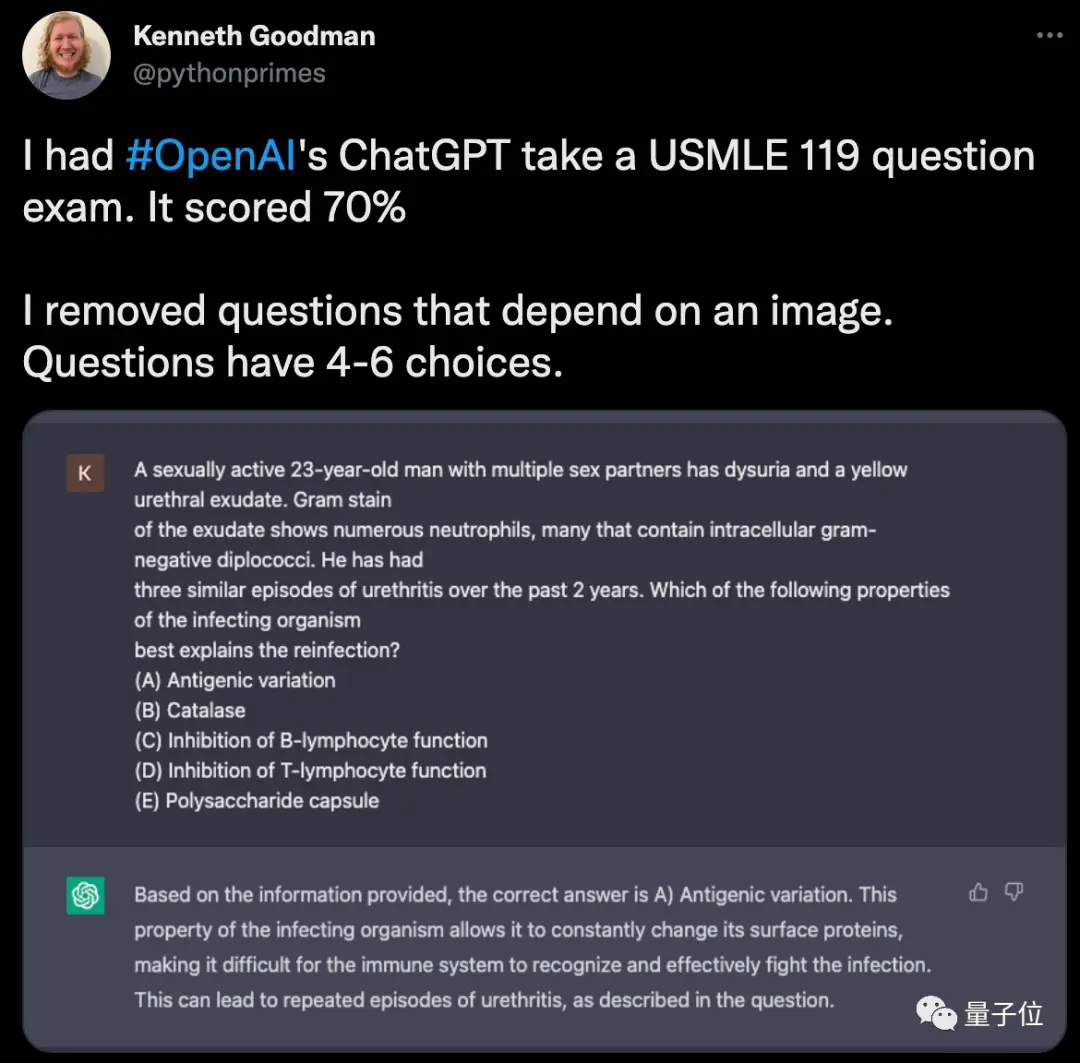
ChatGPT也不甘於落後,同樣挑戰USMLE的第一階段基礎醫學考試。
去掉有圖像的題目後(因無法輸入對話框),ChatGPT正確率達70%。
其餘則是在司法方面,工程師肯尼斯老哥讓ChatGPT嘗試一些非正式題目。
比如美國律師職業道德考試(MPRE)的示例題目(共15道),ChatGPT答對9道,正確率60%。
面對50道律師資格考試模擬試題,ChatGPT的正確率也維持在70%,答對35道。
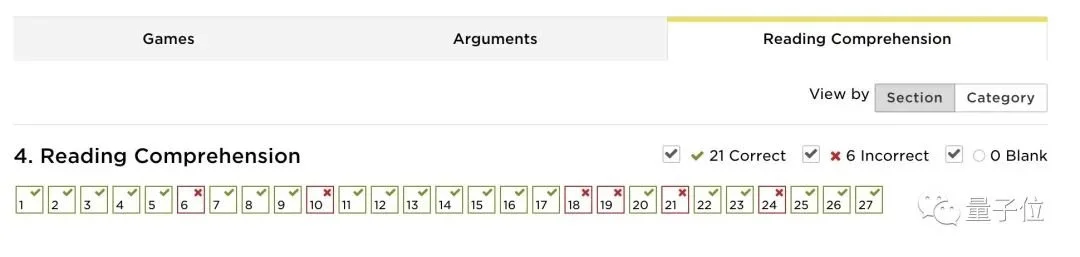
此外,在佛羅裡達農工大學法學院的入學考試中,ChatGPT取得149分,排名在前40%。其中閱讀理解類題目表現最好。
表現最差的,還是數學題。
在CPA註會考試中,ChatGPT的正確率隻有40%。肯尼斯老哥還在嘗試一些調教方法,讓它更聰明一些。

總之,ChatGPT在各種考試中的表現,還是讓人有些意外。
有網友已經產生危機感:
damn,我的工作要被搶!

有人分析,如果直接讓AI來插手司法相關的判斷,風險真的很大,但如果後期有專人來審核它的輸出結果,那麼AI將能夠很好提升律師的工作效率。

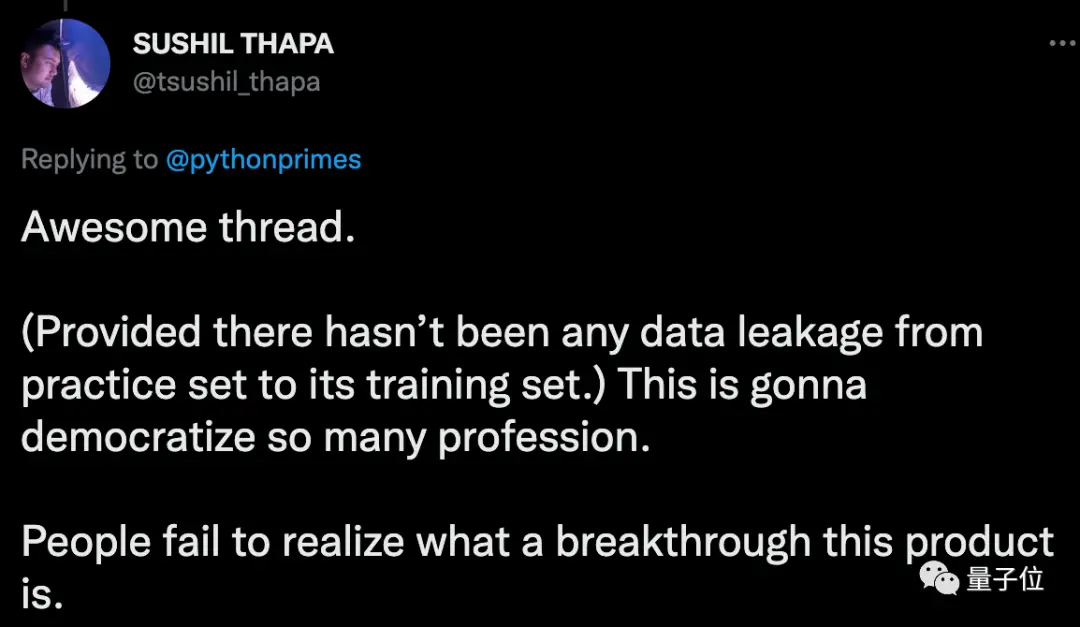
還有人表示,如果能保證任何數據都不泄露的話,那ChatGPT將能夠推動更多行業平民化。
或許正如肯尼斯老哥說的那樣,人類+電腦的組合已經超越人類自身能力,這就是計算機當下正在進行的突破。

One More Thing
最後,我們也讓ChatGPT試試國內法考的題目~
先說結果,3道選擇題,ChatGPT都沒有答對……雖然解釋得頭頭是道,但它應該確實沒有讀過我國的法條。

參考答案D
這答案羅翔老師看直搖頭

參考答案A
換成公務員行測試題呢?沒想到ChatGPT的答案對,可是過程和答案似乎完全沒關系……

這……怎麼感覺AI秒算結果,但隨便編個過程來糊弄人類啊!