三十年前,CPU和其他專用處理器幾乎處理所有計算任務。那個時代的顯卡有助於加快Windows和應用程序中2D形狀的繪制速度,但沒有其他用途。快進到今天,GPU已經成為業界最具主導地位的芯片之一。
但具有諷刺意味的是,圖形芯片的唯一功能是圖形的日子已經一去不復返,機器學習和高性能計算嚴重依賴於不起眼的 GPU 的處理能力。與我們一起探索這款單芯片如何從一個不起眼的像素推動器演變成一個強大的浮點計算引擎。

一開始,CPU統治一切
讓我們回到 20 世紀 90 年代末。高性能計算領域,包括超級計算機的科學工作、標準服務器上的數據處理以及工作站上的工程和設計任務,完全依賴於兩種類型的 CPU:1)專為單一目的而設計的專用處理器,2)來自AMD、IBM 或 Intel 的現成芯片。
ASCI Red 超級計算機是 1997 年左右最強大的超級計算機之一,由 9,632 個 Intel Pentium II Overdrive CPU 組成(如下圖所示)。每個單元的運行頻率為 333 MHz,該系統的理論峰值計算性能略高於 3.2 TFLOPS(每秒萬億次浮點運算)。

由於我們將在本文中經常提到 TFLOPS,因此值得花點時間來解釋它的含義。在計算機科學中,浮點數(或簡稱floats )是表示非整數值的數據值,例如 6.2815 或 0.0044。整數值(稱為整數)經常用於控制計算機及其上運行的任何軟件所需的計算。
浮點數對於精度至關重要的情況至關重要,特別是與科學或工程相關的任何事情。即使是簡單的計算,例如確定圓的周長,也至少涉及一個浮點值。
幾十年來,CPU 一直擁有單獨的電路來對整數和浮點數執行邏輯運算。在上述 Pentium II Overdrive 的情況下,它可以在每個時鐘周期執行一次基本浮點運算(乘法或加法)。理論上,這就是為什麼 ASCI Red 的峰值浮點性能為 9,632 個 CPU x 3.33 億個時鐘周期 x 1 次操作/周期 = 3,207,456 百萬次 FLOPS。
這些數字基於理想條件(例如,對適合緩存的數據使用最簡單的指令),並且在現實生活中很少可以實現。然而,它們很好地表明系統的潛在能力。

其他超級計算機也擁有類似數量的標準處理器——勞倫斯利弗莫爾國傢實驗室的Blue Pacific使用 5808 個 IBM PowerPC 604e芯片,洛斯阿拉莫斯國傢實驗室的Blue Mountain(上圖)則使用 6144 個MIPS Technologies R1000。
為達到萬億次浮點運算級別的處理能力,需要數千個 CPU,所有這些都需要大量 RAM 和硬盤存儲的支持。這過去是,現在仍然是,由於機器的數學要求。
當我們在學校第一次接觸物理、化學和其他學科的方程時,一切都是一維的。換句話說,我們使用一個數字來表示距離、速度、質量、時間等。然而,為準確地建模和模擬現象,需要更多的維度,並且數學上升到向量、矩陣和張量的領域。
它們在數學中被視為單個實體,但包含多個值,這意味著任何進行計算的計算機都需要同時處理大量數字。鑒於當時的 CPU 每個周期隻能處理一到兩個浮點數,因此需要數千個浮點數。
SIMD 加入競爭:
MMX、3DNow!和SSE
1997 年,Intel 通過名為MMX 的技術擴展更新 Pentium CPU 系列,這是一組利用內核內部八個附加寄存器的指令。每個都被設計為存儲一到四個整數值。該系統允許處理器同時執行跨多個數字的一條指令,這種方法被稱為 SIMD(Single Instruction, Multiple Data)。
一年後,AMD 推出自己的版本,名為3DNow!。它的性能尤其優越,因為寄存器可以存儲浮點值。又過一年,英特爾才在 MMX 中解決這個問題,並在 Pentium III 中引入SSE (Streaming SIMD Extensions)。

隨著日歷進入新千年,高性能計算機的設計者可以使用能夠有效處理矢量數學的標準處理器。
一旦擴展到數千個,這些處理器就可以同樣出色地管理矩陣和張量。盡管取得這一進步,超級計算機世界仍然青睞舊的或專用的芯片,因為這些新的擴展並不是專門為此類任務而設計的。對於另一種快速普及的處理器來說,GPU 也是如此,它比 AMD 或 Intel 的任何 CPU 都更擅長 SIMD 工作。
在圖形處理器的早期,CPU 處理構成場景的三角形的計算(因此 AMD 用於執行 SIMD 的名稱為 3DNow!)。然而,像素的著色和紋理完全由 GPU 處理,並且這項工作的許多方面都涉及矢量數學。
20 多年前最好的消費級顯卡,例如 3dfx Voodoo5 5500和 NVIDIA GeForce 2 Ultra,都是出色的 SIMD 設備。然而,它們的創建目的是為遊戲生成 3D 圖形,而不是其他任何東西。即使是專業市場的顯卡也隻專註於渲染。

ATI 售價 2,000 美元的 ATI FireGL 3 配備兩個 IBM 芯片(一個 GT1000 幾何引擎和一個 RC1000 光柵器)、一個巨大的 128 MB DDR-SDRAM 以及據稱 30 GFLOPS 的處理能力。但這一切都是為使用 OpenGL 渲染 API 加速 3D Studio Max 和 AutoCAD 等程序中的圖形。
那個時代的 GPU 無法用於其他用途,因為轉換 3D 對象並將其轉換為監視器圖像的過程並不涉及大量的浮點數學。事實上,其中很大一部分是在整數級別,並且圖形卡需要幾年的時間才開始在整個管道中大量使用浮點值。
第一個是ATI 的 R300 處理器,它有 8 個獨立的像素管道,以 24 位浮點精度處理所有數學運算。不幸的是,除圖形之外,沒有其他方法可以利用這種能力——硬件和相關軟件完全以圖像為中心。
計算機工程師並沒有忘記 GPU 擁有大量 SIMD 功能,但缺乏將其應用到其他領域的方法這一事實。令人驚訝的是,這是一個遊戲機,展示如何解決這個棘手的問題。
統一的新時代
微軟的Xbox 360於2005年11月上市,其CPU由IBM設計和制造,基於PowerPC架構,GPU由ATI設計、臺積電制造。
這款代號為 Xenos 的圖形芯片很特別,因為它的佈局完全避開單獨的頂點和像素管道的經典方法。

取而代之的是一個三路 SIMD 陣列集群。具體來說,每個集群由 16 個向量處理器組成,每個向量處理器包含 5 個數學單元。這種佈局使每個陣列能夠在每個周期對 80 個浮點數據值同時執行來自線程的兩條順序指令。
被稱為統一著色器架構(unified shader architecture),每個陣列可以處理任何類型的著色器。盡管 Xenos 使芯片的其他方面變得更加復雜,但它引發一種至今仍在使用的設計范例。在時鐘速度為 500 MHz 的情況下,整個集群理論上可以為乘法加法命令的三個線程實現 240 GFLOPS (500 x 16 x 80 x 2) 的處理速率。
為讓這個數字有一定的規模感,十年前的一些世界頂級超級計算機無法匹敵這個速度。例如,桑迪亞國傢實驗室的aragon XP/S140憑借 3,680 個 Intel i860 CPU 在 1994 年名列世界超級計算機榜首,峰值速度為 184 GFLOPS。芯片開發的速度很快就超過這臺機器,但 GPU 也是如此。
CPU 多年來一直在整合自己的 SIMD 陣列,例如,英特爾最初的 Pentium MMX 有一個專用單元,用於在向量上執行指令,最多包含 8 個 8 位整數。當 Xbox 的 Xenos 在全球傢庭中使用時,此類設備的尺寸至少增加一倍,但與 Xenos 相比,它們仍然很小。

當消費級顯卡開始采用具有統一著色器架構的 GPU 時,它們已經擁有比 Xbox 360 的圖形芯片明顯更高的處理速率。
GeForce 8800 GTX (2006 ) 中使用的 NVIDIA G80(上圖)的理論峰值為 346 GLFOPS,而Radeon HD 2900 XT (2007) 中的 ATI R600 則擁有 476 GLFOPS。
兩傢圖形芯片制造商很快就在其專業模型中利用這種計算能力。雖然價格過高,但 ATI FireGL V8650 和 NVIDIA Tesla C870 非常適合高端科學計算機。然而,在最高級別上,全世界的超級計算機仍然依賴標準 CPU。事實上,幾年後 GPU 才開始出現在最強大的系統中。
超級計算機和類似系統的設計、建造和操作都極其昂貴。多年來,它們都是圍繞大量 CPU 陣列構建的,因此集成另一個處理器並不是一朝一夕的事。此類系統在增加芯片數量之前需要進行徹底的規劃和初始小規模測試。
其次,讓所有這些組件協調運行,尤其是軟件方面,絕非易事,這也是當時 GPU 的一個重大弱點。雖然它們已經變得高度可編程,但以前可供它們使用的軟件相當有限。
Microsoft 的 HLSL(Higher Level Shader Language)、NVIDIA 的Cg 庫和 OpenGL 的 GLSL 使訪問圖形芯片的處理能力變得簡單,盡管純粹是為渲染。
統一著色器架構 GPU 改變這一切。
2006 年,當時已成為AMD 子公司的ATI和 NVIDIA 發佈軟件工具包,旨在將這種能力不僅僅用於圖形,其 API 分別稱為 CTM(Close To Metal)和CUDA(Compute Unified Device Architecture)。
然而,科學和數據處理社區真正需要的是一個全面的軟件包,它將大量的 CPU 和 GPU(通常稱為異構平臺)視為由眾多計算設備組成的單個實體。
他們的需求在 2009 年得到滿足。OpenCL 最初由 Apple 開發,由 Khronos Group 發佈,該集團幾年前吸收 OpenGL,成為在日常圖形之外或當時該領域使用 GPU 的事實上的軟件平臺GPGPU 指的是 GPU 上的通用計算,該術語由Mark Harris創造。
GPU 進入計算競賽
與廣闊的技術評論世界不同,全球范圍內並沒有數百名評論者測試超級計算機的性能主張。然而,德國曼海姆大學於 20 世紀 90 年代初啟動的一個正在進行的項目正是致力於實現這一目標。
該組織被稱為“TOP500”,每年兩次發佈全球最強大的 10 臺超級計算機排行榜。
第一個誇耀 GPU 的條目出現在 2010 年,中國有兩個系統——Nebulae 和Tianhe-1。它們分別依賴於 NVIDIA 的Tesla C2050(本質上是 GeForce GTX 470,如下圖所示)和 AMD 的Radeon HD 4870芯片,前者的理論峰值為 2,984 TFLOPS。

在高端 GPGPU 的早期階段,NVIDIA 是為計算巨頭配備的首選供應商,不是因為性能(因為 AMD 的 Radeon 卡通常提供更高程度的處理性能),而是因為軟件支持。CUDA經歷快速發展,幾年後 AMD 才找到合適的替代方案,鼓勵用戶改用 OpenCL。
然而,英偉達並沒有完全主導市場,英特爾的至強融核處理器試圖占據一席之地。這些大型芯片源自一個名為 Larrabee 的已中止的 GPU 項目,是一種特殊的 CPU-GPU 混合體,由多個類似奔騰的核心(CPU 部分)與大型浮點單元(GPU 部分)配對組成。
對 NVIDIA Tesla C2050 內部結構的檢查揭示 14 個稱為流式多處理器 (SM) 的塊,由緩存和中央控制器劃分。每一個都包含 32 組兩個邏輯電路(NVIDIA 稱之為 CUDA 核心),用於執行所有數學運算——一組用於整數值,另一組用於浮點數。在後一種情況下,內核可以在每個時鐘周期以單(32 位)精度管理一次 FMA(融合乘加)操作;雙精度(64 位)運算至少需要兩個時鐘周期。
Xeon Phi 芯片(如下所示)中的浮點單元看起來有些相似,隻是每個內核處理的數據值是 C2050 中 SM 的一半。盡管如此,由於與 Tesla 的 14 個重復核心相比,有 32 個重復核心,單個 Xeon Phi 處理器總體上每個時鐘周期可以處理更多的值。然而,英特爾首次發佈的該芯片更多的是一個原型,並不能完全發揮其潛力——英偉達的產品運行速度更快,功耗更低,並被證明最終是優越的。
這將成為 AMD、英特爾和 NVIDIA 之間三路 GPGPU 之爭中反復出現的主題。一種型號可能擁有數量較多的處理核心,而另一種型號可能具有更快的時鐘速度或更強大的緩存系統。
CPU 對於所有類型的計算仍然至關重要,許多超級計算機和高端計算系統仍然由 AMD 或英特爾處理器組成。雖然單個 CPU 無法與普通 GPU 的 SIMD 性能競爭,但當數千個 CPU 連接在一起時,它們就證明足夠。然而,此類系統缺乏功效。
例如,在天河一號超級計算機使用Radeon HD 4870 GPU的同時,AMD最大的服務器CPU(12核Opteron 6176 SE)也開始流行。對於大約 140 W 的功耗,CPU 理論上可以達到 220 GFLOPS,而 GPU 隻需額外 10 W 即可提供 1,200 GFLOPS 的峰值,而且成本僅為其一小部分。
一個可以(做更多事情)的小顯卡
幾年後,不僅僅是世界上的超級計算機在利用 GPU 來集體進行並行計算。NVIDIA 正在積極推廣其GRID 平臺,這是一種用於科學和其他應用的 GPU 虛擬化服務。最初是作為托管基於雲的遊戲的系統而推出的,對大規模、經濟實惠的 GPGPU 不斷增長的需求使得這一轉變不可避免。在其年度技術會議上,GRID 被認為是各領域工程師的重要工具。
在同一事件中,GPU 制造商展示代號為 Volta 的未來架構。公佈的細節很少,普遍的假設是這將是另一款服務於英偉達所有市場的芯片。

與此同時,AMD 也在做類似的事情,在其專註於遊戲的 Radeon 系列以及 FirePro 和 Radeon Sky 服務器卡中利用定期更新的 Graphics Core Next (GCN) 設計。那時,性能數據已經令人震驚——FirePro W9100 的峰值 FP32 吞吐量為 5.2 TFLOPS(32 位浮點),這個數字對於不到二十年前的超級計算機來說是不可想象的。
GPU 仍然主要是為 3D 圖形設計的,但渲染技術的進步意味著這些芯片必須越來越熟練地處理一般計算工作負載。唯一的問題是它們執行高精度浮點數學(即 FP64 或更高)的能力有限。
縱觀2015 年頂級超級計算機,與完全基於 CPU 的超級計算機相比,使用 GPU(英特爾的 Xeon Phi 或 NVIDIA 的 Tesla)的數量相對較少。
當 NVIDIA 在 2016 年推出Pascal 架構時,這一切都發生變化。這是該公司首次嘗試專門為高性能計算市場設計 GPU,其他 GPU 則用於多個領域。前者隻生產過一款(GP100),並且隻產生 5 種產品,但之前所有架構都隻配備少數 FP64 內核,而這款芯片卻容納近 2,000 個內核。

Tesla P100 提供超過 9 TFLOPS 的 FP32 處理能力和 FP64 處理能力的一半,它的功能非常強大。AMD 的 Radeon Pro W9100 使用 Vega 10 芯片,在 FP32 下速度快 30%,但在 FP64 下慢 800%。此時,英特爾因銷售不佳而瀕臨停產 Xeon Phi。
一年後,NVIDIA 終於發佈 Volta,這表明該公司不僅僅有興趣將其 GPU 引入 HPC 和數據處理市場,它還瞄準另一個市場。
神經元、網絡
深度學習是機器學習這一更廣泛學科中的一個領域,而機器學習又是人工智能的一個子集。它涉及使用復雜的數學模型(稱為神經網絡)從給定數據中提取信息。
一個例子是確定所呈現的圖像描繪特定動物的概率。為此,模型需要進行“訓練”——在本例中,顯示數百萬張該動物的圖像,以及數百萬張不顯示該動物的圖像。所涉及的數學植根於矩陣和張量計算。
幾十年來,此類工作負載隻適合基於 CPU 的大型超級計算機。然而,早在 2000 年代,GPU 就顯然非常適合此類任務。
盡管如此,英偉達還是押註於深度學習市場的大幅擴張,並在其 Volta 架構中添加額外的功能,使其在該領域脫穎而出。這些是作為張量核心銷售的 FP16 邏輯單元組,作為一個大型陣列一起運行,但功能非常有限。
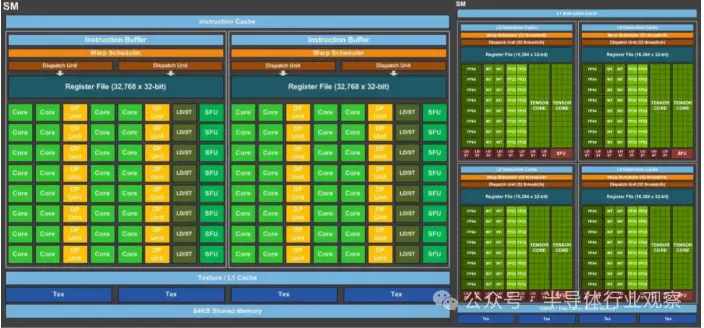
事實上,它們的功能非常有限,隻能執行一個功能:將兩個 FP16 4x4 矩陣相乘,然後將另一個 FP16 或 FP32 4x4 矩陣添加到結果中(這一過程稱為 GEMM 運算)。NVIDIA 之前的 GPU 以及競爭對手的 GPU 也能夠執行此類計算,但速度遠不及 Volta。使用該架構的唯一 GPU GV100 總共容納 512 個張量核心,每個核心能夠在每個時鐘周期執行 64 個 GEMM。
根據數據集中矩陣的大小以及所使用的浮點大小,Tesla V100 卡在這些張量計算中理論上可以達到 125 TFLOPS。Volta 顯然是為小眾市場設計的,但 GP100 在超級計算機領域的進展有限,而新的 Tesla 型號則迅速被采用。
PC 愛好者會知道,NVIDIA 隨後在圖靈架構的通用消費產品中添加張量核心,並開發一種名為DLSS(Deep Learning Super Sampling)的升級技術,該技術使用 GPU 中的核心在計算機上運行神經網絡。放大圖像,糾正幀中的任何偽影。
在短時間內,NVIDIA 獨占 GPU 加速的深度學習市場,其數據中心部門的收入大幅增長——2017 財年增長率為 145%,2018 財年增長率為 133%,2019 財年增長率為 52%。截至 2019 財年末,HPC、深度學習等領域的銷售額總計 29 億美元,這是一個非常積極的結果。
但隨後,市場真的爆發。該公司 2023 年第四季度的總收入為 221 億美元,同比增長 265%。其中大部分增長來自該公司的人工智能計劃,該計劃創造 184 億美元的收入。

然而,隻要有錢,競爭就不可避免,盡管 NVIDIA 仍然是迄今為止最大的 GPU 提供商,但其他大型科技公司也沒有坐以待斃。
2018 年,Google開始通過雲服務提供對其內部開發的張量處理芯片的訪問。亞馬遜很快也緊隨其後,推出專用 CPU AWS Graviton。與此同時,AMD 正在重組其 GPU 部門,形成兩條不同的產品線:一條主要用於遊戲 (RDNA),另一條專門用於計算 (CDNA)。
雖然 RDNA 與其前身明顯不同,但 CDNA 在很大程度上是 GCN 的自然演變,盡管規模擴大到一個巨大的水平。看看當今用於超級計算機、數據服務器和人工智能機器的 GPU,一切都非常巨大。
AMD 的 CDNA 2 驅動的MI250X擁有 220 個計算單元,提供略低於 48 TFLOPS 的雙精度 FP64 吞吐量和 128 GB 的高帶寬內存 (HBM2e),這兩個方面在 HPC 應用中都備受追捧。NVIDIA 的 GH100 芯片采用Hopper 架構和 576 個 Tensor Core,在 AI 矩陣計算中采用低精度 INT8 數字格式,有可能達到 4000 TOPS。
英特爾的Ponte Vecchio GPU 同樣龐大,擁有 1000 億個晶體管,AMD 的 MI300 擁有 460 億個晶體管,包括多個 CPU、圖形和內存小芯片。
然而,它們共有的一件事是它們絕對不是 GPU:它們不是 GPU。早在英偉達將該術語用作營銷工具之前,該縮寫詞就代表圖形處理單元。AMD 的 MI250X 沒有任何渲染輸出單元 (ROP:render output units),甚至 GH100 也僅擁有類似於 GeForce GTX 1050 的Direct3D 性能,使得 GPU 中的“G”變得無關緊要。
那麼,我們可以稱呼它們什麼呢?
“GPGPU”並不理想,因為它是一個笨拙的短語,指的是在通用計算中使用 GPU,而不是設備本身。“HPCU”(高性能計算單元)也好不多少。但也許這並不重要。
畢竟,“CPU”一詞非常廣泛,涵蓋各種不同的處理器和用途。
GPU 接下來要征服什麼?
NVIDIA、AMD、Apple、Intel 和其他數十傢公司在 GPU 研發上投入數十億美元,當今的圖形處理器不會很快被任何截然不同的產品所取代。
對於渲染,最新的 API 和使用它們的軟件包(例如遊戲引擎和 CAD 應用程序)通常與運行代碼的硬件無關,因此從理論上講,它們可以適應全新的東西。
然而,GPU 中專門用於圖形的組件相對較少,三角形設置引擎和 ROP 是最明顯的組件,並且最近版本中的光線追蹤單元也高度專業化。然而,其餘部分本質上是大規模並行 SIMD 芯片,由強大而復雜的內存/緩存系統支持。
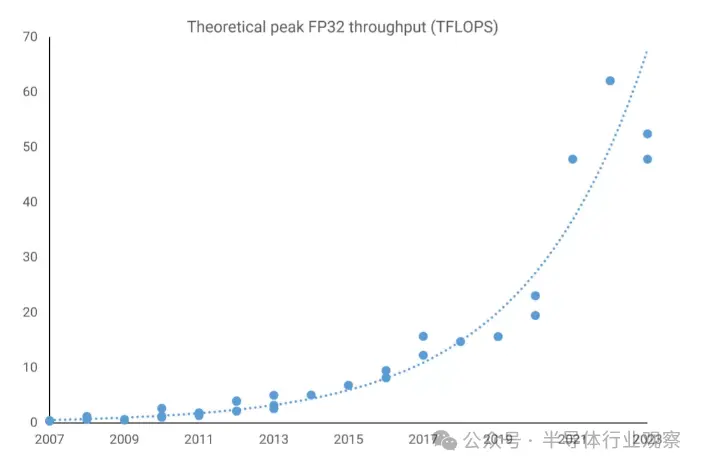
基本設計與以往一樣好,未來的任何改進都與半導體制造技術的進步緊密相關。換句話說,它們隻能通過容納更多邏輯單元、以更高的時鐘速度運行或兩者的組合來改進。
當然,它們可以合並新功能,使其能夠在更廣泛的場景中發揮作用。在 GPU 的歷史上,這種情況已經發生過多次,但向統一著色器架構的過渡尤為重要。雖然最好擁有專用硬件來處理張量或光線追蹤計算,但現代 GPU 的核心能夠管理這一切,盡管速度較慢。
這就是為什麼 AMD MI250 和 NVIDIA GH100 等產品與臺式電腦的同類產品非常相似,未來用於 HPC 和 AI 的設計很可能會遵循這一趨勢。那麼,如果芯片本身不會發生重大變化,那麼它們的應用又如何呢?
鑒於與 AI 相關的任何事物本質上都是計算的一個分支,因此隻要需要執行大量 SIMD 計算,就可能會使用 GPU。雖然科學和工程領域沒有多少領域尚未使用此類處理器,但我們可能會看到 GPU 衍生產品的使用激增。
目前人們可以購買配備微型芯片的手機,其唯一功能是加速張量計算。隨著ChatGPT等工具的功能和普及度不斷增強,我們將看到更多配備此類硬件的設備。
不起眼的 GPU 已經從僅僅比 CPU 更快地運行遊戲的設備發展成為通用加速器,為全球的工作站、服務器和超級計算機提供動力。
全球數百萬人每天都在使用它——不僅在我們的計算機、電話、電視和流媒體設備中,而且在我們使用包含語音和圖像識別或提供音樂和視頻推薦的服務時也是如此。
GPU 真正的下一步可能是一個未知的領域,但有一點是肯定的,圖形處理單元將在未來幾十年內繼續成為計算和人工智能的主要工具。