在之前的演講介紹中,臺積電曾多次談到萬億晶體管的路線圖。今天,在IEEE網站上,發表一篇署名為《HowWe’llReacha1TrillionTransistorGPU》的文章,講述臺積電是如何達成萬億晶體管芯片的目標。
值得一提的是,本文署名作者MARK LIU(劉德音)和H.-S. PHILIP WONG,其中劉德音是臺積電董事長。H.-S Philip Wong則是斯坦福大學工程學院教授、臺積電首席科學傢。
在這裡,我們將此文翻譯出來,以饗讀者。

以下為文章正文:
1997 年,IBM 深藍超級計算機擊敗國際象棋世界冠軍Garry Kasparov。這是超級計算機技術的突破性演示,也是對高性能計算有一天可能超越人類智能水平的首次展示。在接下來的10年裡,我們開始將人工智能用於許多實際任務,例如面部識別、語言翻譯以及推薦電影和商品。
再過十五年,人工智能已經發展到可以“合成知識”(synthesize knowledge)的地步。生成式人工智能,如ChatGPT和Stable Diffusion,可以創作詩歌、創作藝術品、診斷疾病、編寫總結報告和計算機代碼,甚至可以設計與人類制造的集成電路相媲美的集成電路。
人工智能成為所有人類事業的數字助手,面臨著巨大的機遇。ChatGPT是人工智能如何使高性能計算的使用民主化、為社會中的每個人帶來好處的一個很好的例子。
所有這些奇妙的人工智能應用都歸功於三個因素:高效機器學習算法的創新、訓練神經網絡的大量數據的可用性,以及通過半導體技術的進步實現節能計算的進步。盡管它無處不在,但對生成式人工智能革命的最後貢獻卻沒有得到應有的認可。
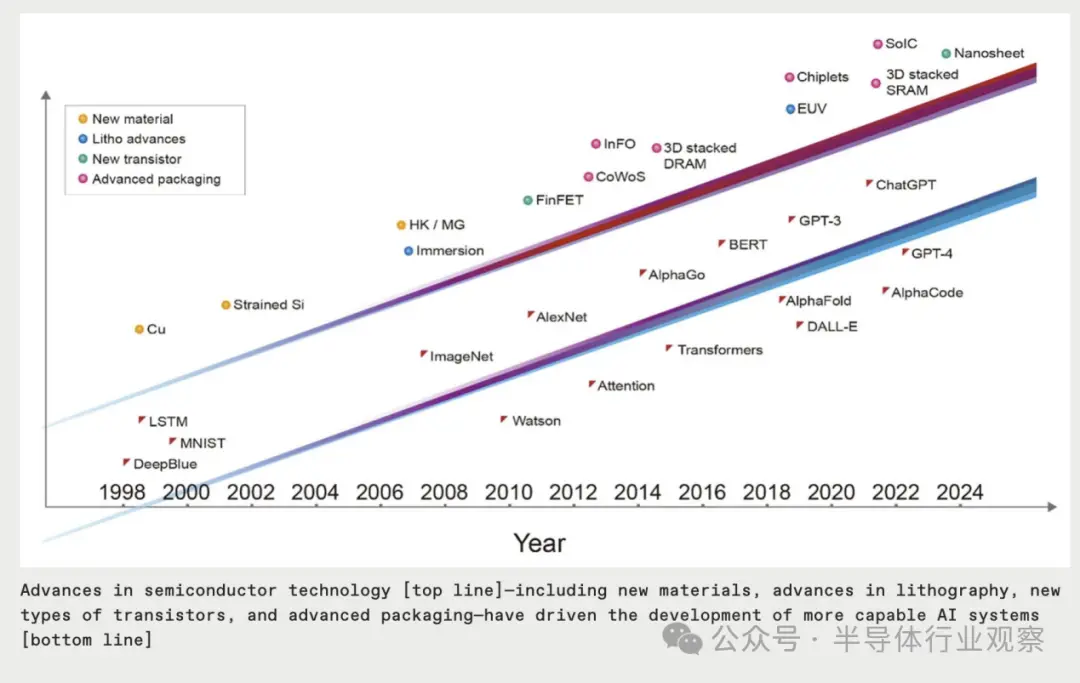
在過去的三十年裡,人工智能的重大裡程碑都是由當時領先的半導體技術實現的,沒有它就不可能實現。Deep Blue 采用 0.6 微米和 0.35 微米節點芯片制造技術的混合實現;贏得 ImageNet 競賽的深度神經網絡並開啟當前機器學習時代的設備使用 40 納米技術打造的芯片;AlphaGo 使用 28 納米技術征服圍棋遊戲;ChatGPT 的初始版本是在采用 5 納米技術構建的計算機上進行訓練的。;ChatGPT 的最新版本由使用更先進的4 納米技術的服務器提供支持。所涉及的計算機系統的每一層,從軟件和算法到架構、電路設計和設備技術,都充當人工智能性能的乘數。但可以公平地說,基礎晶體管器件技術推動上面各層的進步。
如果人工智能革命要以目前的速度繼續下去,它將需要半導體行業做出更多貢獻。十年內,它將需要一個 1 萬億晶體管的 GPU,也就是說,GPU 的設備數量是當今典型設備數量的 10 倍。
AI 模型大小的不斷增長,讓人工智能訓練所需的計算和內存訪問在過去五年中增加幾個數量級。例如,訓練GPT-3需要相當於一整天每秒超過 50 億次的計算操作(即 5,000 petaflops /天),以及 3 萬億字節 (3 TB) 的內存容量。
新的生成式人工智能應用程序所需的計算能力和內存訪問都在持續快速增長。我們現在需要回答一個緊迫的問題:半導體技術如何跟上步伐?
從集成器件到集成小芯片
自集成電路發明以來,半導體技術一直致力於縮小特征尺寸,以便我們可以將更多晶體管塞進縮略圖大小的芯片中。如今,集成度已經上升一個層次;我們正在超越 2D 縮放進入3D 系統集成。我們現在正在將許多芯片組合成一個緊密集成、大規模互連的系統。這是半導體技術集成的范式轉變。
在人工智能時代,系統的能力與系統中集成的晶體管數量成正比。主要限制之一是光刻芯片制造工具被設計用於制造不超過約 800 平方毫米的 IC,即所謂的光罩限制(reticle limit)。但我們現在可以將集成系統的尺寸擴展到光刻掩模版極限之外。通過將多個芯片連接到更大的中介層(一塊內置互連的矽片)上,我們可以集成一個系統,該系統包含的設備數量比單個芯片上可能包含的設備數量要多得多。例如,臺積電的CoWoS(chip-on-wafer-on-substrate )技術就可以容納多達六個掩模版區域的計算芯片,以及十幾個高帶寬內存(HBM)芯片。
CoWoS是臺積電的矽晶圓上芯片先進封裝技術,目前已在產品中得到應用。示例包括 NVIDIA Ampere 和 Hopper GPU。當中每一個都由一個 GPU 芯片和六個高帶寬內存立方體組成,全部位於矽中介層上。計算 GPU 芯片的尺寸大約是芯片制造工具當前允許的尺寸。Ampere有540億個晶體管,Hopper有800億個。從 7 納米技術到更密集的 4 納米技術的轉變使得在基本相同的面積上封裝的晶體管數量增加 50%。Ampere 和 Hopper 是當今大型語言模型 ( LLM ) 訓練的主力。訓練 ChatGPT 需要數萬個這樣的處理器。
HBM 是對 AI 日益重要的另一項關鍵半導體技術的一個例子:通過將芯片堆疊在一起來集成系統的能力,我們在臺積電稱之為SoIC (system-on-integrated-chips) 。HBM 由控制邏輯 IC頂部的一堆垂直互連的 DRAM 芯片組成。它使用稱為矽通孔 (TSV) 的垂直互連來讓信號通過每個芯片和焊料凸點以形成存儲芯片之間的連接。如今,高性能 GPU廣泛使用 HBM 。
展望未來,3D SoIC 技術可以為當今的傳統 HBM 技術提供“無凸塊替代方案”(bumpless alternative),在堆疊芯片之間提供更密集的垂直互連。最近的進展表明,HBM 測試結構采用混合鍵合技術堆疊 12 層芯片,這種銅對銅連接的密度高於焊料凸塊所能提供的密度。該存儲系統在低溫下粘合在較大的基礎邏輯芯片之上,總厚度僅為 600 µm。
對於由大量運行大型人工智能模型的芯片組成的高性能計算系統,高速有線通信可能會很快限制計算速度。如今,光學互連已被用於連接數據中心的服務器機架。我們很快就會需要基於矽光子學的光學接口,並與 GPU 和 CPU 封裝在一起。這將允許擴大能源效率和面積效率的帶寬,以實現直接的光學 GPU 到 GPU 通信,這樣數百臺服務器就可以充當具有統一內存的單個巨型 GPU。
由於人工智能應用的需求,矽光子將成為半導體行業最重要的使能技術之一。
邁向萬億晶體管 GPU
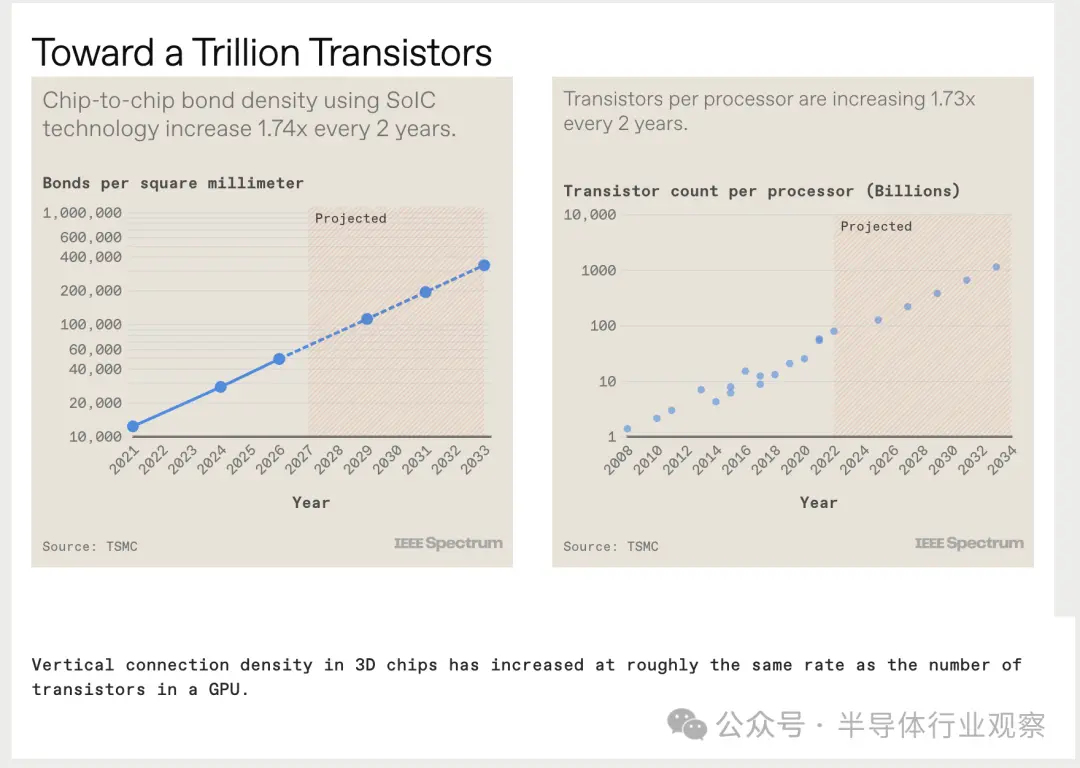
如前所述,用於 AI 訓練的典型 GPU 芯片已經達到標線區域極限(reticle field limit)。他們的晶體管數量約為1000億個。晶體管數量增加趨勢的持續將需要多個芯片通過 2.5D 或 3D 集成互連來執行計算。通過 CoWoS 或 SoIC 以及相關的先進封裝技術集成多個芯片,可以使每個系統的晶體管總數比壓縮到單個芯片中的晶體管總數大得多。如AMD MI 300A 就是采用這樣的技術制造的。
AMD MI300A 加速處理器單元不僅利用CoWoS,還利用臺積電的 3D 技術SoIC。MI300A結合 GPU 和 CPU內核,旨在處理最大的人工智能工作負載。GPU為AI執行密集的矩陣乘法運算,而CPU控制整個系統的運算,高帶寬存儲器(HBM)統一為兩者服務。采用 5 納米技術構建的 9 個計算芯片堆疊在 4 個 6 納米技術基礎芯片之上,這些芯片專用於緩存和 I/O 流量。基礎芯片和 HBM 位於矽中介層之上。處理器的計算部分由 1500 億個晶體管組成。
我們預測,十年內,多芯片 GPU 將擁有超過 1 萬億個晶體管。
我們需要在 3D 堆棧中將所有這些小芯片連接在一起,但幸運的是,業界已經能夠快速縮小垂直互連的間距,從而增加連接密度。而且還有足夠的空間容納更多。我們認為互連密度沒有理由不能增長一個數量級,甚至更高。
GPU 的節能性能趨勢
那麼,所有這些創新的硬件技術如何提高系統的性能呢?
如果我們觀察一個稱為節能性能的指標的穩步改進,我們就可以看到服務器 GPU 中已經存在的趨勢。EEP 是系統能源效率和速度(the energy efficiency and speed of a system)的綜合衡量標準。過去 15 年來,半導體行業的能效性能每兩年就提高三倍左右。我們相信這一趨勢將以歷史速度持續下去。它將受到多方面創新的推動,包括新材料、器件和集成技術、極紫外(EUV)光刻、電路設計、系統架構設計以及所有這些技術元素的共同優化等。
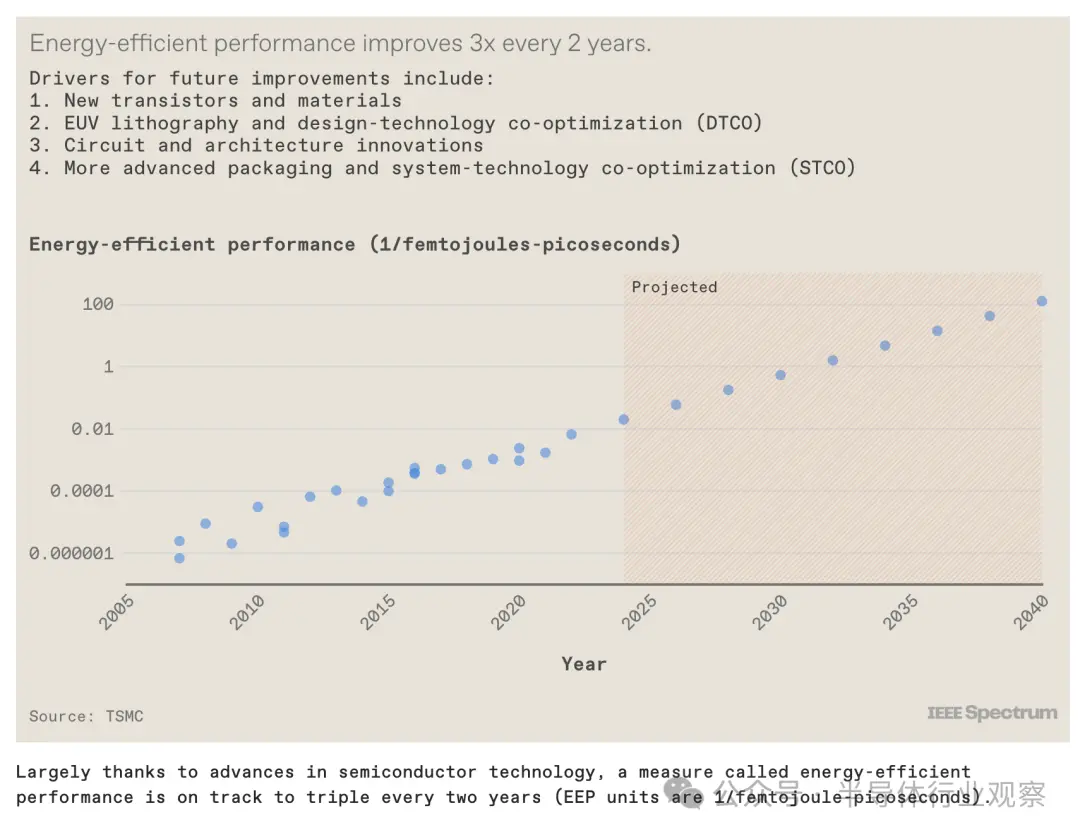
特別是,EEP 的增加將通過我們在此討論的先進封裝技術來實現。此外,系統技術協同優化 (STCO:system-technology co-optimization)等概念將變得越來越重要,其中 GPU 的不同功能部分被分離到各自的小芯片上,並使用性能最佳和最經濟的技術來構建每個部分。
3D 集成電路的Mead-Conway時刻
1978年,加州理工學院教授Carver Mead和施樂帕洛阿爾托研究中心的Lynn Conway發明集成電路的計算機輔助設計方法。他們使用一組設計規則來描述芯片縮放,以便工程師可以輕松設計超大規模集成(VLSI)電路,而無需解太多工藝技術。
3D 芯片設計也需要同樣的功能。如今,設計人員需要解芯片設計、系統架構設計以及硬件和軟件優化。制造商需要解芯片技術、3D IC技術和先進封裝技術。正如我們在 1978 年所做的那樣,我們再次需要一種通用語言,以電子設計工具可以理解的方式描述這些技術。這種硬件描述語言使設計人員可以自由地進行 3D IC 系統設計,而無需考慮底層技術。它正在路上:一種名為3Dblox 的開源標準已被當今大多數技術公司和電子設計自動化 (EDA) 公司所接受。
隧道之外的未來
在人工智能時代,半導體技術是人工智能新能力和應用的關鍵推動者。新的 GPU 不再受過去的標準尺寸和外形尺寸的限制。新的半導體技術不再局限於在二維平面上縮小下一代晶體管。集成人工智能系統可以由盡可能多的節能晶體管、用於專門計算工作負載的高效系統架構以及軟件和硬件之間的優化關系組成。
過去 50 年來,半導體技術的發展就像走在隧道裡一樣。前面的路很清晰,因為有一條明確的道路。每個人都知道需要做什麼:縮小晶體管。
現在,我們已經到達隧道的盡頭。從這裡開始,半導體技術將變得更加難以發展。然而,在隧道之外,還有更多的可能性。我們不再受過去的束縛。