在領先的人工智能實驗室之外,大多數新產品開發人員都不是從零開始的。他們從現成的人工智能(如Meta的開源語言模型Llama2)開始,然後從GitHub和HuggingFace等在線資源庫中尋找數據集,教生成式人工智能系統如何更好地回答問題或總結文本。

盡管這些數據集可免費獲取,但根據一項對廣泛使用的數據集進行檢查的最廣泛的研究項目顯示,這些數據集充斥著未經授權的數據。
在一群機器學習工程師和法律專傢的組織下,"數據出處倡議"(Data Provenance Initiative)研究用於教授人工智能模型擅長特定任務的專業數據,這一過程被稱為"微調"。他們審核 Hugging Face、GitHub 和 Papers With Code(2019 年加入 Facebook AI)等網站上的 1800 多個微調數據集,發現約 70% 的數據集沒有說明應使用何種許可,或者被錯誤地標註比其創建者意圖更寬松的準則。
能夠回答問題和模仿人類說話的聊天機器人的出現,掀起一場建立更大更好的生成式人工智能模型的競賽。這也引發有關版權和合理使用互聯網文本的問題,而互聯網文本是訓練大型人工智能系統所需的海量數據的關鍵組成部分。
但是,如果沒有適當的授權,開發人員就會對潛在的版權限制、商業使用限制或數據集創建者的信用要求一無所知。該倡議報告的共同作者、研究實驗室 Cohere for AI 的負責人薩拉-胡克(Sara Hooker)說:"即使人們想做正確的事,他們也做不到。"
麻省理工學院媒體實驗室研究大型語言模型的博士生 Shayne Longpre 領導這次審計,他說,托管網站允許用戶在上傳數據集時識別許可證,不應該因為錯誤或遺漏而受到指責。
朗普雷說,缺乏適當的文檔是一個源於現代機器學習實踐的全社會問題。數據檔案經常被多次合並、重新打包和重新授權。他說,試圖跟上新版本發佈步伐的研究人員可能會跳過記錄數據來源等步驟,或者故意模糊信息,以此作為"數據洗錢"的一種形式。
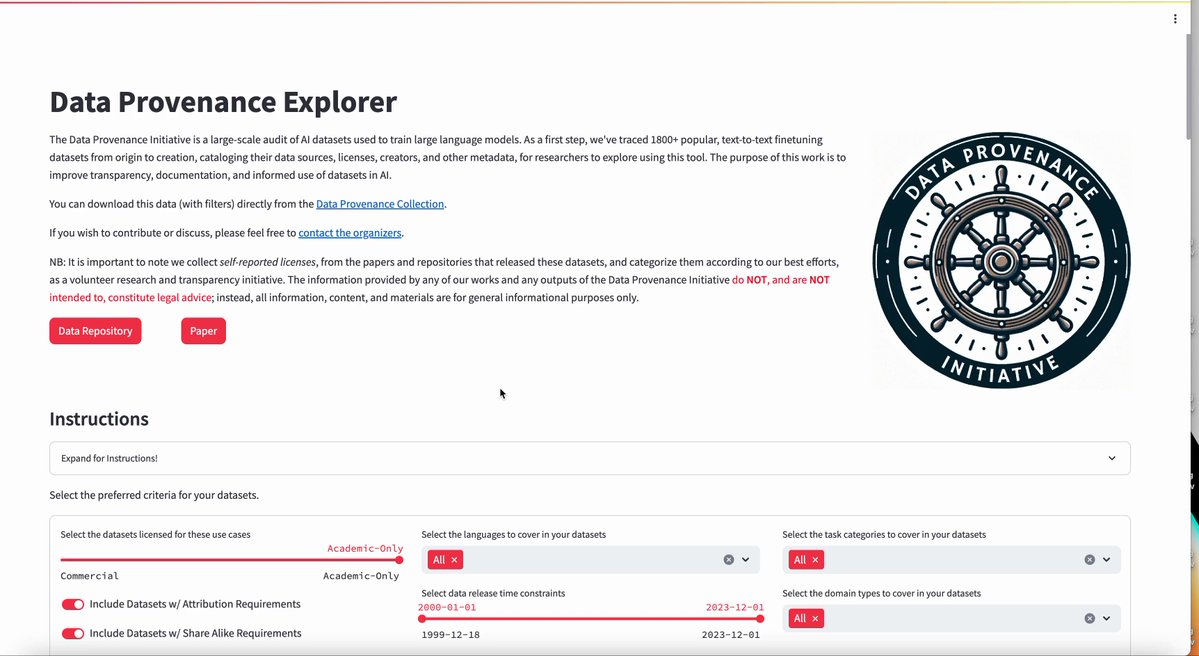
通過互動網站,用戶可以探索審計中分析的數據集內容,其中一些數據集已被下載數十萬次。
Hugging Face的機器學習和社會團隊負責人亞辛-傑尼特(Yacine Jernite)說,Hugging Face發現,數據集在開放、持續使用和共享的情況下,會有更好的文檔記錄。這傢開源公司已將改進文檔的工作列為優先事項,例如自動建議元數據。傑尼特說,即使註釋不完善,公開可訪問的數據集也是提高該領域透明度的有意義的第一步。
一些最常用的微調數據集最初是由OpenAI和Google等公司創建的數據集。越來越多的數據集是利用 OpenAI 模型創建的機器數據集。包括OpenAI在內的領先人工智能實驗室禁止使用其工具的輸出結果開發競爭性人工智能模型,但允許某些非商業用途。
人工智能公司對用於訓練和完善流行人工智能模型的數據越來越保密。這項新研究的目標是讓工程師、政策制定者和律師解助長人工智能淘金熱的不可見處的數據生態系統。
這項倡議的提出正值矽谷與數據所有者之間的緊張關系瀕臨臨界點之際。各大人工智能公司正面臨著來自圖書作者、藝術傢和編碼員的大量版權訴訟。與此同時,出版商和社交媒體論壇在閉門談判中威脅要扣留數據。
該倡議的探索工具指出,審計並不構成法律建議。Longpre 說,這些工具旨在幫助人們解信息,而不是規定哪種許可是合適的,也不是倡導某種特定的政策或立場。
作為分析的一部分,研究人員還跟蹤各數據集的模式,包括數據的收集年份和數據集創建者的地理位置。約 70% 的數據集創建者來自學術界,約 1% 的數據集創建者來自 Meta 等公司的行業實驗室。最常見的數據來源之一是維基百科,其次是 Reddit 和 Twitter(現在稱為 X)。
《華盛頓郵報》對Google C4 數據集的分析發現,在 1500 萬個域名中,維基百科是排名第二的網站。據《郵報》上周報道,Reddit最近威脅說,如果領先的人工智能公司不付費使用其數據來訓練模型,就會阻止Google和必應的搜索爬蟲,從而面臨搜索流量損失的風險。
與英語國傢和西歐國傢相比,南半球國傢的口語幾乎沒有代表性,數據出處小組的分析為常用數據集的局限性提供新的見解。
但該小組還發現,即使全球南部有語言代表,數據集"幾乎總是來自北美或歐洲的創作者和網絡來源",該小組的論文如是說。
胡克說,她希望該項目的工具能夠揭示未來研究的主要領域。她說:"數據集的創建通常是研究周期中最不光彩的部分,應該得到應有的歸屬,因為這需要大量的工作。我喜歡這篇論文,因為它脾氣暴夠躁,但也提出解決方案。我們必須從某個地方開始"。