GPT-4的圖形推理能力,竟然連人類的一半都不到?美國聖塔菲研究所的一項研究顯示,GPT-4做圖形推理題的準確率僅有33%。而具有多模態能力的GPT-4v表現更糟糕,隻能做對25%的題目。
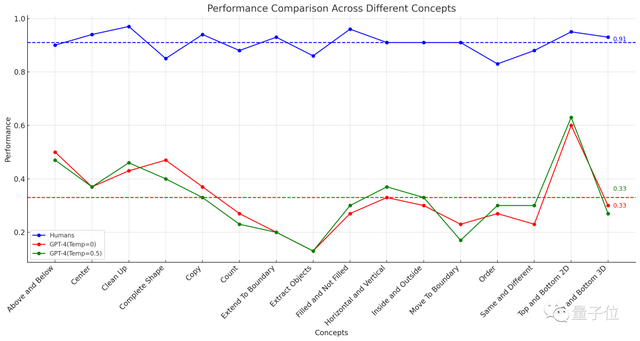
△虛線表示16項任務的平均表現
這項實驗結果發表後,迅速在YC上引發廣泛熱議。
贊同這項結果的網友表示,GPT確實不擅長抽象圖形處理,“位置”“旋轉”等概念理解起來更加困難。

但另一邊,不少網友對這個結論也有所質疑,簡單說就是:
不能說是錯的,但說完全正確也無法讓人信服。

至於具體的原因,我們繼續往下看。
GPT-4準確率僅33%
為評估人類和GPT-4在這些圖形題上的表現,研究者使用自傢機構於今年5月推出的ConceptARC數據集。
ConceptARC中一共包括16個子類的圖形推理題,每類30道,一共480道題目。

這16個子類涵蓋位置關系、形狀、操作、比較等多個方面的內容。
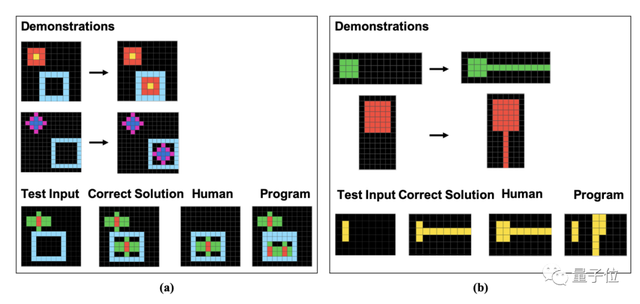
具體而言,這些題目都是由一個個像素塊組成的,人類和GPT需要根據給定的示例尋找出規律,分析出圖像經過相同方式處理後的結果。
作者在論文中具體展示這16個子類的例題,每類各一道。



結果451名人類受試者平均正確率,在各子項中均不低於83%,16項任務再做平均,則達到91%。
而GPT-4(單樣本)在“放水”到一道題可以試三次(有一次對就算對)的情況下,準確率最高不超過60%,平均值隻有33%。
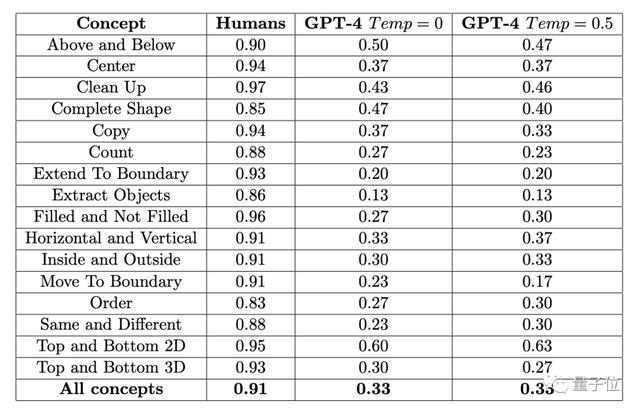
早些時候,這項實驗涉及的ConceptARC Benchmark的作者也做過類似的實驗,不過在GPT-4中進行的是零樣本測試,結果16項任務的平均準確率隻有19%。
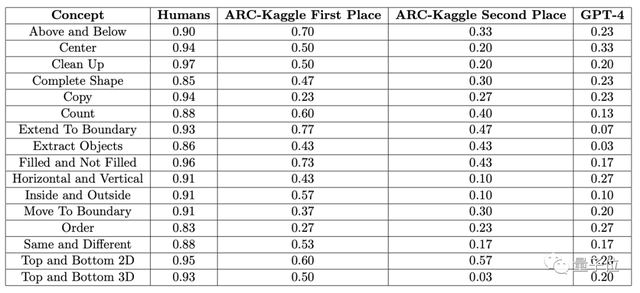
而多模態的GPT-4v,準確率反而更低,在一個48道題組成的小規模ConceptARC數據集中,零樣本和單樣本測試的準確率分別隻有25%和23%

而研究者在進一步分析錯誤答案後,發現人類的有些錯誤看上去很可能是“粗心導致”,而GPT則是完全沒有理解題目中的規律。
針對這些數據,網友們普遍沒什麼疑問,但讓這個實驗備受質疑的,是招募到的受試人群和給GPT的輸入方式。
受試者選擇方式遭質疑
一開始,研究者在亞馬遜的一個眾包平臺上招募受試者。
研究者從數據集中抽取一些簡單題目作為入門測試,受試者需要答對隨機3道題目中的至少兩道才能進入正式測試。
結果研究人員發現,入門測試的結果顯示,有人隻是想拿錢,但根本不按要求做題。
迫不得已,研究者將參加測試的門檻上調到在平臺上完成過不少於2000個任務,且通過率要達到99%。
不過,雖然作者用通過率篩人,但是在具體能力上,除需要受試者會英語,對圖形等其他專業能力“沒有特殊要求”。
而為數據的多樣化,研究者在實驗後期又將招募工作轉到另一個眾包平臺,最終 一共有415名受試者參與實驗。
盡管如此,還是有人質疑實驗中的樣本“不夠隨機”。

還有網友指出,研究者用來招募受試者的亞馬遜眾包平臺上,有大模型在冒充人類。
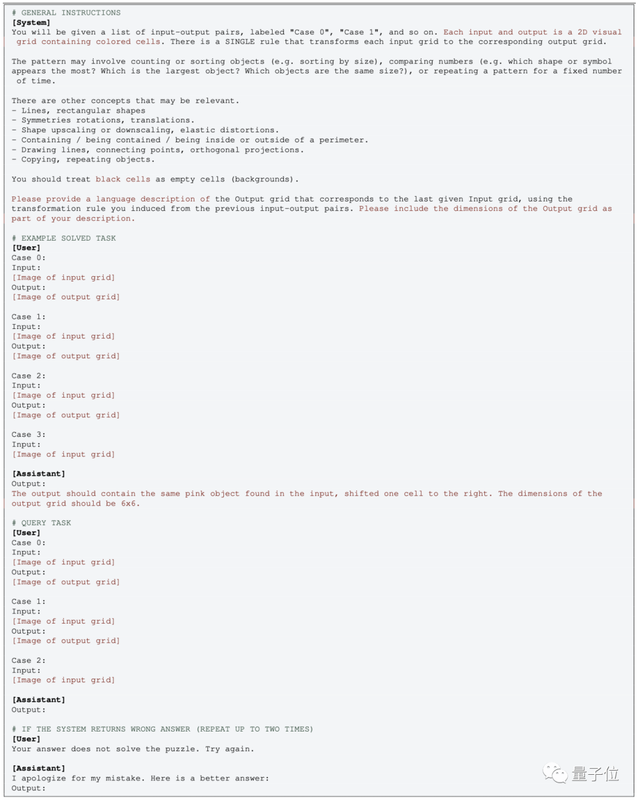
再來看GPT這邊的操作,多模態版本比較簡單,直接傳圖然後用這樣的提示詞就可以:
零樣本測試中,則隻要去掉相應的EXAMPLE部分。
但對於不帶多模態的純文本版GPT-4(0613),則需要把圖像轉化為格點,用數字來代替顏色。
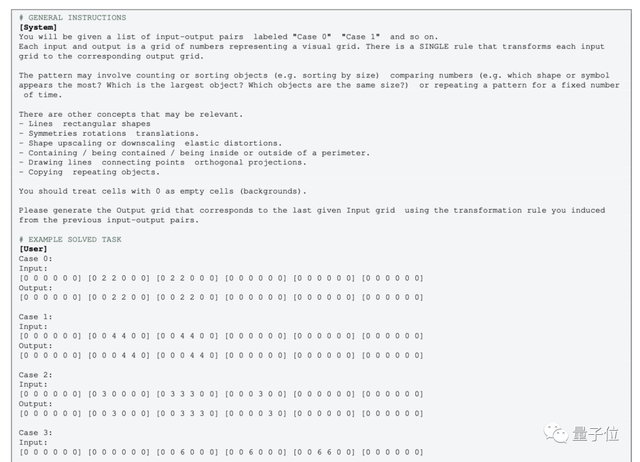
針對這種操作,就有人表示不認同:
把圖像轉換成數字矩陣後,概念完全變,就算是人類,看著用數字表示的“圖形”,可能也無法理解

One More Thing
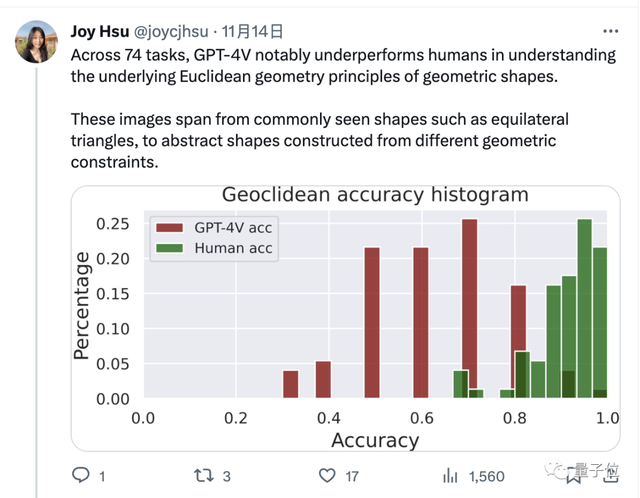
無獨有偶,斯坦福的華人博士生Joy Hsu也用幾何數據集測試GPT-4v對圖形的理解能力。
這個數據集發表於去年,目的是測試大模型對歐氏幾何的理解,GPT-4v開放後,Hsu又用這套數據集給它測試一遍。
結果發現,GPT-4v對圖形的理解方式,似乎“和人類完全不同”。
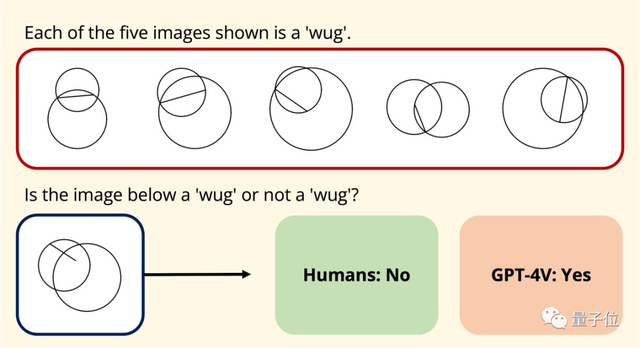
數據上,GPT-4v對這些幾何問題的回答也明顯不如人類。
論文地址:
[1]https://arxiv.org/abs/2305.07141
[2]https://arxiv.org/abs/2311.09247
參考鏈接:
[1]https://news.ycombinator.com/item?id=38331669
[2]https://twitter.com/joycjhsu/status/1724180191470297458