昨天,很多人徹夜未眠——全球科技圈都把目光聚焦在美國舊金山。短短45分鐘時間裡,OpenAICEO山姆・奧特曼向我們介紹迄今為止最強的大模型,和基於它的一系列應用,一切似乎就像當初ChatGPT一樣令人震撼。OpenAI在本周一的首個開發者日上推出GPT-4Turbo,新的大模型更聰明,文本處理上限更高,價格也更便宜,應用商店也開起來。現在,用戶還可以根據需求構建自己的GPT。
根據官方說法,這一波 GPT 的升級包括:
更長的上下文長度:128k,相當於 300 頁文本。
更高的智能程度,更好的 JSON / 函數調用。
更高的速度:每分鐘兩倍 token。
知識更新:目前的截止日期為 2023 年 4 月。
定制化:GPT3 16k、GPT4 微調、定制模型服務。
多模態:Dall-E 3、GPT4-V 和 TTS 模型現已在 API 中。
Whisper V3 開源(即將推出 API)。
與開發者分享收益的 Agent 商店。
GPT4 Turbo 的價格約是 GPT4 的 1/3。
發佈會一開完,人們蜂擁而入開始嘗試。GPT4 Turbo 的體驗果然不同凡響。首先是快,快到和以前所有大模型拉開代差:
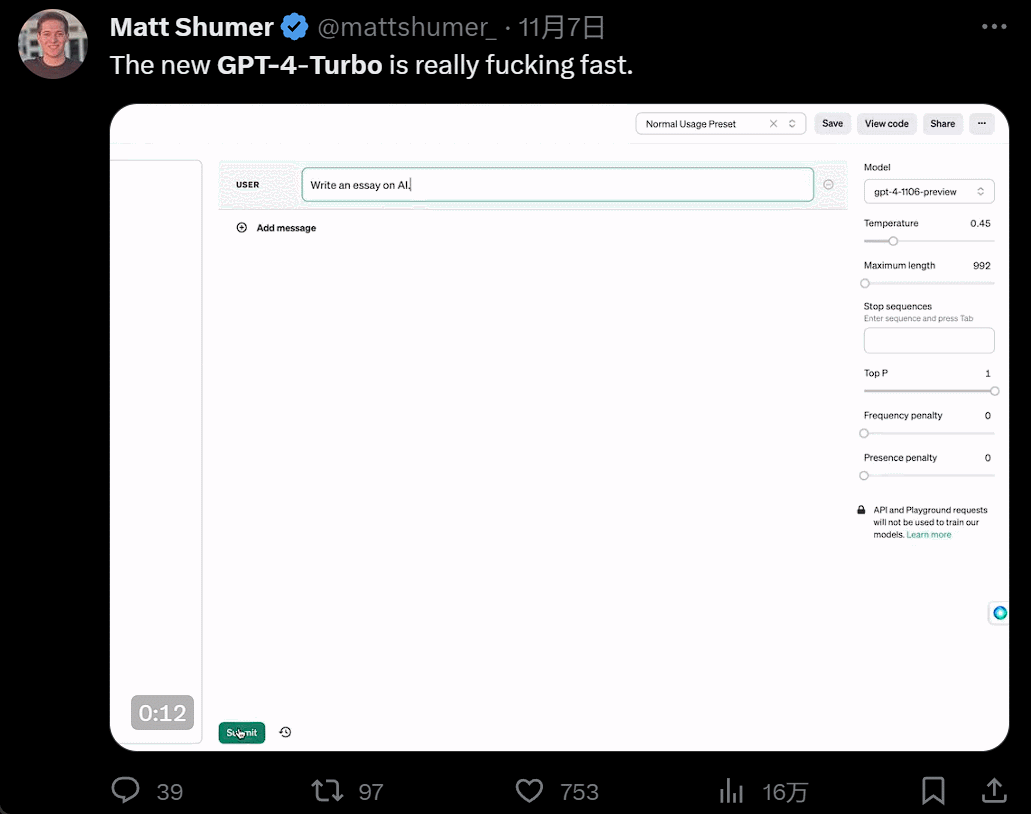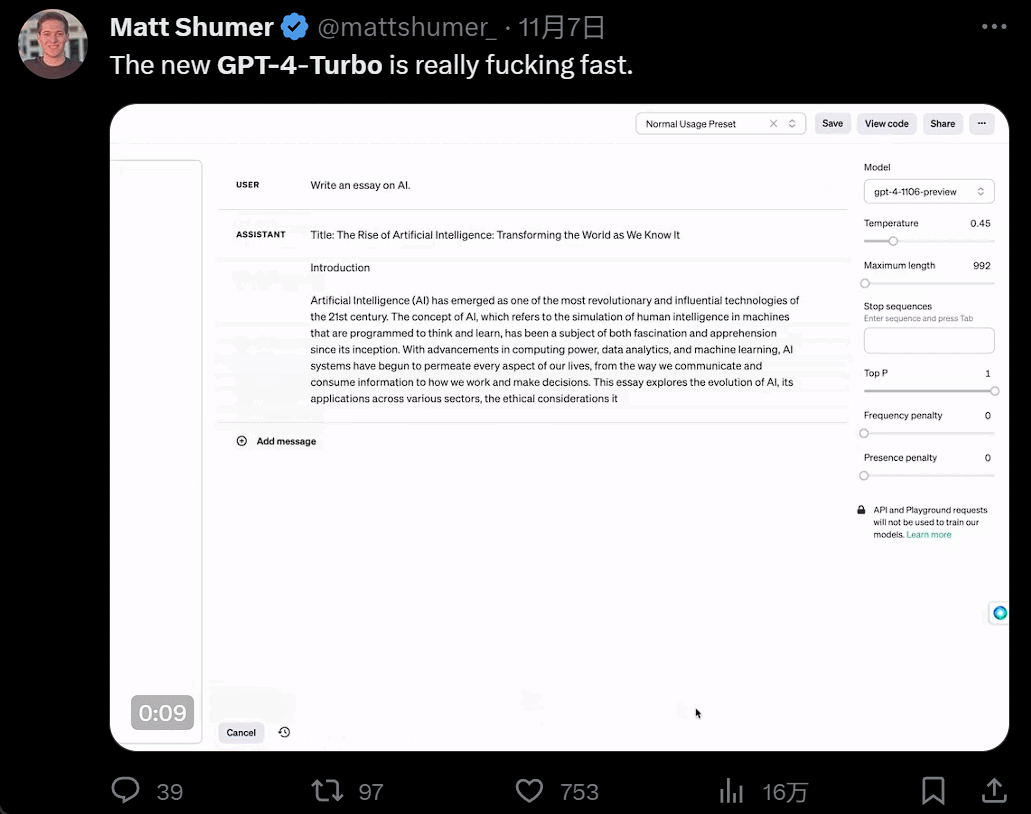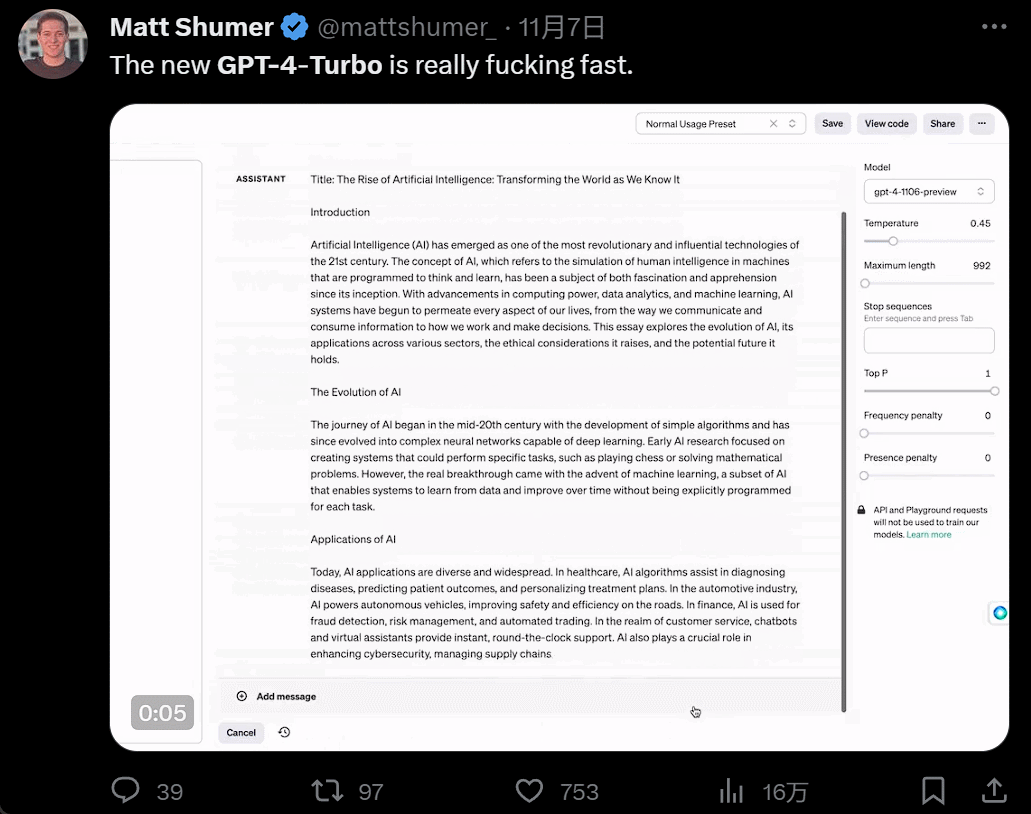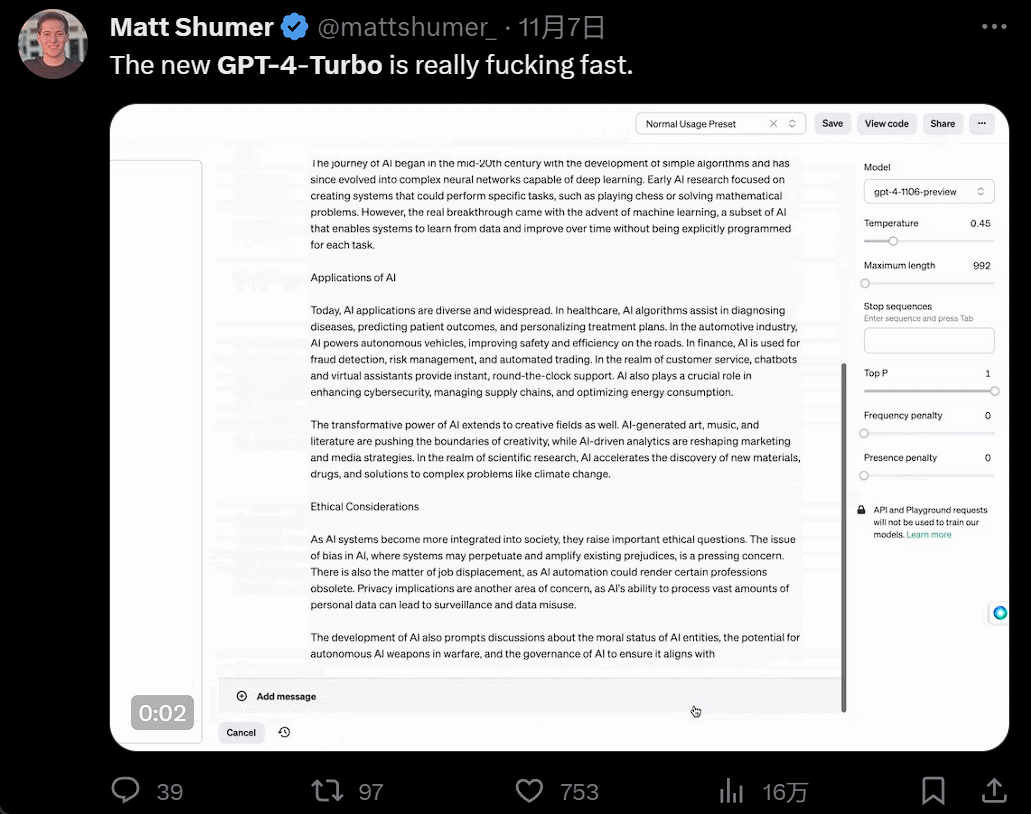
然後是功能增多,畫畫的時候,你一有靈感就可以直接說話讓 AI 負責實現:
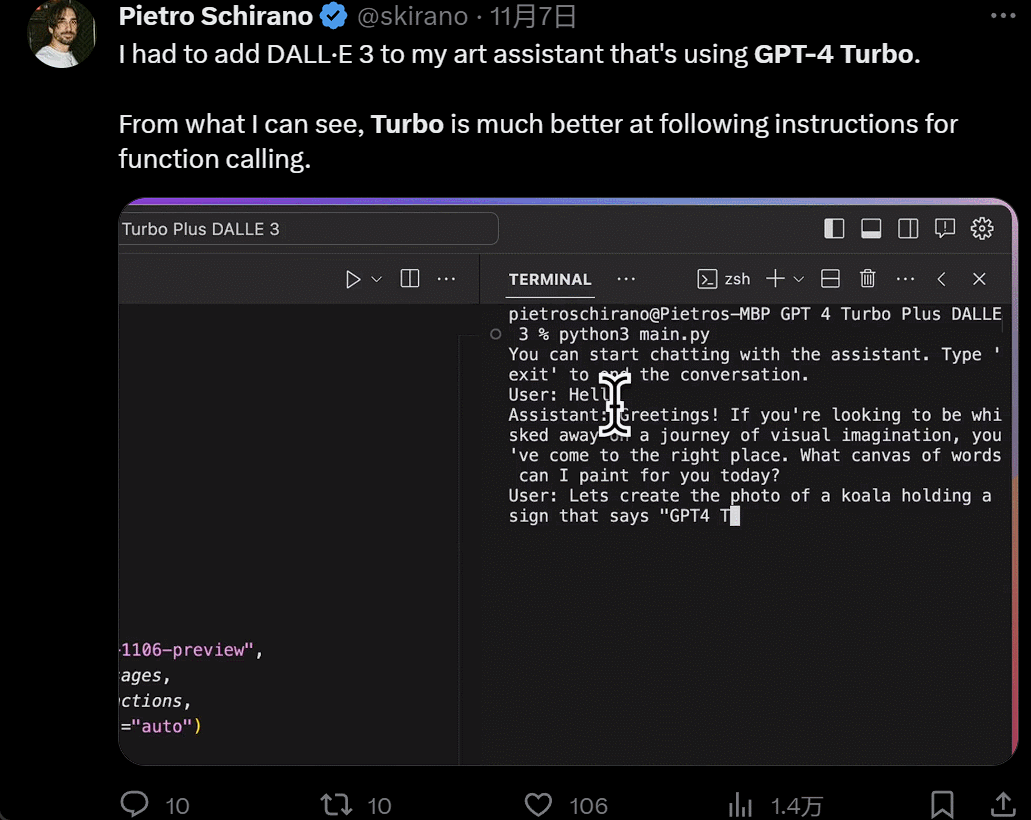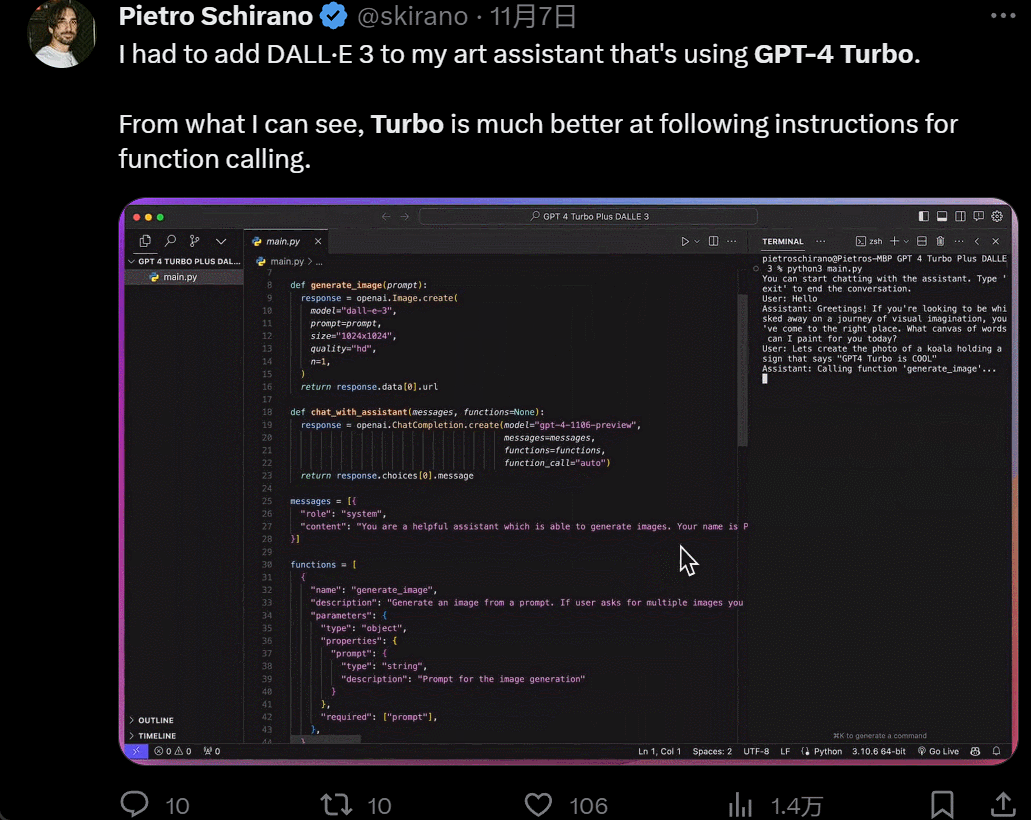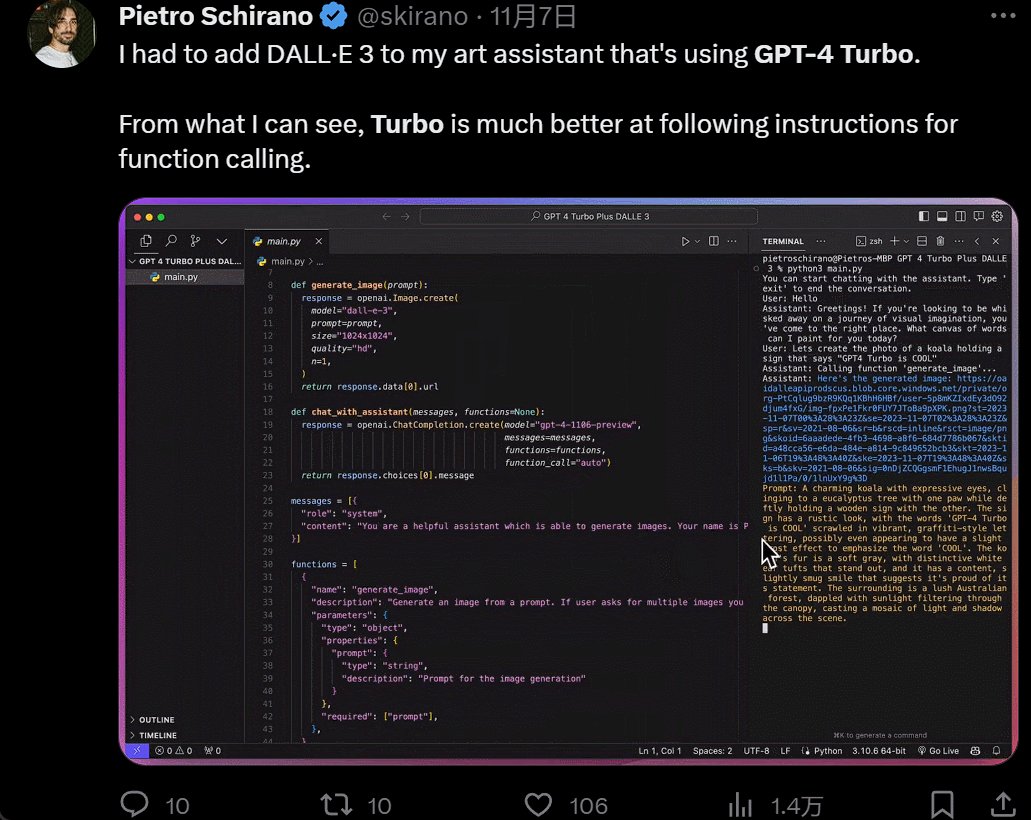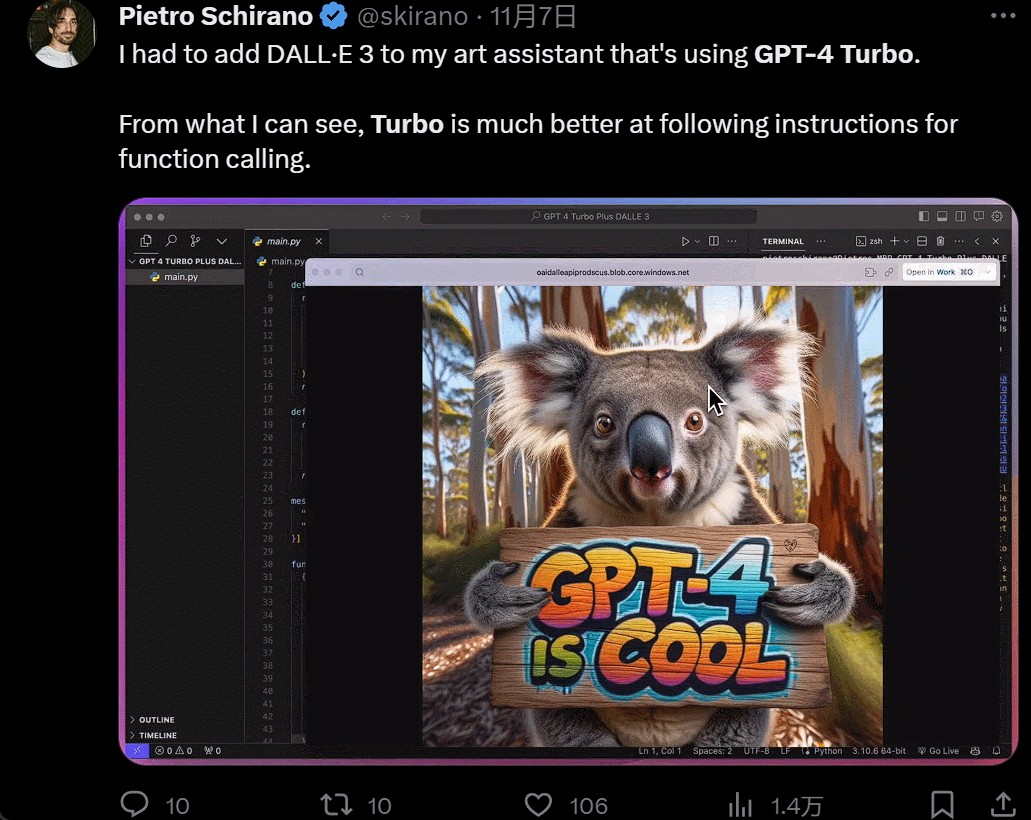
設計個 UI,幾個小時的工作變成幾分鐘:
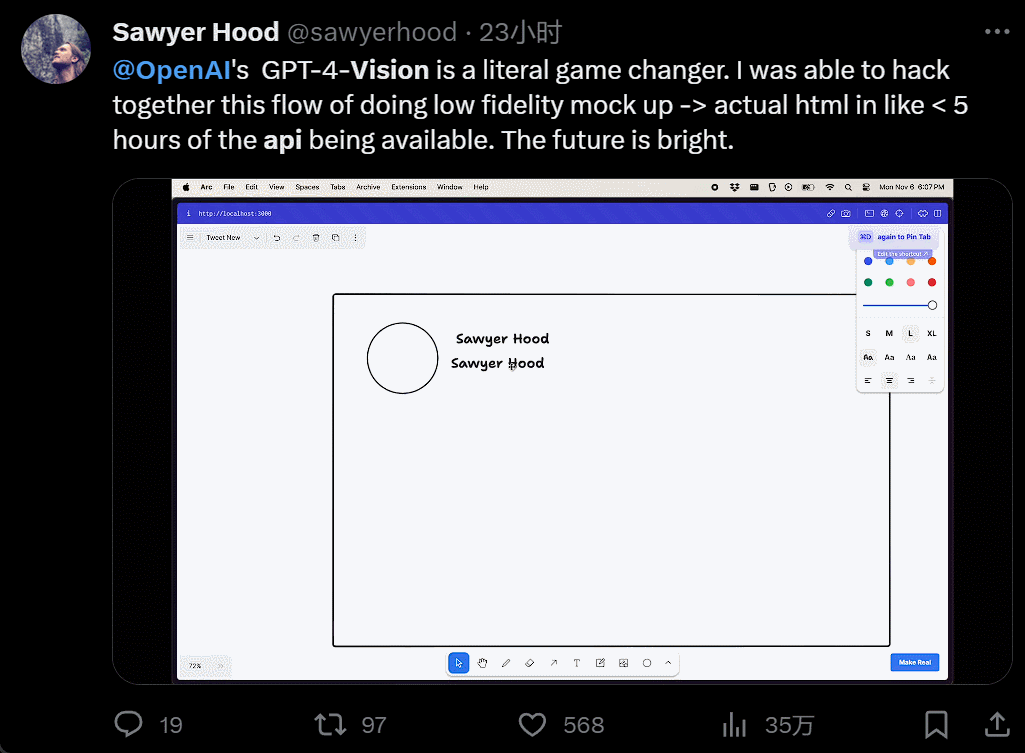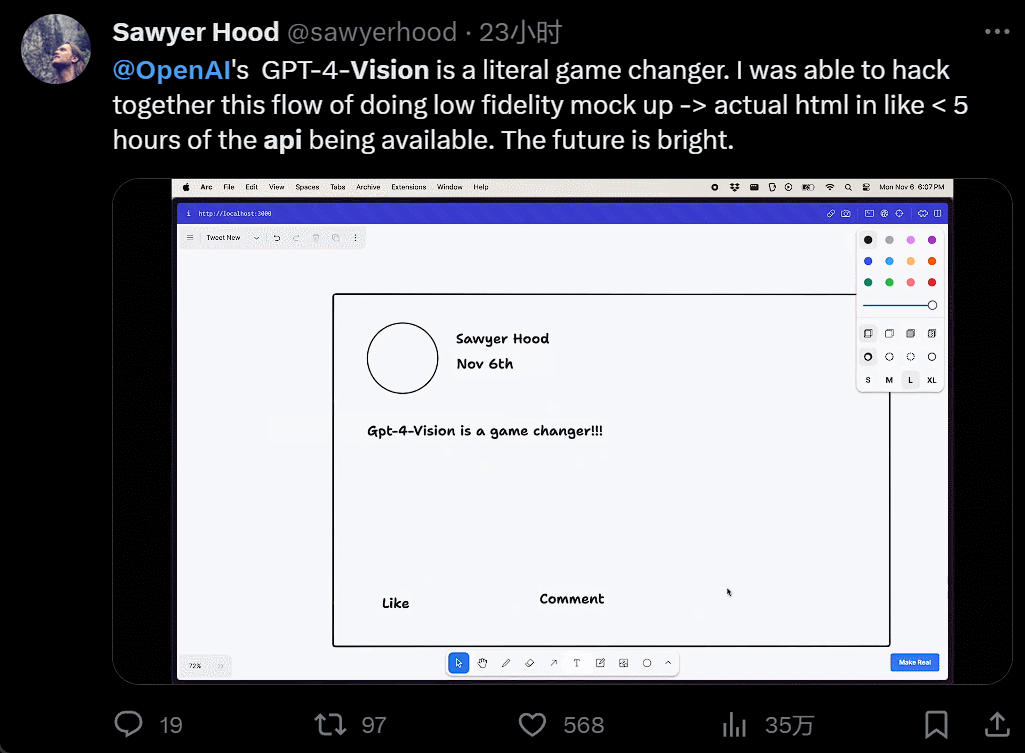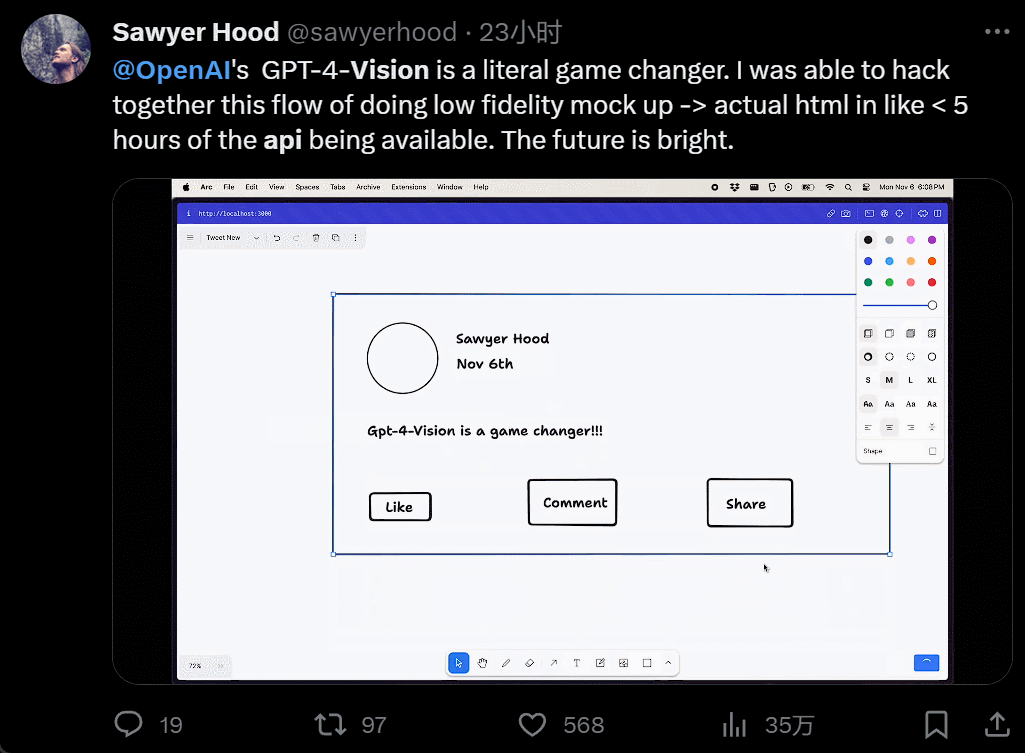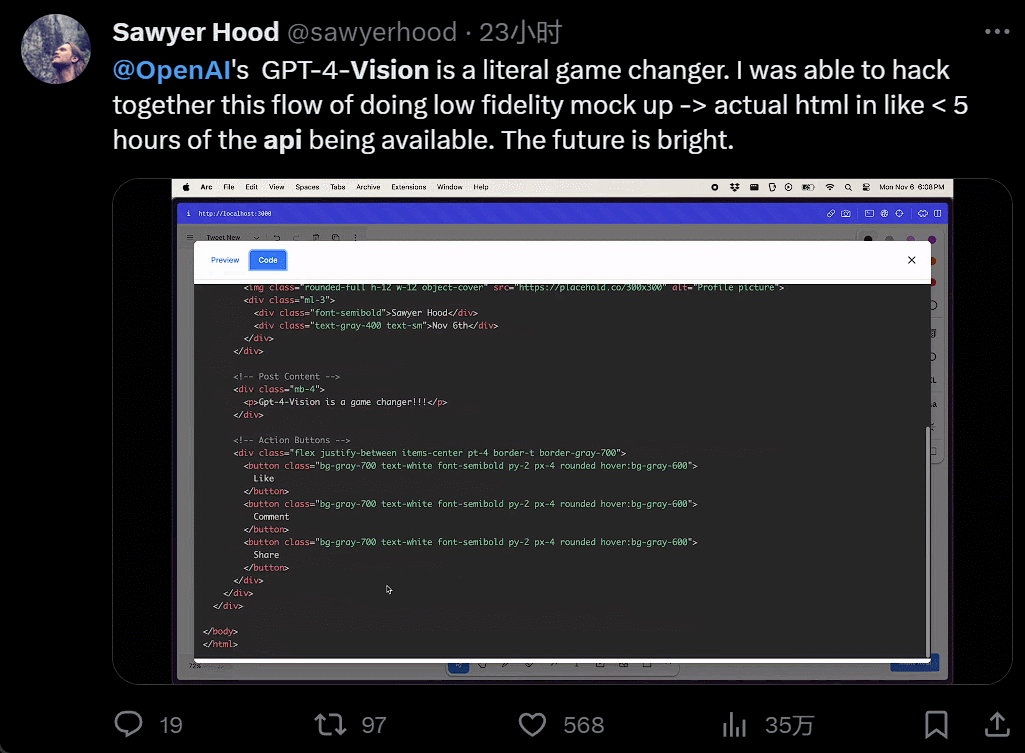
我直接不裝,截個圖復制粘貼別人的網站,生成自己的,隻用 40 秒:
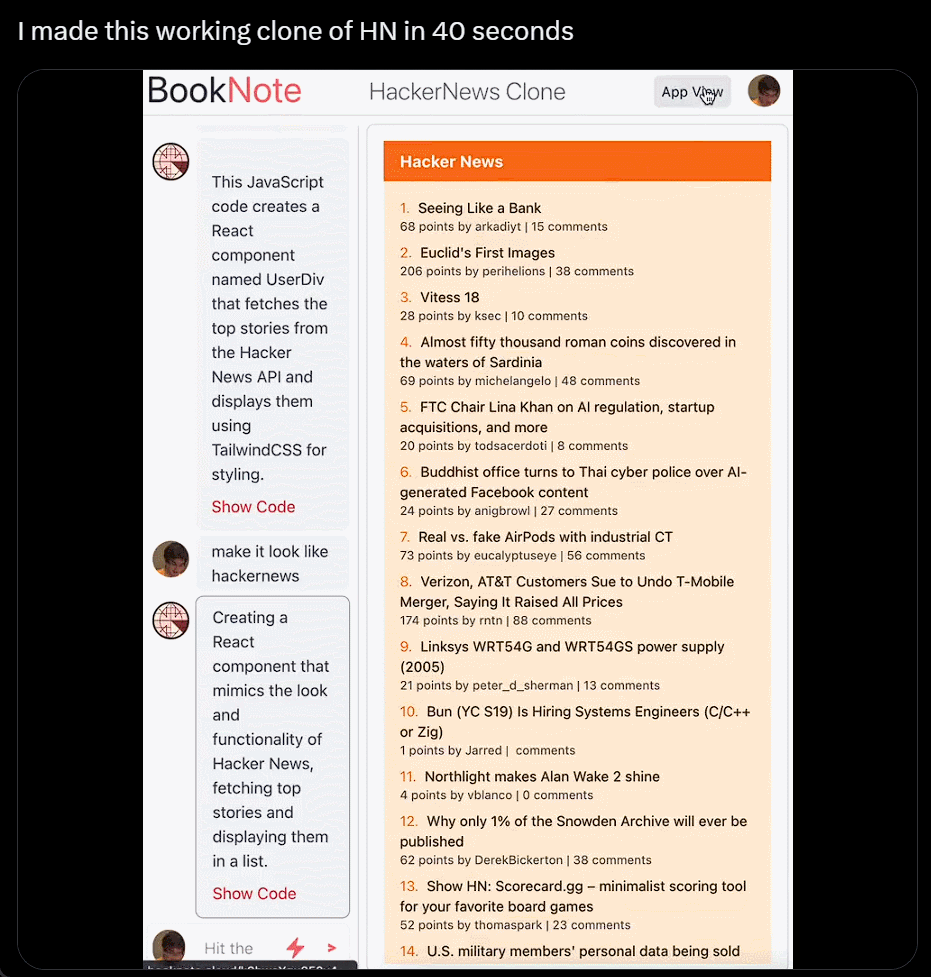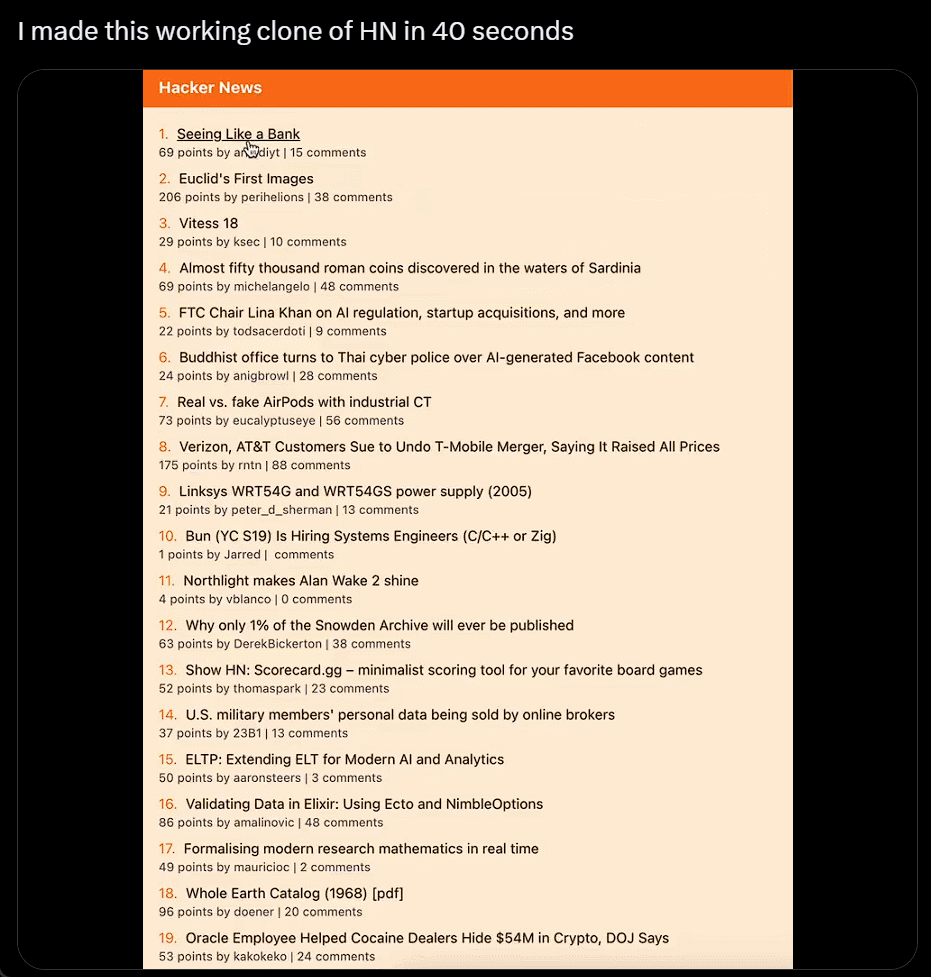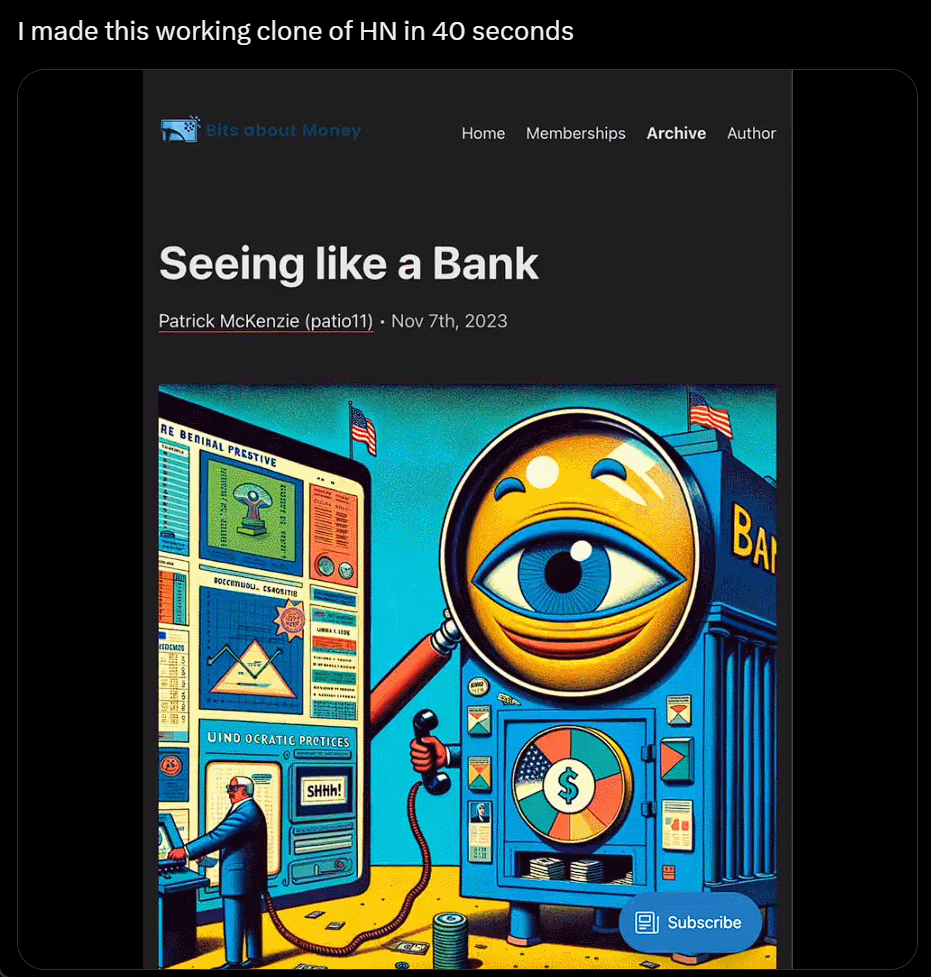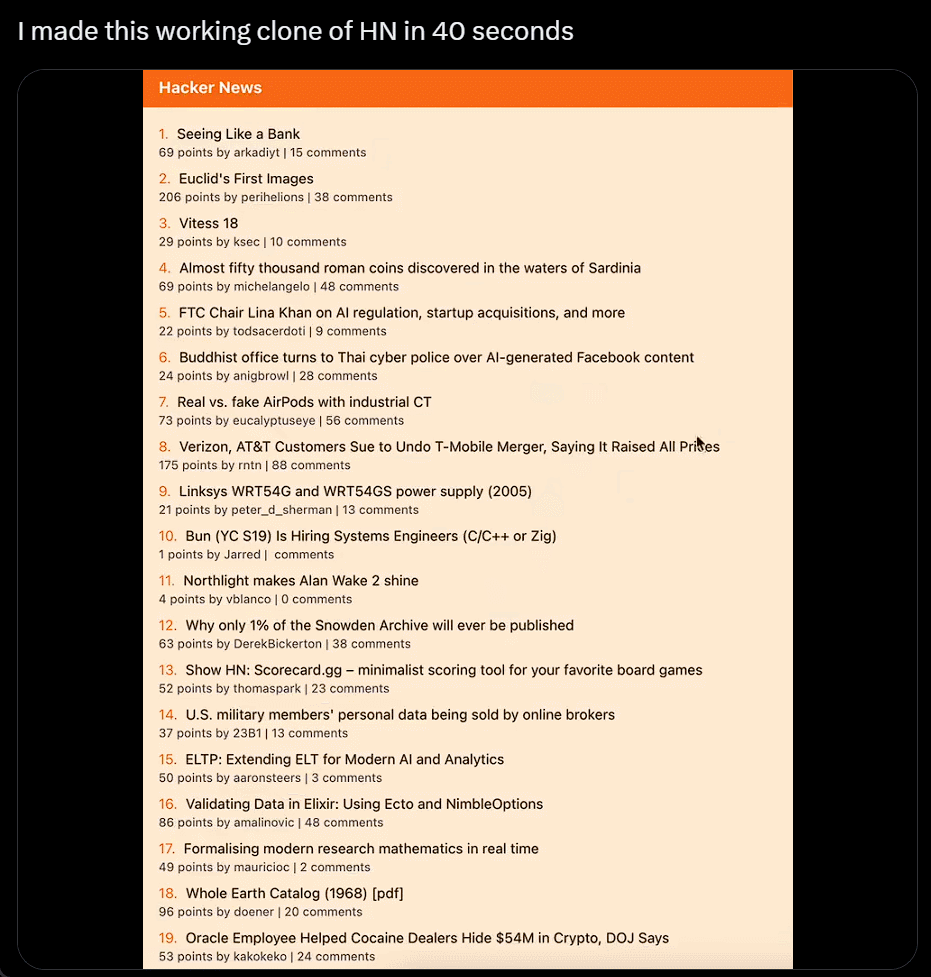
利用 ChatGPT 與 Bing 的瀏覽功能以及與 DALL-E 3 圖像生成器的集成,沃頓商學院教授 Ethan Mollick 分享一段視頻,展示他的名為“趨勢分析器”的 GPT 工具,其可查找市場特定細分市場的趨勢,然後創建新產品的原型圖像。
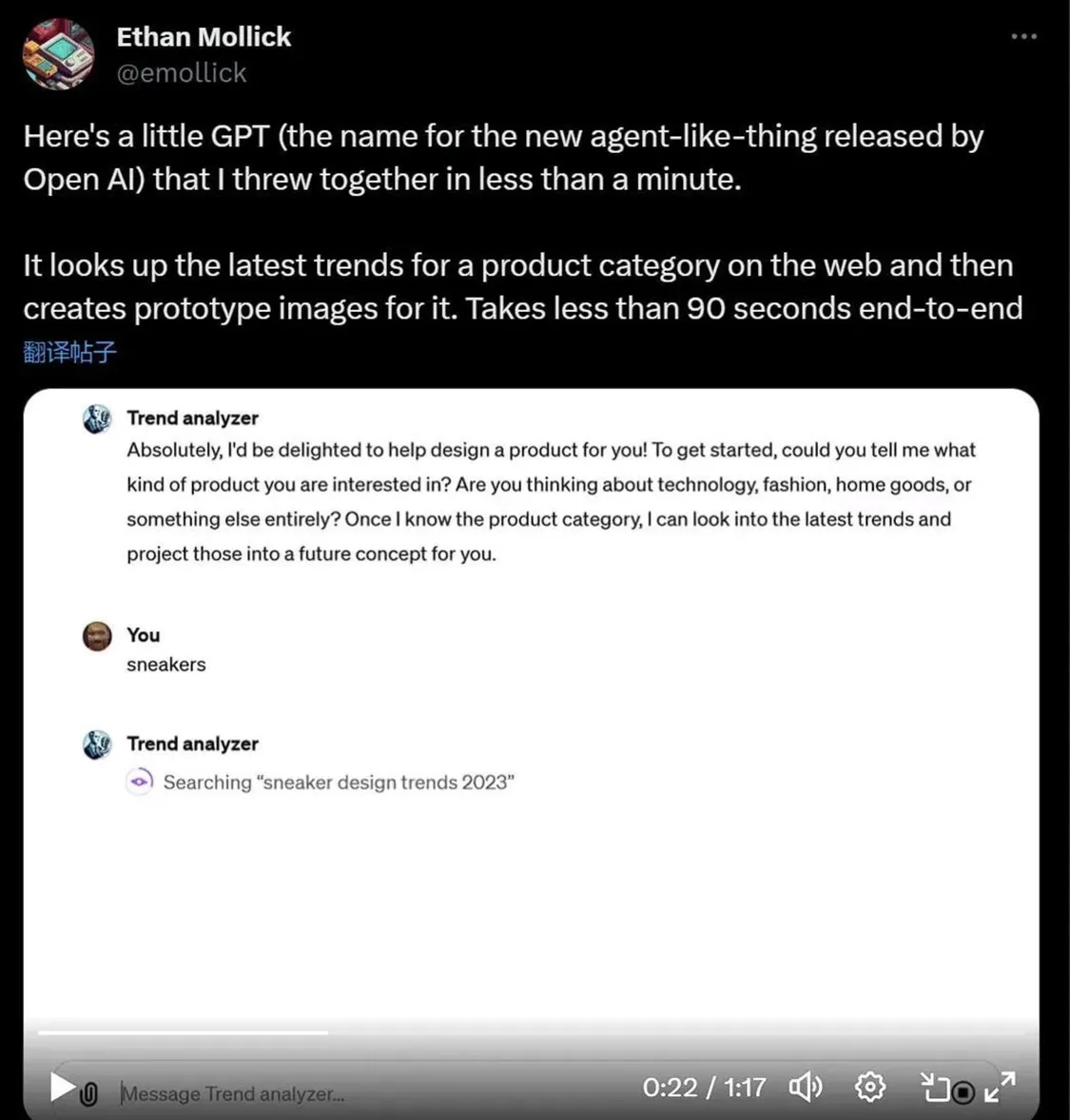
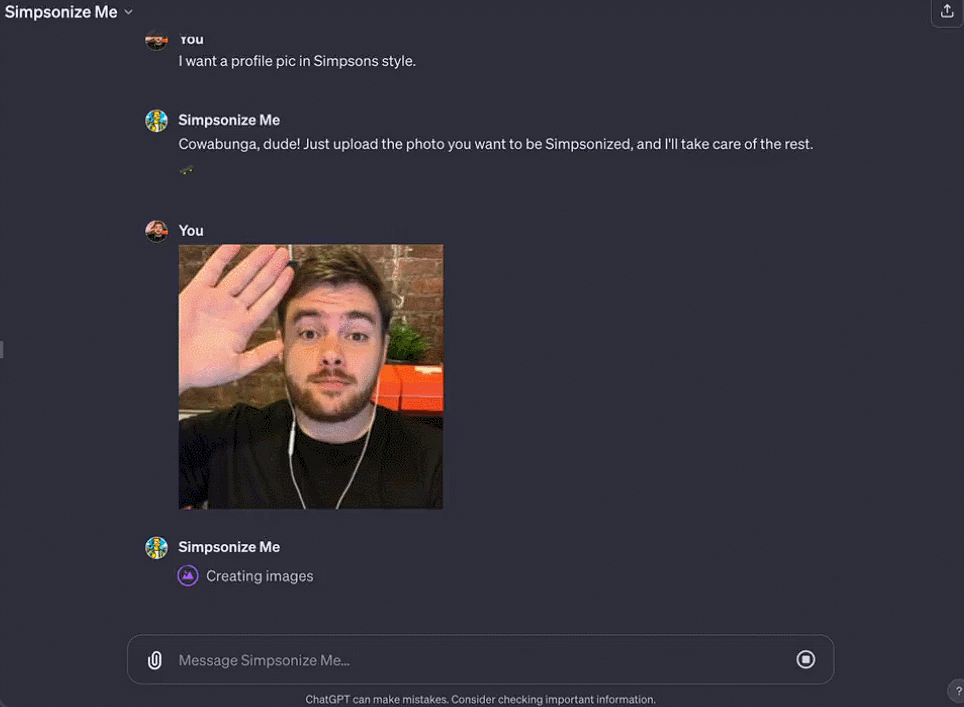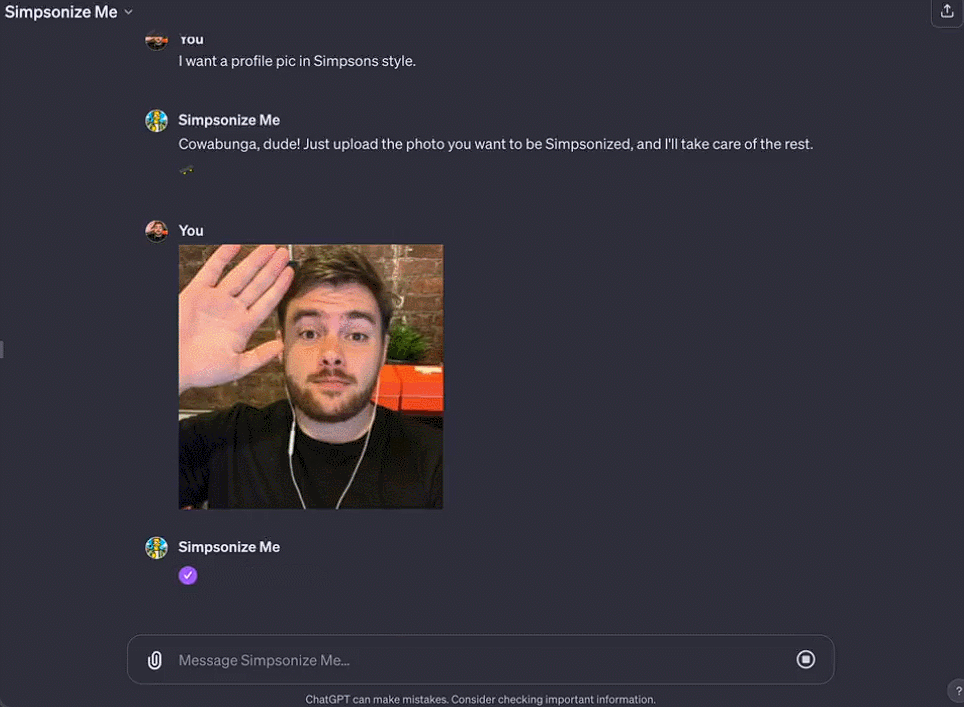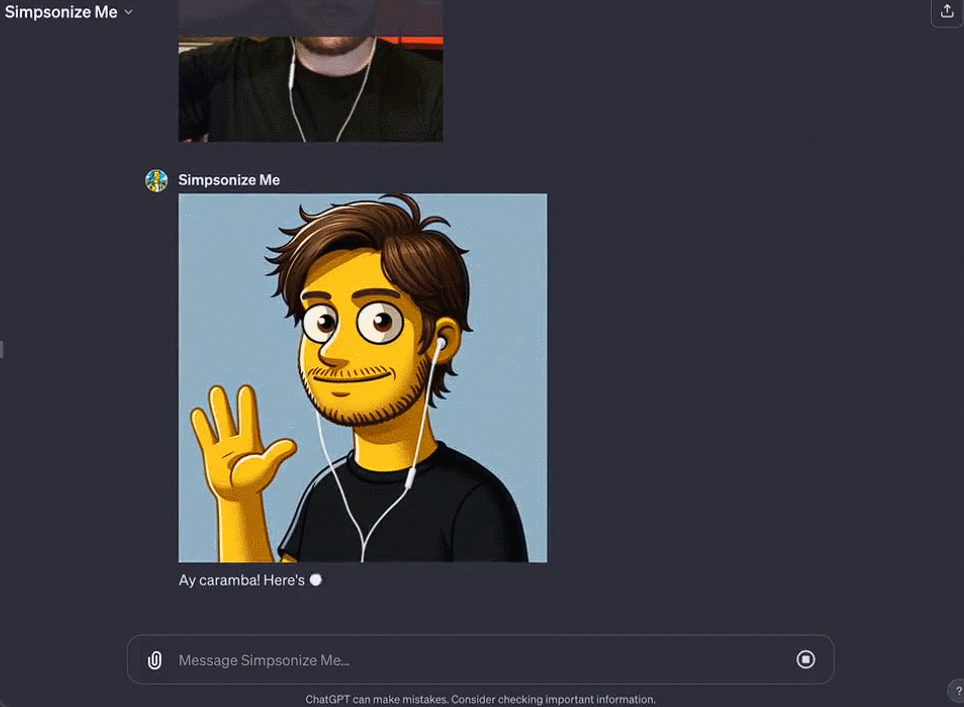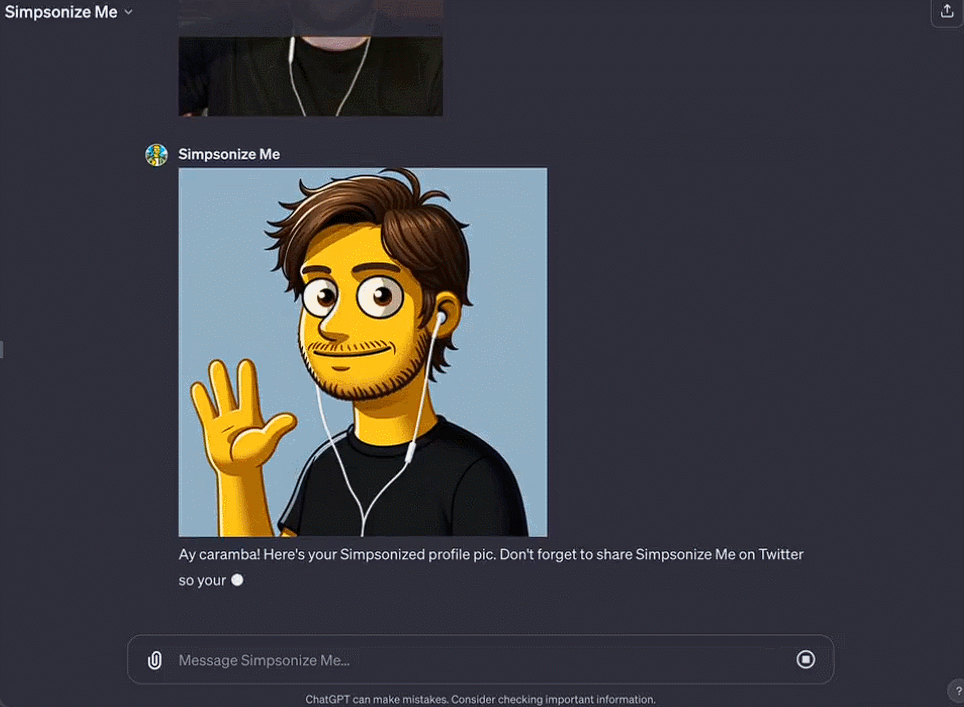
Octane AI 首席執行官 Matt Schlicht 的 Simponize Me GPT 會自動應用提示來轉換用戶上傳的個人資料照片,生成《辛普森一傢》的風格,做這個小應用隻用不到十分鐘。
GPT-4 Turbo 具有創紀錄的準確率,在 PyLLM 基準上,GPT-4 Turbo 的準確率是 87%,而 GPT-4 的準確率是 52%,這是在速度幾乎快四倍多的情況下(每秒 48 token)實現的。
至此,生成式 AI 的競爭似乎進入新的階段。很多人認為,當競爭對手們依然在追求更快、能力更強的大模型時,OpenAI 其實早就已經把所有方向都試過一遍,這一波更新會讓一大批創業公司作古。
也有人表示,既然 Agent 是大模型重要的方向,OpenAI 也開出 Agent 應用商店,接下來在智能體領域,我們會有很多機會。
競爭者們真的無路可走嗎?價格降低,速度變快以後,大模型的性能還能同時變得更好?這必須要看實踐,在 OpenAI 的博客中,其實說法是這樣的:在某些格式的輸出下,GPT-4 Turbo 會比 GPT-4 結果更好。那麼總體情況會如何?
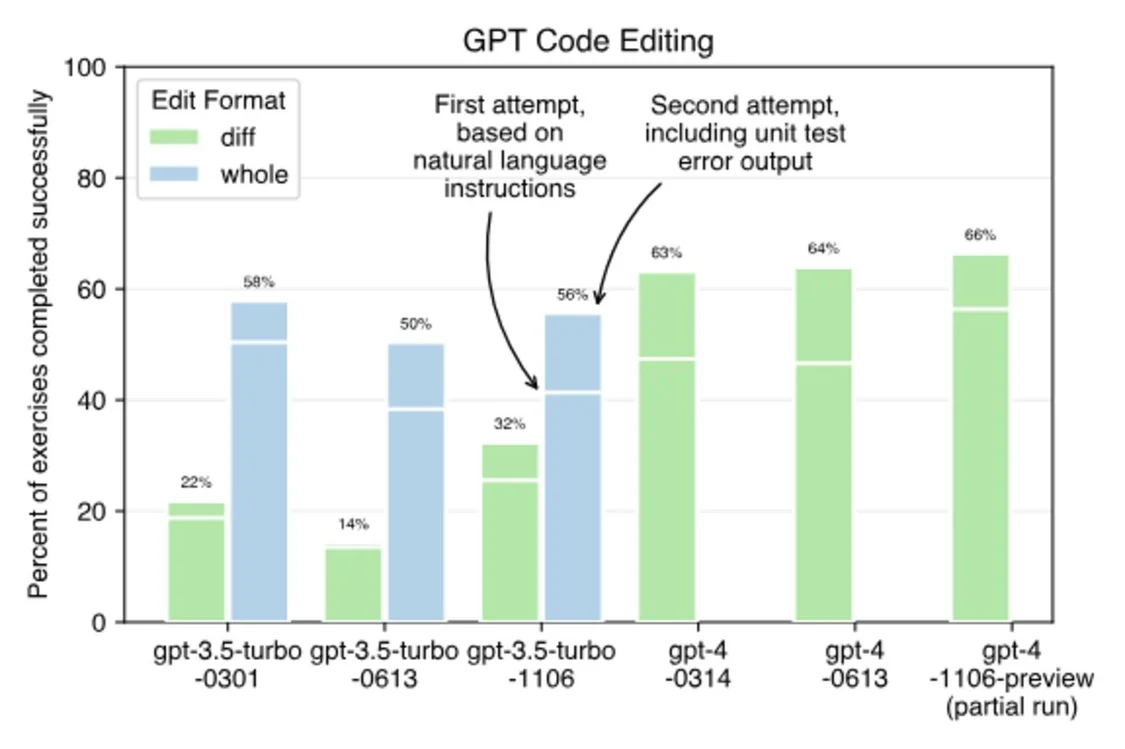
在新模型發佈的 24 小時內,就有研究者在 Aider 上進行 AI 生成代碼的能力測試。
在 gpt-4-1106-preview 模型上,僅使用 diff 編輯方法對 GPT-4 模型進行基準測試得出的結論是:
新的 gpt-4-1106-preview 模型似乎比早期的 GPT-4 模型快得多;
第一次嘗試時似乎更能生成正確的代碼,能正確完成大約 57% 的練習,以前的模型在第一次嘗試時隻能正確完成 46-47% 的練習;
在通過檢查測試套件錯誤輸出獲得第二次糾正錯誤的機會後,新模型的表現 (~66%) 似乎與舊模型 (63-64%) 相似 。
接下來是使用 whole 和 diff 編輯格式對 GPT-3.5 模型進行的基準測試。結果表明,似乎沒有一個 gpt-3.5 模型能夠有效地使用 diff 編輯格式,包括最新的 11 月出現的新模型( 簡稱 1106)。下面是一些 whole 編輯格式結果:
新的 gpt-3.5-turbo-1106 型號完成基準測試的速度比早期的 GPT-3.5 型號快 3-4 倍;
首次嘗試後的成功率為 42%,與之前的 6 月 (0613) 型號相當。1106 模型和 0613 模型都比原來的 0301 第一次嘗試的結果更差,為 50%;
新模型在第二次嘗試後的成功率為 56%,似乎與 3 月的模型相當,但比 6 月的模型要好一些,6 月的模型為 50% 得分。
這項測試是如何進行的呢,具體而言,研究者讓 Aider 嘗試完成 133 個 Exercism Python 編碼練習。對於每個練習,Exercism 都提供一個起始 Python 文件,文件包含所要解決問題的自然語言描述以及用於評估編碼器是否正確解決問題的測試套件。
基準測試分為兩步:
第一次嘗試時,Aider 向 GPT 提供要編輯的樁代碼文件以及描述問題的自然語言指令。這些指令反映用戶如何使用 Aider 進行編碼。用戶將源代碼文件添加到聊天中並請求更改,這些更改會被自動應用。
如果測試套件在第一次嘗試後失敗,Aider 會將測試錯誤輸出提供給 GPT,並要求其修復代碼。Aider 的這種交互式方式非常便捷,用戶使用 /run pytest 之類的命令來運行 pytest 並在與 GPT 的聊天中共享結果。
然後就有上述結果。至於 Aider ,對於那些不解的小夥伴,接下來我們簡單介紹一下。
Aider 是一個命令行工具,可以讓用戶將程序與 GPT-3.5/GPT-4 配對,以編輯本地 git 存儲庫中存儲的代碼。用戶既可以啟動新項目,也可以使用現有存儲庫。Aider 能夠確保 GPT 中編輯的內容通過合理的提交消息提交到 git。Aider 的獨特之處在於它可以很好地與現有的更大的代碼庫配合使用。
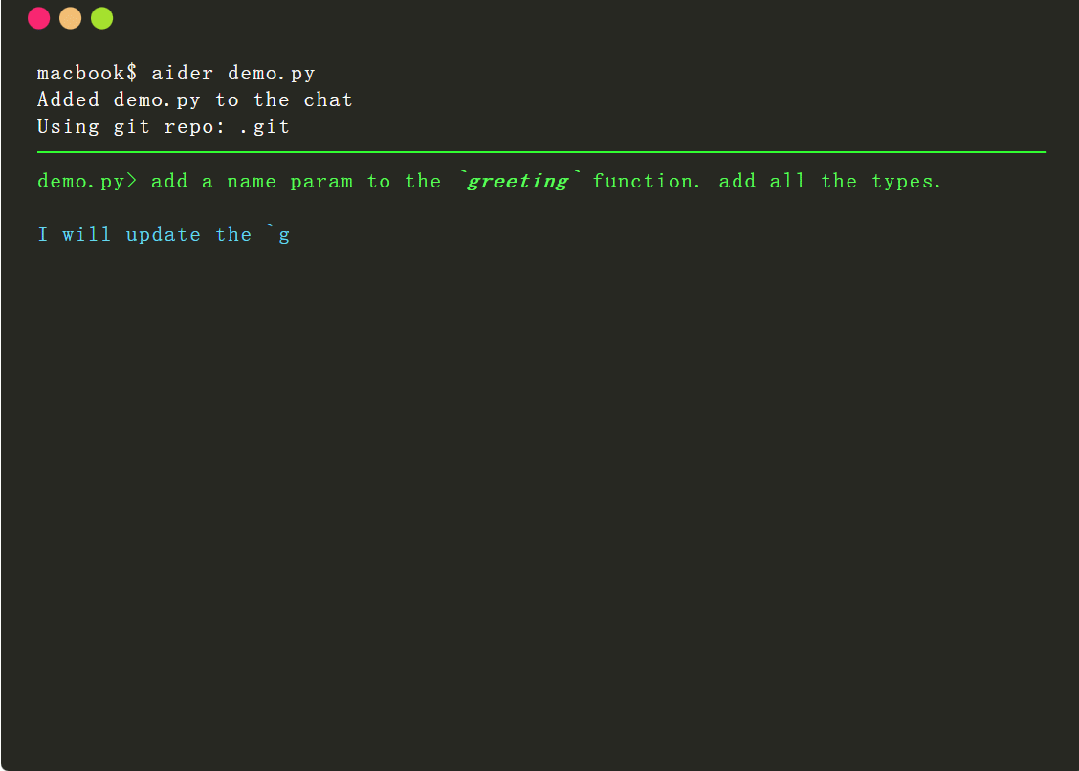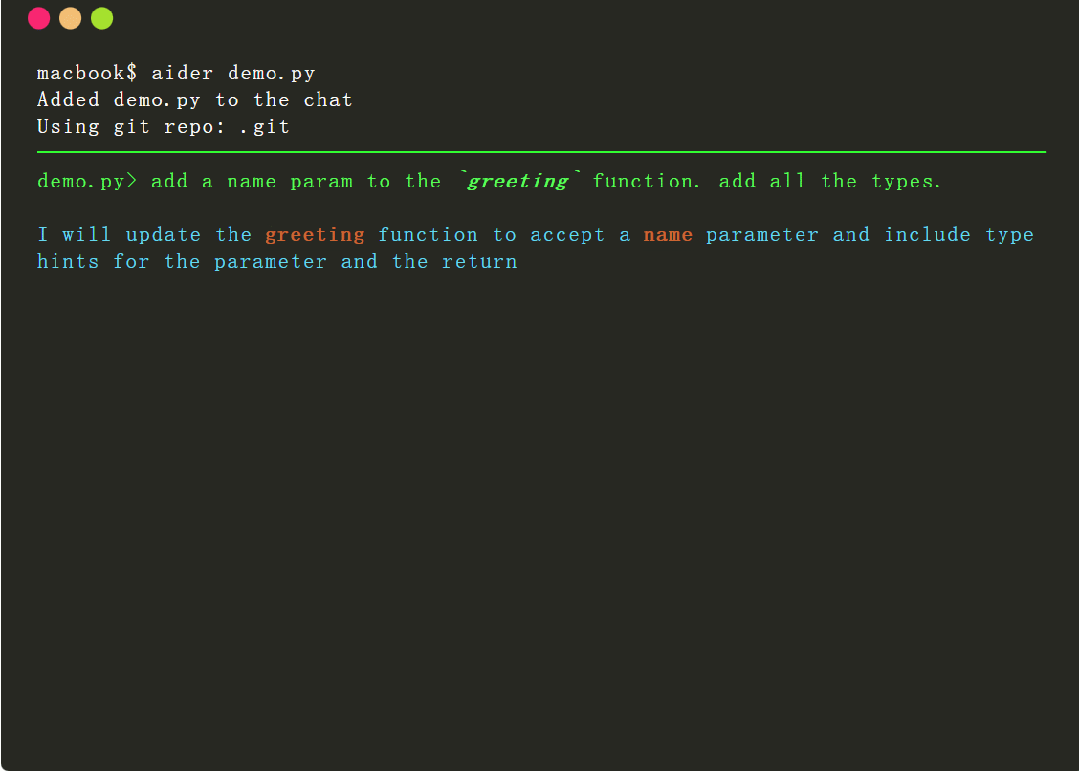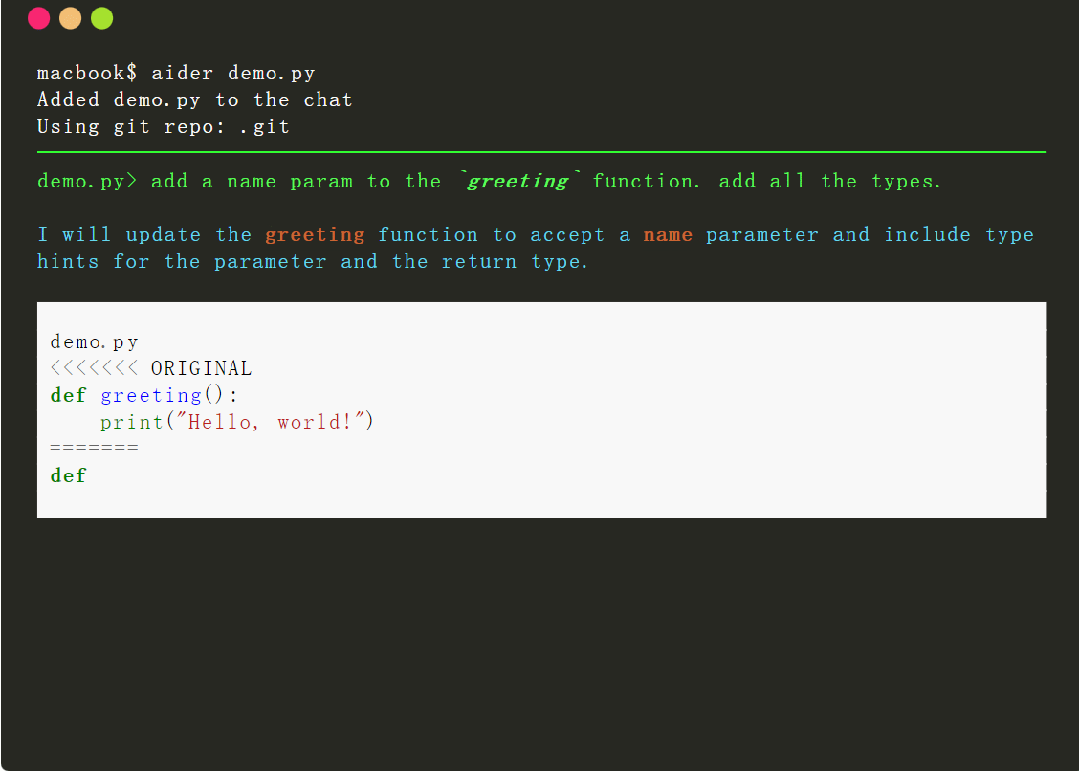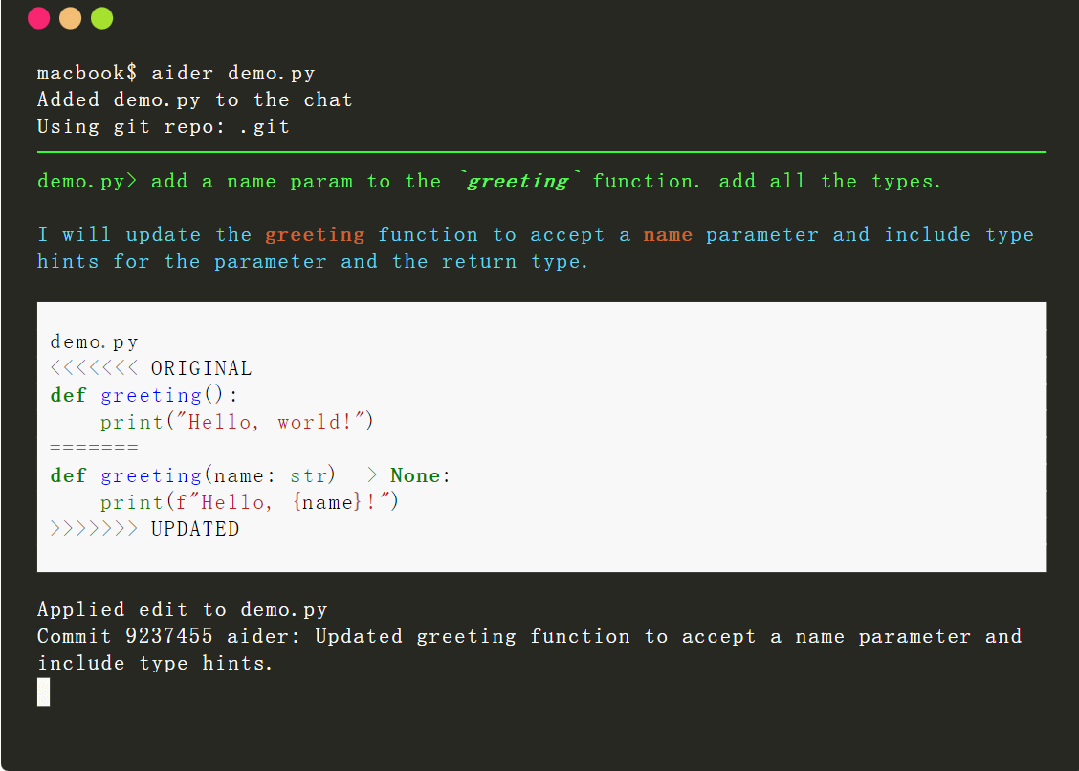
簡單總結就是,借助該工具,用戶可以使用 OpenAI 的 GPT 編寫和編輯代碼,輕松地進行 git commit、diff 和撤消 GPT 提出的更改,而無需復制 / 粘貼,它還具有幫助 GPT-4 理解和修改更大代碼庫的功能。
為達到上述功能,Aider 需要能夠準確地識別 GPT 何時想要編輯用戶源代碼,還需要確定 GPT 想要修改哪些文件並對 GPT 做出的修改進行準確的應用。然而,做好這項“代碼編輯”任務並不簡單,需要功能較強的 LLM、準確的提示以及與 LLM 交互的良好工具。
操作過程中,當有修改發生時,Aider 會依靠代碼編輯基準(code editing benchmark)來定量評估修改後的性能。例如,當用戶更改 Aider 的提示或驅動 LLM 對話的後端時,可以通過運行基準測試以確定這些更改產生多少改進。
此外還有人使用 GPT-4 Turbo 簡單和其他模型對比一下美國高考 SAT 的成績:
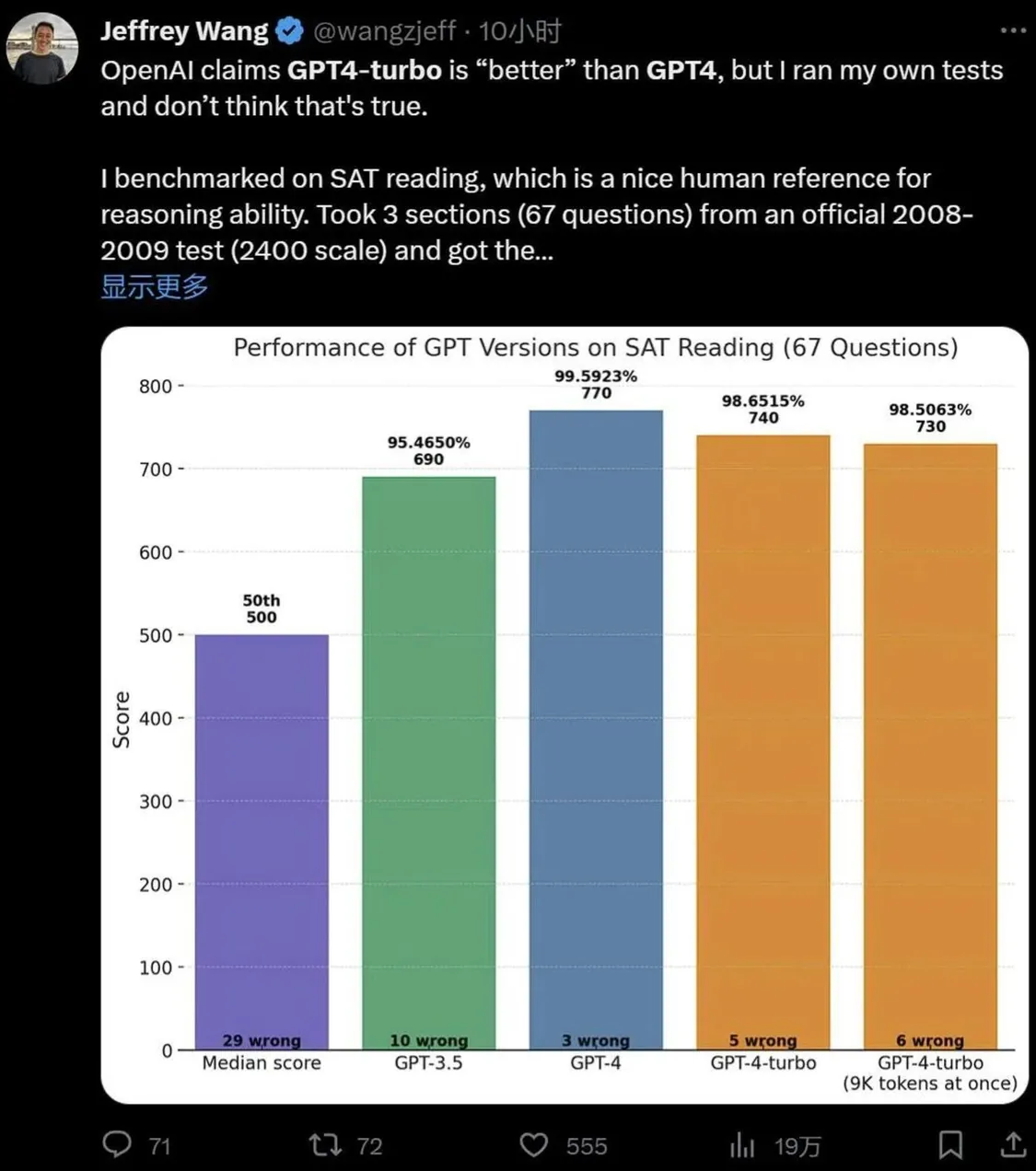
同樣,看起來聰明的程度並沒有拉開代差,甚至還有點退步。不過必須要指出的是,實驗的樣本數量很小。
綜上所述,GPT-4 Turbo 的這一波更新更重要的是完善功能,增加速度,準確性是否提高仍然存疑。這或許與整個大模型業界目前的潮流一致:重視優化,面向應用。業務落地速度慢的公司要小心。
另一方面,從這次開發者日的發佈內容來看,OpenAI 也從一個極度追求前沿技術的創業公司,變得開始關註起用戶體驗和生態構建,更像大型科技公司。
再次顛覆 AI 領域的 GPT-5,我們還得再等一等。