來自Google的研究人員發表一篇論文,稱他們創建一個從文本描述中生成高保真音樂的模型。它被稱為MusicLM,根據人工智能科學傢KeunwooChoi的說法,這個模型的整體結構是基於其他模型的,它結合MuLan+AudioLM和MuLan+w2b-Bert+Soundstream。
Choi解釋一下這些模型各自的工作原理:
MuLan是一個文本-音樂聯合嵌入模型,支持對比性訓練和來自YouTube的44M音樂音頻-文本描述對。
AudioLM使用一個來自語音預訓練模型的中間層來獲取語義信息。
w2v-BERT是一個來自Transformers的雙向編碼器表表達法,這是一個最初用於語音的深度學習工具,這次用於音頻。
SoundStream是一個神經音頻編解碼器。
Google將所有這些結合起來,產生從文本中生成音樂的AI模型,以下是研究人員對MusicLM的解釋。
MusicLM是一個從文本描述中生成高保真音樂的模型,如"平靜的小提琴旋律伴著扭曲的吉他旋律"。MusicLM將有條件的音樂生成過程作為一個層次化的序列到序列的建模任務,它生成的音樂頻率為24KHz,時長可以達到幾分鐘。實驗表明,MusicLM在音頻質量和對文本描述的遵守方面都優於以前的系統。此外,還可以證明MusicLM可以以文本和旋律為條件,因為它可以根據文本說明中描述的風格來轉換口哨和哼唱的旋律。為支持未來的研究,我們公開發佈MusicCaps,這是一個由5500首音樂-文本對組成的數據集,其中有人類專傢提供的豐富文本描述。
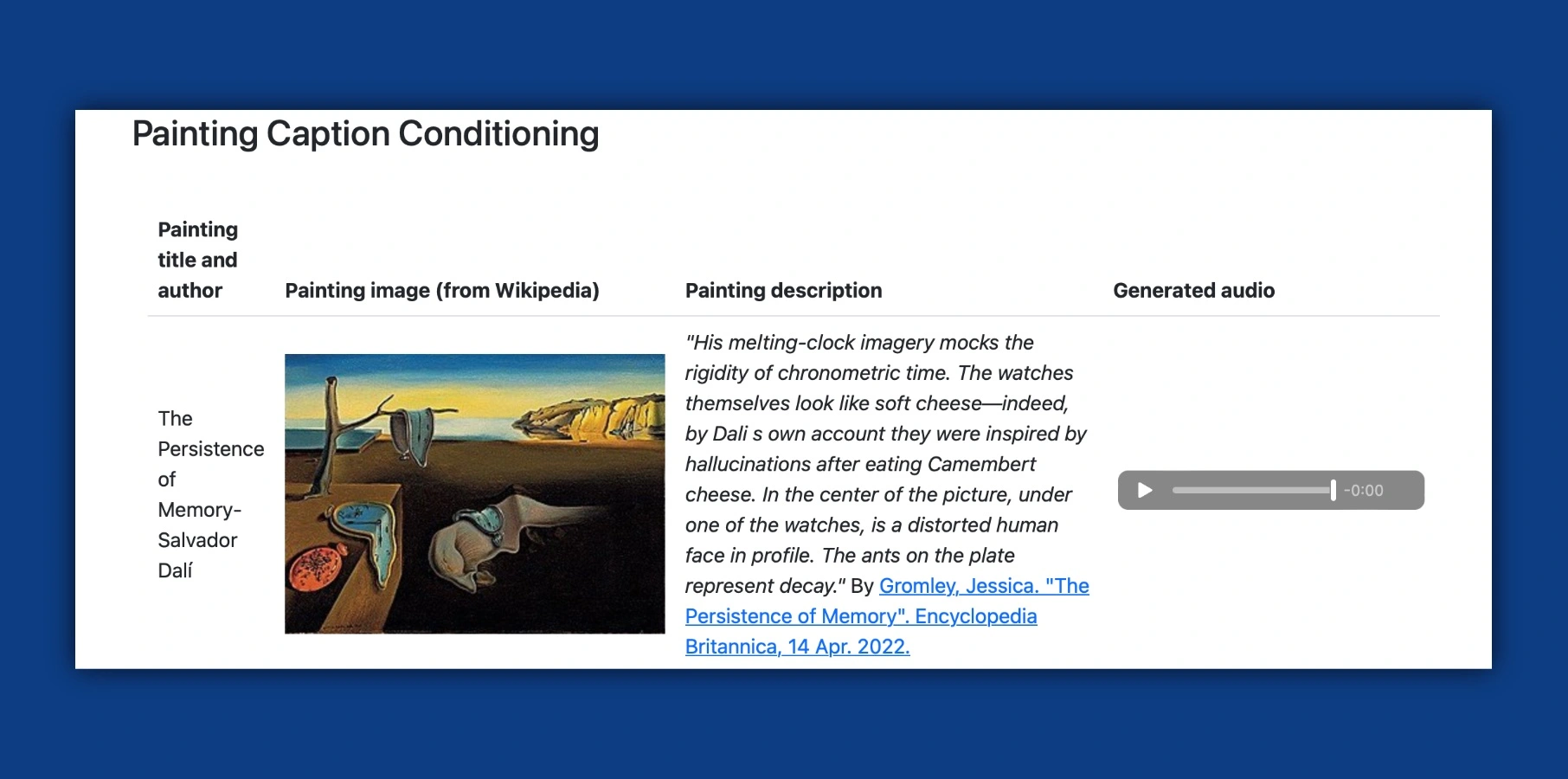
相對而言,想想ChatGPT能夠完成的事情就很有意思。艱難的考試,分析復雜的代碼,為國會寫決議,甚至創造詩歌、音樂歌詞等。在這種情況下,MusicLM更是超越前者,把文字意圖、一個故事甚至一幅繪畫轉化為歌曲。看到薩爾瓦多-達利的《記憶的持久性》被轉化為旋律,這很吸引人。
不幸的是,該公司並不打算向公眾發佈這種模型,但您仍然可以在這裡看看-和聽聽-這個人工智能模型如何從文本中生成音樂:
https://google-research.github.io/seanet/musiclm/examples/