“ChatGPT的意義不亞於PC或互聯網的誕生”,比爾蓋茨對這個新風口不吝贊譽。裁員潮下一片慘淡的矽谷,因為ChatGPT再次燃起希望之光。微軟斥資100億美元投資OpenAI,並計劃將ChatGPT融入旗下全線產品。2月4日,微軟融合ChatGPT-4的Bing已經短暫上線,速度之快讓人咂舌。
圖:融入ChatGPT的Bing
而為應對微軟激進的佈局,Google緊急地召回佩奇和佈林兩位創始人,並在上周也開始內測類似的產品Apprentice Bard。同時,Google還向OpenAI的競爭對手Anthropic投資近4億美元,以完成微軟和OpenAI類似的綁定。
中國科技公司也在紛紛跟進,一波類似於2016年AlphaGo的熱潮又一次掀起。
2月7日,百度公佈自傢類ChatGPT產品的名字“文心一言”,並預計在3月推出相應的產品。
2月8日,阿裡巴巴也透露,聊天機器人ChatGPT目前處於內測階段。
同日,網易有道CEO周楓也獨傢向光錐智能確認,網易有道未來或將推出ChatGPT同源技術產品,應用場景圍繞在線教育。
2月9日,騰訊也表態正有序推進ChatGPT和AIGC相關方向的專項研究。
一時間,不僅科技圈無人不談ChatGPT,甚至有不少人也開始用其面向普通用戶賺錢。瑞銀預測,ChatGPT的月活躍用戶在今年1月份達到1億,它完成這個目標隻用2個月,而在它之前,最快的TikTok大概花9個月,這讓ChatGPT成為迄今為止增長最快的消費者應用。
在此之前,AI產品更多是針對B端的產品,ChatGPT也打破to B到to C的圈層壁壘。
當然,ChatGPT的偉大,更重要的還是它讓通用型人工智能進一步成為可能,並降低這項技術的進入門檻,讓更多開發者能夠以低成本的方式在ChatGPT的基礎上開發專屬應用,讓AI改造世界的可能性進一步提升。
可以說,就像25年前剛剛萌芽的互聯網正準備對全球帶來翻天覆地的變革一樣,如今ChatGPT的出現,讓AI成為新一輪技術爆發的奇點成為可能。
但是,光錐智能在和中國人工智能行業從業者交流後,發現不少技術從業者反而不如圈外如此狂熱。這是因為,漸進式技術進步到今天,並非一蹴而就,技術從業者一直都在保持著密切的觀察和技術跟進。
ChatGPT很牛,但不要神化它。
一、矽谷隻剩AI
談起ChatGPT,我們仍然要從矽谷開始。和互聯網、Web3、元宇宙等之前大多數具有革命或非革命意義的技術突破一樣,ChatGPT仍然來自於矽谷。
但和之前矽谷各項技術方向百傢爭鳴不同,這個時間點的ChatGPT更像是矽谷沒有選擇的選擇。
2022年,矽谷就經歷一波大裁員,並波及幾乎所有的科技公司。到2023年2月,雖然冬天的氣溫已經有所回升,但矽谷的寒意卻還沒有褪去。
據trueup.io統計數據,在2023年剛剛過去的這一個月,全球326傢科技公司累計裁掉106950萬人,其中大頭都在矽谷,而且打擊面還非常廣泛,元宇宙、芯片、自動駕駛和SaaS都是重災區。
一直以來,裁員都是一個行業不景氣的直接表現。
以Wbe3為例,Coinbase在2023年1月計劃裁掉公司20%的員工,這是美國第一傢上市的合規加密交易平臺,且這傢公司已經在去年6月裁掉18%的員工。
研究公司PitchBook的數據顯示,在2022年第四季度,Wbe3行業的風險投資就已跌到這兩年以來的最低水平,比2021年同期下降75%。
在芯片領域,美光、格羅方德、英特爾等巨頭無一幸免,其中泛林集團裁員1300人,因特爾下調包括CEO在內的管理人員薪酬,並裁員數百人。SaaS領域,Salesforce在1月4日宣佈裁員8000人,約占全體員工的10%。自動駕駛方面,包括Waymo、Crusie、圖森未來、無人車配送公司Nuro都有裁員的消息傳出。
除此之外,曾經被傾註下一代互聯網希望的元宇宙也終於走到拐點。
去年11月,Meta確認成立18年來首次大規模裁員,紮克伯格向被裁員工道歉,“我錯,我要為此次裁員,以及我們是如何走到今天這個地步負責。”
投資人也不再看好Meta的元宇宙未來,美國投資公司Altimeter Capital向Meta發表公開信,呼籲公司削減20%的員工成本,並將“元宇宙”項目的支出限制在每年50億美元。
而相比於一頭紮入元宇宙之後又船大難掉頭的Meta,涉足稍淺的微軟則果斷選擇棄舊從新。
首先,微軟對元宇宙相關業務進行大刀闊斧的裁剪,其宣佈將在3月10日關閉2017年收購的社交平臺AltspaceVR,並有可能擺脫混合現實工具包(MRTK)團隊。
同時,微軟又在AI方面大力投入。1月初,微軟就計劃向OpenAI投資100億美元,然後宣佈要將包括Bing搜索、Office、Azure在內的旗下全線產品整合ChatGPT。到2月7日,微軟已經在Redmond召開整合ChatGPT的Bing發佈會。
其實從ChatGPT面世第一天開始,ChatGPT顛覆傳統搜索的觀點就已經不脛而走。所以面對微軟激進的佈局,Google2月6日宣佈推出一款聊天機器人Bard來與ChatGPT競爭,Google雲計算部門也在開展一個名為“Atlas”的項目。
2月7日,Google向ChatGPT的競爭對手Anthropic投資約3億美元,獲得10%的股份,這讓Google和Anthropic形成類似微軟與OpenAI的綁定關系。
除Google和微軟之外,在ChatGPT上線前三個月,Meta其實也曾發佈過一款類似的聊天機器人,隻是並沒有獲得太多影響力。用Meta首席人工智能科學傢雅恩・勒昆(Yann LeCun)的話說,“Meta的Blenderbot讓人覺得很無聊”。
相應的,亞馬遜也已經將ChatGPT應用到包括回答面試問題、編寫軟件代碼和創建培訓文檔等工作職能中。一名亞馬遜員工在Slack上表示,亞馬遜雲部門已經成立一個小型工作組,以更好地解人工智能對其業務的影響。甚至,連蘋果都宣佈要在下周召開內部AI峰會。
如今的矽谷,AI已經成為絕對C位。
這種轉向其實也表現在投資機構的動態上,2021年12月,紅杉資本將自己在Twitter上的簡介從“幫助有冒險精神的人創建偉大的公司”改成“從想法到落地,我們幫助富有冒險精神的人打造偉大的DAO。”2022年,Web3賽道火熱,紅杉在2022年1月1日-4月26日,以大概每周一傢的速度投資17傢Web3公司。
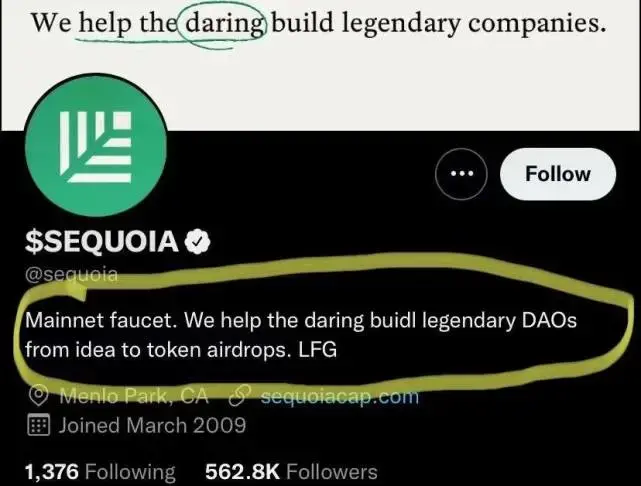
但變化發生在去年9月,紅杉資本發佈一篇文章《生成式AI:一個創造性的新世界》。其中寫道,生成式AI有可能創造數百萬億美元的經濟價值。
PitchBook的一項統計數據顯示,2022年投資圈向生成式AI公司共投入13.7億美元(折合人民幣約93.69億元),幾乎達到過去5年的總和。這些投資中不僅包括OpenAI、Stability AI這樣的頭部企業,也包如Jasper、Regie.ai、Replika等初創企業。
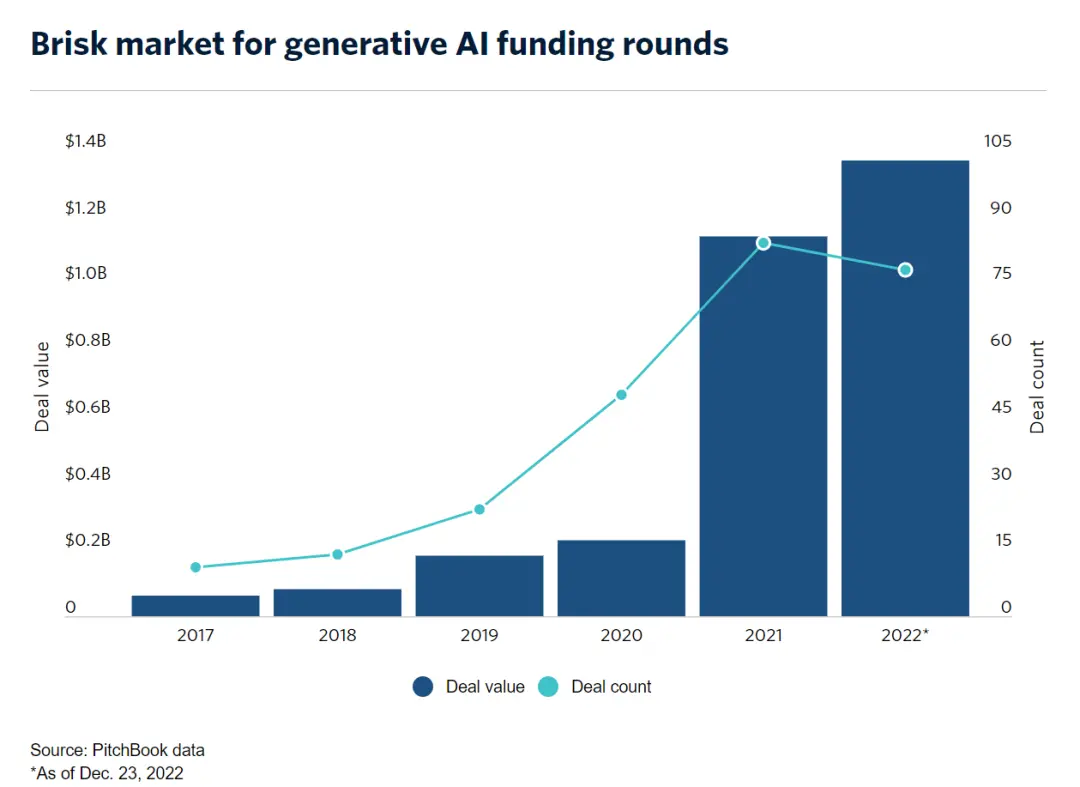
整體上,從投資人到大企業,再到創業者,一場關於AI 2.0的大幕已經拉開。
二、中美差距沒那麼大
從矽谷到中國,ChatGPT的熱度有增無減。
畢竟一直以來,關鍵的技術革新都發生在矽谷,這兩年中國尖端技術又一直面臨卡脖子的問題。所以在ChatGPT出現之後,大傢最關心的還是當國外技術已經開始商業化落地的時候,國內的進度到底如何,差距又有多少?
2月7日,百度對外公佈自傢類ChatGPT產品的名稱“文心一言”,英文名叫ERNIE BOT,目前,文心一言正在做上線前的沖刺。
“文心一言”一經透露,便迅速登上各大平臺熱搜,百度股價一度漲超17%,市值增長約700億港元。很明顯,市場對於一個中國版的ChatGPT已經期待太久。
之前,有觀點認為國內外差距大概在兩年左右。但雲知聲研發副總裁劉升平認為,實際上的差距可能沒有這麼遠。兩年的說法是因為GPT-3是在兩年前公佈的,但其實自GPT-3發佈之後,國內許多企業就已經跟進在做類似的大模型。“實際差距並沒有那麼大,大概在一年左右。”
小冰公司CEO李笛也向光錐智能提到:“國內人工智能技術不像芯片、操作系統一樣落後於國外,相反它應該是最接近國際的。”
“國內外的差距主要是一種思維上的差距。”李笛認為,國內對技術創新這件事鼓勵得不夠充分,如果一個公司耐得住寂寞,那它無論在哪個方向都是OK的。
事實上,國內大廠基本都具備訓練大模型的能力。比如百度這次發佈的文心一言,就和百度文心大模型一脈相承。
百度在發佈文心一言名字的時候還特意提到,在人工智能四層構架中有全棧佈局,包括底層芯片、深度學習框架,大模型以及最上層的搜索等應用。擁有產業級知識增強文心大模型ERNIE,具備跨模態、跨語言的深度語言語義理解與生成能力。
同樣的,騰訊也有類似混元AI大模型,在此基礎上,騰訊推出HunYuan-NLP 1T大模型並一度登頂國內最權威的自然語言理解任務榜單CLUE。此外,像阿裡有“通義”大模型,華為有盤古大模型,國傢隊中科院自動化研究所有“紫東·太初”等等。
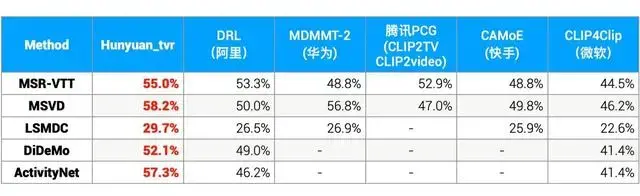
簡單來說,國內大廠基本都有做NLP預訓練模型的能力,甚至許多專業能力還處在世界領先的水平。
比如騰訊的混元大模型在2022年11月公佈一項最新進展,它們實現萬億級NLP模型,可以用256張卡,最快1天內完成訓練,成本相比原來降低1/8。
作為對比,ChatGPT訓練一次的成本高達1千萬美元,這是一般企業無法承受的。小冰公司CEO李笛算過一筆賬:“如果按照ChatGPT成本來考量的話,每天我要燒3億人民幣,一年要燒一千多億。”
而騰訊通過課程學習、MOE路由算法、模型結構等方式優化之後,讓更多企業能夠承擔得起訓練自己的NLP模型的成本。
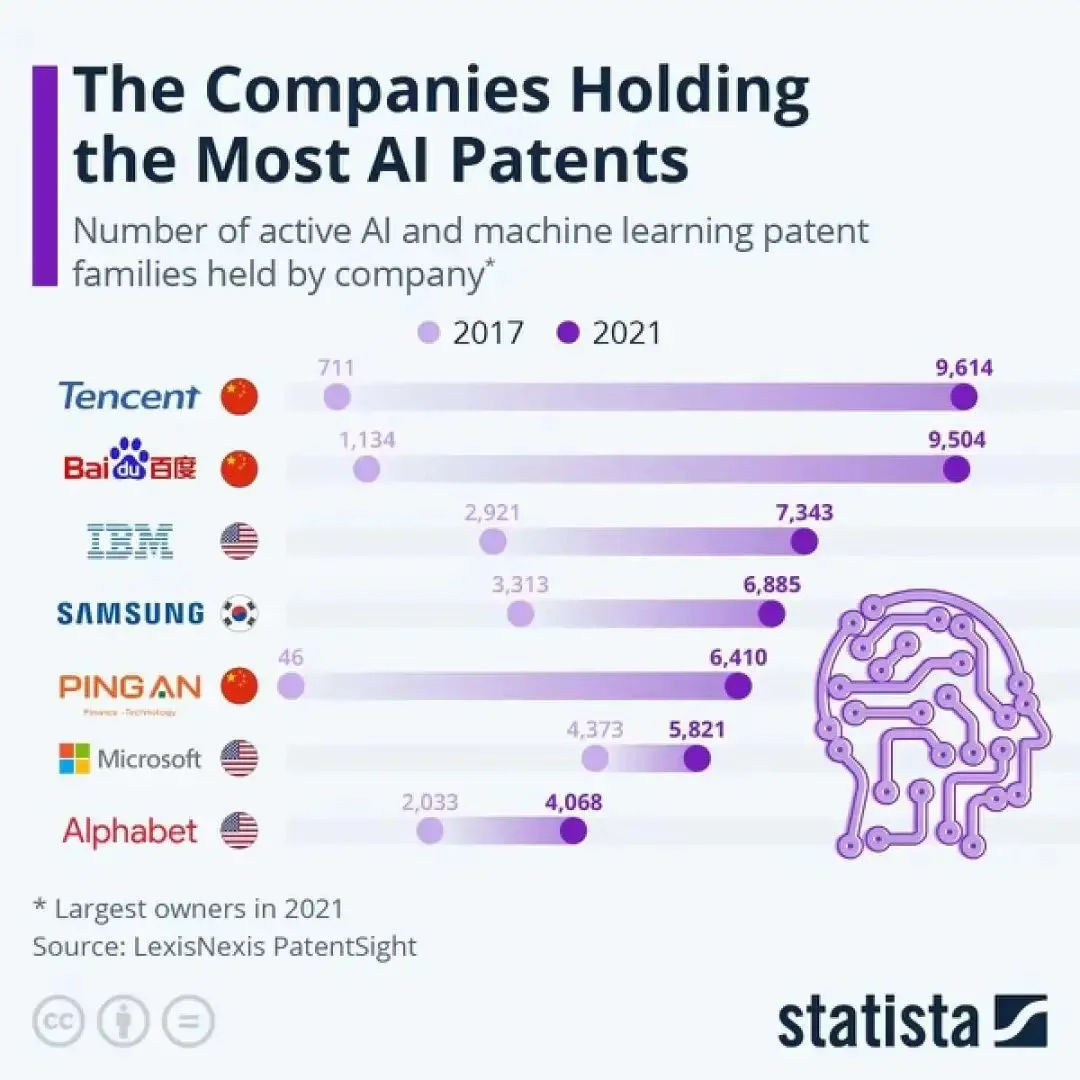
除此之外,像在專利儲備上,根據statista2021年的數據,百度和騰訊都名列世界前列。
另一方面,就ChatGPT而言,它的技術原理並不新鮮。
Yann LeCun提到:“就底層技術而言,ChatGPT並不是特別創新的,它不是革命性的,盡管這是公眾對它的看法。”他指出,除Google和Meta,還有6傢初創公司基本上擁有與它非常相似的技術。ChatGPT是一項集體努力,因為它匯集多方多年來開發的多項技術。
李笛也提到,大模型對應的技術理念已經誕生好幾年,無論是國內還是國外,使用這種技術理念訓練出來的大模型已經很多,隻是在具體fine tune(微調)的過程中專註的領域有所不同。
做個不恰當的比喻,ChatGPT就像原子彈一樣,它的原理已經被寫在教科書裡,而大多數國傢仍然無法實現,更多是因為工程性的問題。比如千億規模的數據從哪裡來?如何進行數據標註,具體標註哪些數據,標註多少,這些數據又如何進行組織訓練等等。
而這些問題也都沒有在OpenAI的論文中得到公佈,需要企業在自己的模型訓練中去嘗試和摸索,然後形成經驗,積累成自己的know-how。
三、不要神化ChatGPT
雖然在底層技術上,國內外其實並沒有想象中那麼大的差距。但當大傢看到國外如火如荼的技術落地時,也會擔心國內在這方面掉隊。
對於ChatGPT這樣技術邏輯清晰的產品而言,慢一點並不影響結果。但如果產品差,則表現在具體工程問題的解決能力上,這些部分要摸索,要踩坑,要形成經驗都需要漫長的時間,這背後反映的是技術水平的問題。
相比於歐美以英文為主的語言環境,中文是表意文字,在抽象概括和邏輯能力上天生不及英文。除此之外,國內互聯網的語料也相對缺乏,沒有英文互聯網那麼大的數據積累。
所以有業內人士表示,對目前國內的類ChatGPT產品發展而言,重要的不是模型,而是數據。
“自然語言處理需要經過一個非常嚴密的推理過程。”李笛提到:“大模型某種意義上代表一種暴力,即把大量的數據壓縮到一個黑盒裡面,然後提取出來,這意味著大傢在算力有一定保障的前提下,可以有機會用之前沒有用過的方法去完成。”
另一方面,ChatGPT確實是革命性的存在,但卻並不代表它就是今後NLP領域的唯一方向。
首先是ChatGPT的技術發展,今天最主要的技術在於,一個模型建壓好之後,如何從裡面很好地提取數據,目前還有很多新方法沒有嘗試,所以不排除未來用更小的模型達到很好效果的可能。
李笛提到,現在整個行業都在追求這種可能,因為模型參數太大,一定意味著成本非常高,以及各種各樣的其他問題。“今天技術差異還遠遠沒有達到成為不同技術流派的程度,也還遠遠沒有到說就按應用場景去劃分這樣一個程度。”
其次是從整個NLP的技術路線來看,目前主要有兩種主流技術路線,分別是以GoogleBERT為代表的雙向預訓練語言模型+fine-tuning(微調),和以OpenAI的GPT為代表的自回歸預訓練語言模型+Prompting(指示/提示)。
在ChatGPT發佈之前,BERT一直是業內主流的技術方案,它之所以被ChatGPT搶風頭,是因為它無法像GPT一樣用一個模型解決所有問題,沒有表現出通用型人工智能的潛力。
但實際上,BERT在許多具體的場景下擁有優勢,比如在特定場景下,BERT可以用更小的數據量(ChatGPT是在3000億單詞的語料基礎上預訓練出的擁有1750億參數的模型),更低的訓練成本實現同樣的性能。
比如在醫院內部這樣一個特定場景,一方面它用不起千億規模的模型,ChatGPT在醫院場景就屬於殺雞用牛刀,醫院也無法負擔部署ChatGPT的成本。另一方面,ChatGPT的模型是基於公開數據訓練的,但醫院的數據並不存在公共網絡上,所以面對醫院的問題,ChatGPT可能無能為力。
但BERT卻能夠適應這樣的場景,它可以以更小的數據量,更低的成本,針對醫院的數據和場景針對性地訓練出的模型,在解決具體問題上比ChatGPT更加得心應手。
這其實就是一個所有領域都涉獵的全能型選手和深耕特定領域的專傢之間的區別。即在數據確定的特定場景,BERT更有優勢。而在沒有明確數據和目標,面向開放式的應用場景,ChatGPT則更合適。
當然,具體到國內企業的商業化來說,大模型需要大量的數據,高昂的訓練成本,這些都不是一般企業能夠承擔的,因此它註定是巨頭的遊戲。
在騰訊研究院近期發佈的《AIGC發展趨勢2023》報告中就梳理目前AIGC產業生態體系的三層構架,包括以預訓練模型為主的基礎層;以垂直化、場景化、個性化模型為主的中間層;和以圖像、語音、文字生成等具體AIGC應用為主的應用層。
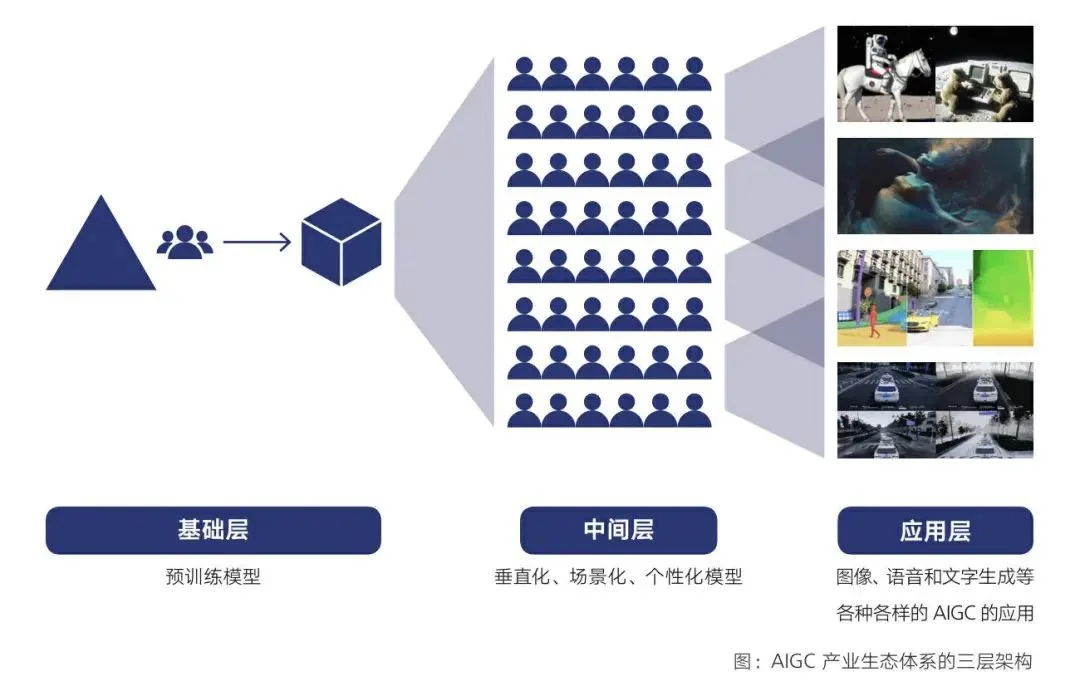
圖:騰訊研究院《AIGC發展趨勢2023》
其中,如百度、騰訊、OpenAI這樣的大公司將專註於做預訓練模型,對這些企業來說,他們一方面能夠將大模型的能力整合到自己的產品線中,直接面向廣大的用戶;另一方面又能夠通過API為中小企業提供能力調用,在具體場景中落地。
面對這樣的生態架構,一位知名機構投資人在考察過矽谷的ChatGPT項目後向光錐智能表示:“創業公司的機會在於,在開源技術的基礎上,做具體的應用場景。尤其是可以把幾種具體技術結合在一起,比如數字人和ChatGPT結合,自動生成視頻,用於金融、客服等特定場景下的應用。”
但這也會面臨一些問題,即如果大傢都調用同一個模型的能力,又落地在同一個細分場景,那必然會面臨同質化的問題。
所以劉升平認為:“ChatGPT適合創業公司進入市場初期的冷啟動,即通過ChatGPT提供服務,然後逐步積累數據,待有一定數據積累之後再利用BERT訓練專用模型,以此來建立自己的技術壁壘和護城河,同時也提供差異化的服務,和同行拉開差距。”
所以,無論是從技術,還是從商業化的角度而言,ChatGPT和BERT從來不是一個非此即彼的問題,而是一個術業有專攻的問題。
此外,劉升平也提到,對於中小公司而言,如果沒有能力去研發類似ChatGPT的通用大模型,那也可以考慮研發類似ChatGPT的行業版模型,用更少的參數量,更多的行業數據,在行業問題上達到或超過ChatGPT的效果。
“我認為到目前為止,人工智能在To C和To B上尚未出現一個放之四海而皆準的商業模式。”
李笛提到,AI現在還出其實還處在一個相對比較早期,甚至可以稱之為蠻荒時代,很多理念都還處在特別特別原始的狀態,所以可能每年我們回顧過去,都會覺得在顛覆自己。
“就像前幾年NIIPS大會上有人開玩笑說過的大模型煉丹,現在的大模型就像大傢拿到一個好的玩具,但不知道這個玩具還能吐出什麼令人驚訝的東西。”
在2016年,AlphaGo擊敗李世石時,我們也曾以為AI時代已經來臨,它會在許多領域將人類替代掉,我們也曾為此恐慌和興奮,但實際上如今將近10年過去,AlphaGo並沒有改變世界,甚至沒有改變任何人。
所以,何妨讓子彈再飛一會兒呢?