日前,AMD對華AI芯片特供版“MI309”暫未拿到美國商務部BIS出口許可的消息不脛而走。據稱,AMD效仿英偉達,對原版MI300系列的規格參數做調整以符合去年10月份BIS的管制新規,但卻仍被美國商務部以“性能過強”為由攔下。
去年10月的美國商務部對華高性能芯片禁令,在2022年版的“傳輸帶寬”和“總體處理性能”這兩個指標上又做迭代化的管制處理,取消傳輸帶寬限制,新增性能密度指標,即要看芯片的總體處理性能除以裸片面積,以此作為計算方法作為評估出口許可證的基準。新規之下,英偉達對華特供版A800和H800也不再符合性能密度指標要求,連面向消費類的RTX4090顯卡也不在豁免范圍內。面對這個局面,有理由推斷AMD的這款魔改版AI加速器在申請出口許可之前應該通過企業內部合規部的審查,但卻依然碰壁。
目前業界對此事的解讀大多集中在兩個層面,一是強調美國商務部BIS有“口徑彈性”,是否給出口許可不完全按照紙面規定的門檻,一個是從應用場景上解讀,強調美國對華AI芯片算力的遏制,卡人工智能大模型的升級。
誠然,這兩個解讀維度都有很強的說服力。但如果考慮到美國商務部半年多以來對華半導體技術路線調研的焦慮,尤其是華為Mate60的上市,代表中國本土芯片工藝制程的重大突破,美方對此事的一系列反應,AMD的“MI309”暫時被禁背後或許還有另一個位面。
AMD MI300系列和英偉達H100的差異化
英偉達“閹割版”的H800被禁和AMD“閹割版”MI309被禁是不是完全算同一回事?是否可以用同一種思維框架去解讀?對此我們不妨來看看二者在設計理念上的一個明顯區別。
2023年12月,AMD發佈最新MI300X GPU芯片,基於最新一代CDNA3計算架構,集成8個5nm工藝的XCD模塊,同時還有四個6nm工藝的IOD模塊和256MB無限緩存,將HBM 2.5D先進封裝與 3D V-Cache技術結合,誕生一個營銷術語“3.5D”封裝。可以說,MI300X一共有12個Chiplets,其中4個IODs在最底層,集成8顆CDNA-3架構GPU(4 SoC die的Chiplets)與另外4個I/O die,如下圖:
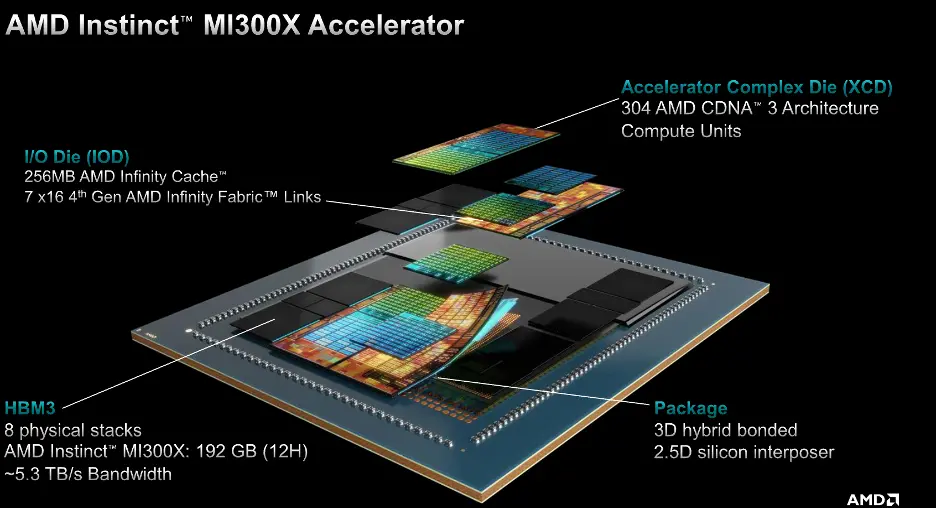
而英偉達則選擇繼續在單片矽上深耕GPU,H100沒有采用Chiplet技術,背後的原因也並不復雜。在黃仁勛看來,die際之間的通訊帶寬依然不能和傳統Monolithic內部通信帶寬相比,在高AI算力場合以及高端消費級顯卡領域,英偉達為保證傳輸的低延遲性,寧可承受高成本、相對較低良率的代價,也要堅持走大芯片GPU路線。
當然,Chiplet技術的采用深度關系到die size即打破“光罩墻”與晶體管密度問題。AMD的MI300X僅采用5nm與6nm結合,就可以把die size做到超過1000平方毫米,並將晶體管密度堆到超過1.5億每平方毫米。除此之外,在更廣闊的視角上,Chiplet技術導向著事關產業生態的重大革新。
Chiplet的初心,從美國軍方談起
2017年9月,美國國防部高級研究計劃局(DARPA)官方網站上,突然出現一則以“異構整合推動Chiplet發展”的新聞,吹皺行業一池春水。DARPA表示,CMOS技術雖然實現數字、模擬和混合信號模塊的SoC集成,但也導致和芯片設計、制造相關的成本的不斷推高,而美國國防部的預算無法承受單片SoC成本帶來的急劇上升,為強化芯片設計系統的靈活性,並減少芯片迭代的設計時間,需要找到一個“IP復用”的新范例。
主持這項計劃的項目經理丹·格林(Dan Green)當時表示,Chiplet可以將芯片設計與制造的思維方式、技能、技術優勢和商業利益混合搭配。“如果計劃成功,我們將獲得更廣泛的專用模塊,我們將能夠更輕松地以更低的成本集成到我們的系統中。這對於商業和國防部門來說應該是雙贏。”
一言以蔽之,美國國防部的軍用這一特殊應用場景,無法讓其供貨的供應商走“走量”模式,如何降低采購成本,是DARPA開啟Chiplet項目的初心。最初加入該計劃的主承包商包括四傢主要的半導體公司英特爾、美光科技,和兩傢EDA公司新思科技和Cadence,除此之外還有一些軍用芯片承包商。拋開半導體產業這個圈子不談,至少從美國軍方看來,解決“摩爾定律”逐漸失效的問題,以及如何降低芯片設計成本,需要做到芯片性能與芯片工藝的解耦,Chiplet是代表一種“省錢”的技術路線。
之後的幾年,從芯片設計端到制造封裝端的國際巨頭,雖然切入到Chiplet技術的具體錨點各不相同,但參與其中的動機則契合美國DARPA的想法。比如高帶寬存儲HBM是與GPU封裝在一起,這主要由晶圓代工廠完成,臺積電把2.5D封裝中的中介層(interposer)當技術突破點,把不同工藝節點的die混封,加快新工藝芯片的上市時間,無論英偉達的2.5D還是AMD的3.5D,都讓臺積電收益巨大。
從作為買方市場的DARPA入手看Chiplet當初被推廣的理念,我們發現它指引一種產業生態演化的理想狀態,即在一個無限廣闊,完全自由開放的Chiplet市場上,客戶就像廚子在菜市場采購食材一樣,自由mix-and-match,IP可以復用,不同工藝節點混搭,研發成本分攤,也可以帶動IP和EDA賽道的創新。
AMD與Chiplet
回到AMD對華定制化AI加速器被阻的這件事本身,我們有理由推斷,AMD在Chiplet之路上走的“過快”,反而引發美國出口管制政策制定者的忌憚。因為,相比英偉達和英特爾,AMD真正引領Chiplet商用落地的成熟和生態建設,並且在有限范圍裡部分實現DARPA的那種自由開放的樣態。
AMD的EPYC處理器經過代號為那不勒斯、羅馬、米蘭和熱那亞等多次迭代,有效形成CCD Die和I/O Die分割演進的打法,為減少成本也采用不同代工廠的分散佈局,把相對工藝不那麼高的I/O Die扔給格芯,而需要先進工藝的CPU和3D V-Cache讓臺積電代工,其他產品線如Ryzen系列也可以復用CCD模塊,降低研發費用。

AMD CEO Lisa Su 曾表示:Chiplet可以作為一個平臺,讓第三方IP導入更容易
不過,目前Chiplet距離理想中的藍海還有很長的路要走,這是業界多年來長期討論的焦點。如die to die的互聯標準問題,Chiplet先進封裝帶來的供電和散熱問題,以及DTCO理念(協同設計)理念所要求的聯合設計、驗證和測試難題,考驗著EDA工具的適配度。
Chiplet,一片混沌的藍海
從產業上下遊生態整合的角度來看,可以參考中興微高速互連總工程師吳楓的一段分析。他在去年芯和半導體用戶大會上發表以“算力時代的Chiplet技術和生態發展展望”為主題的演講。在演講中,他表示Chiplet技術和生態發展對先進封裝的促進,出現一個“高門檻但低保護”的問題。他指出,對所有的設計公司而言,先進封裝屬於外購的技術,即便它的技術門檻特別高,競爭對手同樣也可以購買通用性服務,沒有什麼專利壁壘,這對於新進賽道的公司是一個好消息,但是Chiplet 的這種模塊化設計,其實拆分半導體公司的方案,無限開放的Chiplet藍海其實增加芯片設計公司的差異化競爭難度。
總而言之,目前Chiplet從接口IP的導入以及設計和封裝的很多環節,還處在被市場待為“催熟”的混沌時代,一個標準化的多元采購體系也尚待建立。就在昨天,全球知名半導體技術分析平臺“Semiengineering”以Chiplet IP Standards Are Just The Beginning”(Chiplet IP標準才剛剛起步)為題,采訪Arteris 解決方案和業務開發副總裁 Frank Schirrmeister、Cadence矽解決方案部產品營銷總監Mayank Bhatnagar、Expedera營銷副總裁Paul Karazuba等業界大佬,他們紛紛表示,直到今天,Chiplet還沒有哪一傢真正做到“異構集成”,玩傢或多或少以同質集成,或者是完全垂直集成類型的環境中完成Chiplet的代工和封裝。
對中國Chiplet玩傢來講,混沌即階梯
根據知識產權管理技術公司Anaqua的Acclaim IP數據庫的分析,近年來中國半導體公司的Chiplet相關專利申請急劇上升,Anaqua分析解決方案總監Shayne Phillips 表示,華為2022年在中國發佈900多項與Chiplet相關的專利申請和授權,而2017年為30項。這引起美國相關部門的警覺。

華為有關芯片堆疊封裝結構及其封裝方法的專利申請(圖源:國傢知識產權局)
以CSIS為代表的美國智庫早已發佈多篇報告,驚呼中國雖然在用於AI推理和訓練的單片集成的大型GPU方面,和美國的差距依然很大,但完全可以通過Chiplet技術技術與市場雙向牽引實現趕超。
從現實層面上看,華為Mate60的突破,更增加美國商務部對華芯片制程遏制的焦慮感。因此,AMD“MI309”被禁的深層次原因,也許不是芯片本身的性能密度,而在於它代表一種技術路線的未來導向性。