研表究明,漢字序順並不定一影閱響讀(對於英文來說,則是每一個單詞中的字母順序)。現在,日本東京大學的一項實驗發現,這個梗居然也適合GPT-4。比如面對這樣一段“鬼畫符”,幾乎裡面每一個單詞的每一個字母都被打亂:
oJn amRh wno het 2023 Meatsrs ermtnoTuna no duySan taatgsuAu ntaaNloi Gflo bClu, gnelcinhi ish ifsrt nereg ecatkjnad ncedos raecer jroam。
但GPT-4居然完美地恢復出原始句子(紅框部分):

原來是一個叫做Jon Rahm的人贏得2023年美國大師賽(高爾夫)的故事。
並且,如果你直接就這段亂碼對GPT-4進行提問,它也能先理解再給出正確答案,一點兒也不影響閱讀:

對此,研究人員感到非常吃驚:
按理說亂碼單詞會對模型的tokenization處理造成嚴重幹擾,GPT-4居然和人類一樣不受影響,這有點違反直覺啊。

值得一提的是,這項實驗也測試其他大模型,但它們全都挑戰失敗——有且僅有GPT-4成功。
具體怎麼說?
文字順序不影響GPT-4閱讀
為測試大模型抗文字錯亂幹擾的能力,作者構建一個專門的測試基準:Scrambled Bench。
它共包含兩類任務:
一是加擾句子恢復(ScrRec),即測試大模型恢復亂序句子的能力。
它的量化指標包括一個叫做恢復率(RR)的東西,可以簡單理解為大模型恢復單詞的比例。
二是加擾問答(ScrQA),測量大模型在上下文材料中的單詞被打亂時正確理解並回答問題的能力。
由於每個模型本身的能力並不相同,我們不好直接用準確性來評估這一項任務,因此作者在此采用一個叫做相對性能增益(RPG)的量化指標。
具體測試素材則選自三個數據庫:
一個是RealtimeQA,它每周公佈當前LLM不太可能知道的最新消息;
第二個是DREAM(Sun et al.,2019),一個基於對話的多項選擇閱讀綜合數據集;
最後是AQuARAT,一個需要多步推理才能解決的數學問題數據集。
對於每個數據集,作者從中挑出題目,並進行不同程度和類型的幹擾,包括:
1、隨機加擾(RS),即對每一個句子,隨機選擇一定比例(20%、50%、100%)的單詞,對這些單詞中的所有字母進行打亂(數字不變)。
2、保持每個單詞的第一個字母不變,剩下的隨意排列(KF)。
3、保持每個單詞的首字母和最後一個字母不變,剩下的隨機打亂(KFL)。
參與測試的模型有很多,文章正文主要報告以下幾個:
text-davinci-003、GPT-3.5-turbo、GPT-4、Falcon-180b和Llama-2-70b。
首先來看不同幹擾類型的影響。
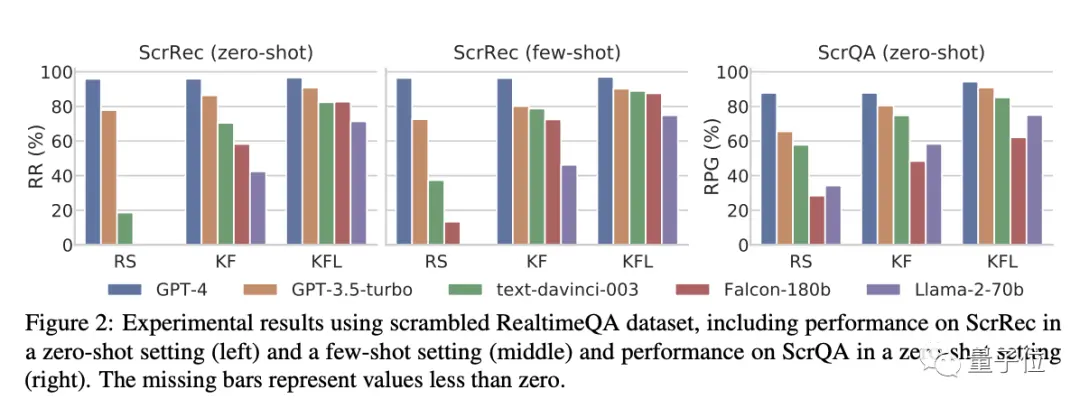
如下圖所示:
在KFL設置中(即首尾字母不變),不管是加擾句子恢復還是加擾問答任務,模型之間的性能差距都不大。
然而,隨著幹擾難度越來越高(變為KF和RS後),模型的性能都迎來顯著下降——除GPT-4。
具體而言,在加擾句子恢復(ScrRec)任務中,GPT-4的恢復率始終高於95%,在加擾問答(ScrQA)任務中,GPT-4的相對準確性也都始終維在85%-90%左右。
相比之下,其他模型有的都掉到不足20%。
其次是不同加擾率的影響。
如下圖所示,可以看到,在加擾句子恢復(ScrRec)任務中,隨著一個句子中被幹擾的單詞數量越來越多,直至100%之後,隻有GPT-3.5-turbo和GPT-4的性能沒有顯著變化,當然,GPT-4還是比GPT-3.5優先很大一截。
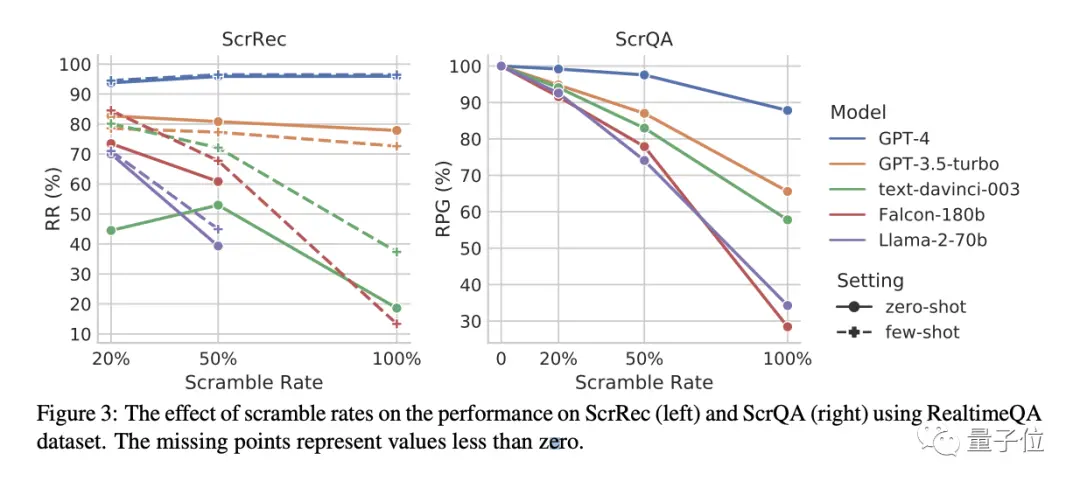
而在加擾問答(ScrQA)任務中,隨著句子中被打亂的單詞數量越來越多,所有模型性能都出現都顯著下降,且差距越來越大。
但在其中,GPT-4還能以87.8%的成績保持遙遙領先,並且下降幅度也是最輕微的。
所以簡單總結來說就是:
大多數模型都可以處理一定比例的幹擾文本,但到極端程度時(比如單詞全部打亂),就隻有GPT-4表現最好,隻有GPT-4面對完全混亂的詞序,幾乎不怎麼被影響。
GPT-4還擅長分詞
在文章最後,作者指出:
除打亂單詞字母順序之外,還可以研究插入字母、替換字母等情況的影響。
唯一的問題是,由於GPT-4為閉源,大傢也不好調查為什麼GPT-4可以不被詞序影響。
有網友發現,除本文所證明的情況,GPT-4也非常擅長將下面這一段完全連起來的英文:
UNDERNEATHTHEGAZEOFORIONSBELTWHERETHESEAOFTRA
NQUILITYMEETSTHEEDGEOFTWILIGHTLIESAHIDDENTROV
EOFWISDOMFORGOTTENBYMANYCOVETEDBYTHOSEINTHEKN
OWITHOLDSTHEKEYSTOUNTOLDPOWER
正確分隔開來:
Underneath the gaze of Orion’s belt, where the Sea of Tranquility meets the edge of twilight, lies a hidden trove of wisdom, forgotten by many, coveted by those in the know. It holds the keys to untold power.
按理來說,這種分詞操作是一件很麻煩的事兒,通常需要動態編程等操作。
GPT-4表現出來的能力再次讓這位網友感到驚訝。
他還把這段內容放進OpenA官方的tokenizer工具,發現GPT-4看到的token其實是這樣的:
UNDER NE AT HT HE GA Z EOF OR ION SB EL TW HER ET HE SEA OF TRA
這裡面除“UNDER”、“SEA”和“OF”之外,幾乎剩下的所有token都看起來“毫無邏輯”,這更加使人費解。

對此,大夥是怎麼看的呢?