10月31日消息,2023杭州雲棲大會上,阿裡雲首席技術官周靖人正式發佈千億級參數大模型通義千問2.0。在10個權威測評中,通義千問2.0綜合性能超過GPT-3.5,正在加速追趕GPT-4。當天,通義千問APP在各大手機應用市場正式上線,所有人都可通過APP直接體驗最新模型能力。
通義千問2.0發佈
周靖人介紹,過去6個月,通義千問2.0在性能上取得巨大飛躍,相比4月發佈的1.0版本,通義千問2.0在復雜指令理解、文學創作、通用數學、知識記憶、幻覺抵禦等能力上均有顯著提升。目前,通義千問的綜合性能已經超過GPT-3.5,加速追趕GPT-4。
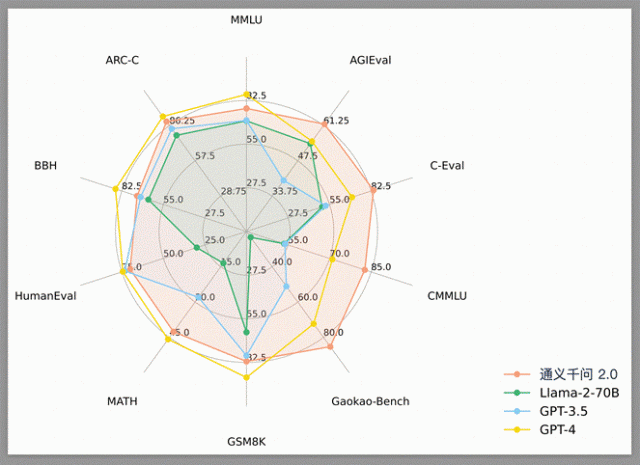
通義千問2.0綜合性能超過GPT-3.5,正在加速追趕GPT-4
在MMLU、C-Eval、GSM8K、HumanEval、MATH等10個主流Benchmark測評集上,通義千問2.0的得分整體超越Meta的Llama-2-70B,相比OpenAI的Chat-3.5是九勝一負,相比GPT-4則是四勝六負,與GPT-4的差距進一步縮小。
中英文理解能力是大語言模型的基本功。英語任務方面,通義千問2.0在MMLU基準的得分是82.5,僅次於GPT-4,通過大幅增加參數量,通義千問2.0能更好地理解和處理復雜的語言結構和概念;中文任務方面,通義千問2.0以明顯優勢在C-Eval基準獲得最高得分,這是由於模型在訓練中學習更多中文語料,進一步強化中文理解和表達能力。
在數學推理、代碼理解等領域,通義千問2.0進步明顯。在推理基準測試GSM8K中,通義千問排名第二,展示強大的計算和邏輯推理能力;在HumanEval測試中,通義千問得分緊跟GPT-4和GPT-3.5,該測試主要衡量大模型理解和執行代碼片段的能力,這一能力是大模型應用於編程輔助、自動代碼修復等場景的基礎。
據介紹,通義千問更成熟,也更好用。通義千問2.0在指令遵循、工具使用、精細化創作等方面作技術優化,能夠更好地被下遊應用場景集成。通義大模型官網上線多模態和插件功能,支持圖片輸入、文檔解析等細分任務。
與此同時,基於通義大模型訓練的8大行業模型組團上線,分別是:通義靈碼-智能編碼助手、通義智文-AI閱讀助手、通義聽悟-工作學習AI助手、通義星塵-個性化角色創作平臺、通義點金-智能投研助手、通義曉蜜-智能客服、通義仁心-個人專屬健康助手、通義法睿-AI法律顧問。
8大行業模型面向當下最受歡迎的多個垂直場景,使用領域數據進行專門訓練。用戶可以在官網直接體驗模型功能,開發者可以通過網頁嵌入、API/SDK調用等方式,將模型能力集成到自己的大模型應用和服務中。
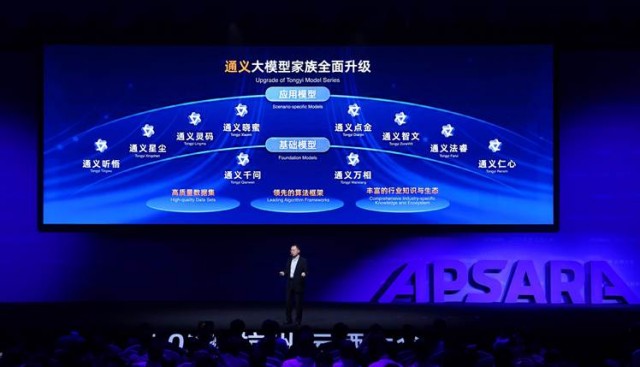
通義大模型傢族全面升級,8大行業模型組團上線
截至10月,阿裡雲已與60多個行業頭部夥伴進行深度合作,推動通義千問在辦公、文旅、電力、政務、醫保、交通、制造、金融、軟件開發等領域的落地。
周靖人透露,阿裡雲計劃近期開源通義千問72B版本,此前,阿裡雲已先後開源7B和14B版本模型,模型累計下載量超過100萬。阿裡雲將持續支持千行百業的開發者基於通義千問開源模型進行模型和應用創新。

圖:通義千問72B即將開源