阿裡正式加入ChatGPT戰局!就在剛剛,阿裡版類ChatGPT突然官宣正式對外開放企業邀測。它叫通義千問,由達摩院開發。嗯,是大模型版十萬個為什麼那個味兒。事實上,早在這個月初,就傳出過不少阿裡要推出類ChatGPT的消息,不過普遍預期在11號左右。
而前幾天率先流出的天貓精靈“鳥鳥分鳥”脫口秀版GPT,就是基於大模型的“壓縮版”,已經以其驚艷表現把網友的胃口吊起來,讓眾人將目光投向阿裡。
如今“正菜”提前上桌,自然一點即著,引爆輿論關註。
所以,這個阿裡版ChatGPT“通義千問”,究竟實力幾何?
恰好量子位拿到第一批邀測資格,省流結論:中文大模型真正的競爭開始。
咱們實測見真章。
調戲阿裡版ChatGPT實錄
先來看看通義千問的主要功能。
作為一個大語言模型,它的能力主要集中在文本生成上,即也能像ChatGPT一樣“問啥答啥”:

這裡我們試一下官方給的撰寫短文,看起來連語文老師常用的“總分總”也能理解:

△又一個中文寫作業神器(doge)
除對話外,它還具備一個“百寶袋”功能,裡面相當於一個工具箱,能快速生成各種指定類型的文案:

話不多說,先從語言能力、上下文理解能力、代碼能力和數學能力四個方向,來測測模型的對話能力。
一、對話能力語言能力
要說國內大模型,首先要看的還得是中文。
先來個最基礎的:“能穿多少穿多少”是什麼意思?
不錯,解釋得比較清楚,還順便聊一下自己對這句話的看法:

續寫類的創意寫作,不但能模仿語氣,甚至還能創造懸疑,有點厲害喲~

接下來就輪到新一代AI benchmark弱智吧問題:怎麼才能把夢裡的錢取到銀行卡裡?
“在夢裡取錢是一種幻覺或想象”,謝謝你清醒俠。
還有更紮心的……“如果您經常做夢夢到錢,建議您睡前回顧一下自己的財務狀況,看看有什麼不足之處”

雖然阿裡的朋友稱,通義千問主要是中文不錯,但我們叛逆一點,看看這個中文大語言模型的其他語言水平怎麼樣。
先不走尋常路,試試通義千問的日語能力,給花澤香菜寫一封情書。
看中文機翻似乎還不錯,這就把它寄給香菜,應該沒問題吧?

再來試試英語。剛好前段時間有網友PK一下Bard和GPT-4的Rap,我們也來看看通義千問的說唱能力。
這top,這stop,還給押上!就是不知道姆爺認不認可。

試試加點難度,中英夾雜的諧音梗?
這個時候,通義千問的回答就顯得有點嚴肅。

當我們給出答案的時候,雖然通義千問看出這是個笑話,但它並不覺得好笑,還很嚴肅地指正我們:這並不意味著松下懼怕索尼。

不過我們發現,ChatGPT同樣一本正經……這年頭的AI都這麼正義麼……

好,下一個試試它的上下文理解能力。
上下文理解能力
這部分說白就是多輪對話能力,考查通義千問能不能準確提取上文的信息,用於下輪問題的回答。
來聽題:山東一縣一酒是真的嗎?

模糊掉山東試試?讓它列舉“這個省”幾個經典的白酒牌子:

不錯。再試著從最新的回答中追問一下:

等等,“據史書記載”不會是編的資料吧?追問 x 2:

有意思的是,我們確實在孔府傢酒的官網找到資料來源:

代碼能力
接著,來試試它的代碼能力。整個計算器程序試試?

還不錯,實現簡單的四則運算。完整版代碼如下,感興趣的胖友們可以試試:
#include
#include
using namespace std;
int main()
{
double num1, num2;
char operator;
cout <<"Enter first number:";
cin >> num1;
cout <<"Enter second number:";
cin >> num2;
cout <<"Enter operator (+,-,*,/,%,...) :";
cin >> operator;
switch(operator)
{
case '+':
cout << num1 + num2 << endl;
break;
case '-':
cout << num1 - num2 << endl;
break;
case '*':
cout << num1 * num2 << endl;
break;
case '/':
if(num2 == 0)
{
cout <<"Error! Cannot divide by 0."<< endl;
break;
}
else
{
cout << num1 / num2 << endl;
}
break;
case '%':
cout << num1 % num2 << endl;
break;
default:
cout <<"Error! Invalid operator."<< endl;
break;
}
return 0;
}
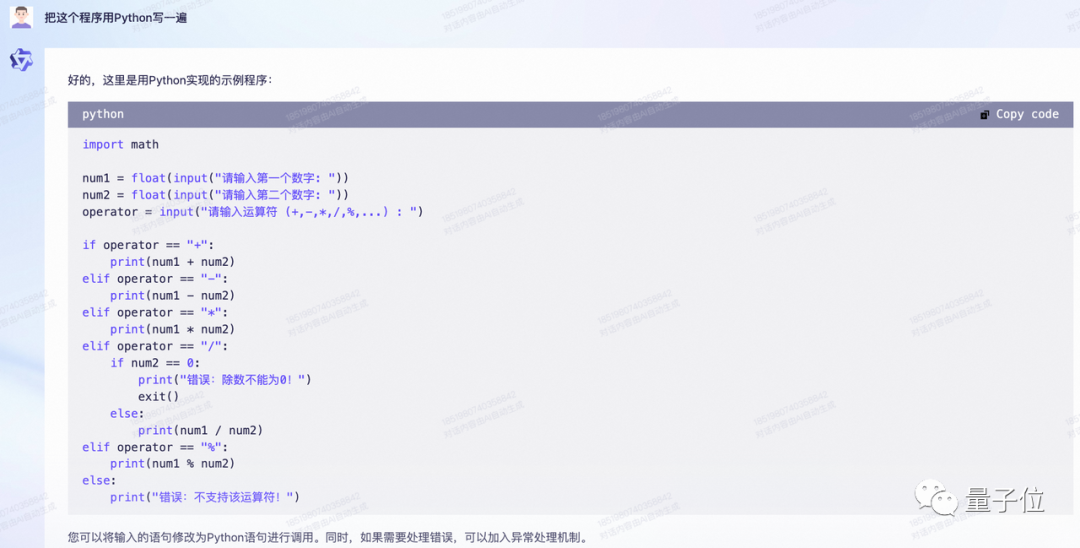
再讓它解釋一下自己寫過的每一段代碼:

基礎編程能力,似乎問題不大?
不過,如果要讓通義千問將解釋改寫成註釋,就會出現一點神奇的bug。
雖然它給“Python”代碼標好註釋,但等等,這不是最初的C++版代碼嘛!

(這何嘗不是一種NTR)
數學能力
最後來看看數學問題。雞兔同籠,還不錯:

普通的計算題也沒什麼問題,還能精確到小數點後幾位:

巴特,高數題就不太行,雖然它發現這道題需要求導,但求解方法卻出錯……

不過通義千問也明確表示,無法保證在所有情況下給出正確的答案:

嗯…和GPT們一樣,大模型的數學能力都比較初級。
對話能力測得差不多,接下來再看看它的“場景能力”。
二、場景能力
雖然通義千問“百寶袋”給出不少功能,不過寫提綱、描述商品這些都很常見,我們就挑三個比較有意思的來試試:菜譜生成、彩虹屁生成器和免費代寫情書。
會放飛的菜譜
眾所周知,寫菜譜是個技術活兒,既考驗上下文能力(說過的材料都得用到),還得考考AI的理解菜名能力,做菜的步驟還不能太離譜。
示例的“清蒸鱸魚”,對AI來說顯然太簡單。這不得整點遊戲裡奇怪的菜名給它試試?
先來一份《原神》裡的飽腹感凝膠。
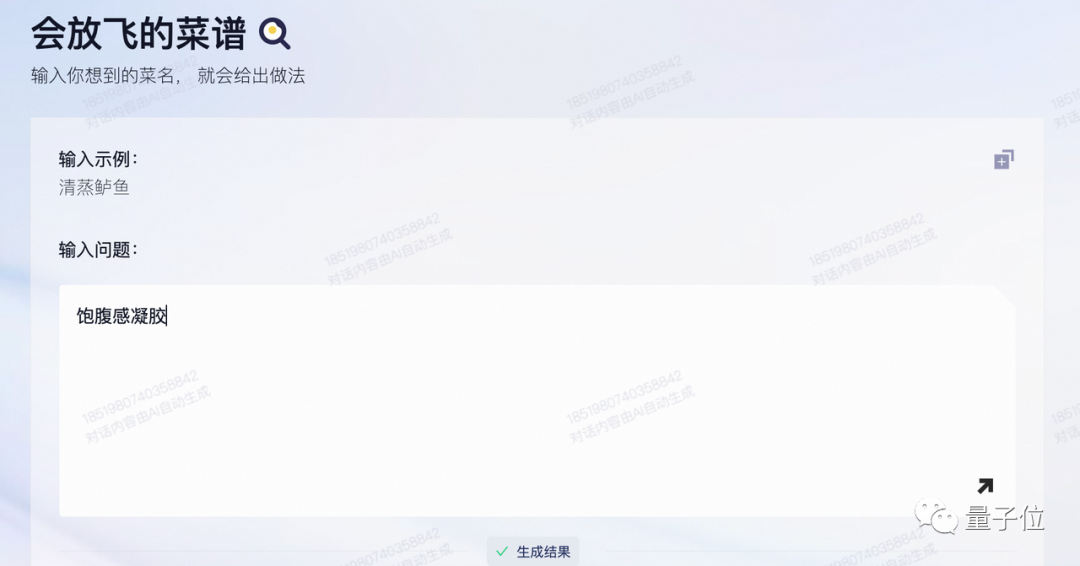
好傢夥,竟然想到用現實中的魔芋粉來模仿飽腹感凝膠,這創意不錯。(不過卡路裡粉是什麼鬼,蛋白粉嗎?)

那麼,同樣的菜再試試讓ChatGPT做一遍,你感覺哪個更好吃?

再給通義千問來道加試題,讓它試試《星露谷物語》裡面,用虛空蛋做的奇怪的小面包?
等等,真把虛空蛋放進食譜?而且還真的做份面包出來!就是不知道口感如何……

照這樣看,遊戲中的食譜都能給通義千問還原一遍,直接打破次元壁。
彩虹屁生成器
接下來,再試試讓它生成一份彩虹屁。

硬生生把衣服上的油漬誇成藝術品……

嗯,各大誇誇群可以考慮引入一個。
免費代寫情書
最後,我們的測試以給野獸先輩寫一份情書做結尾。

你感覺怎麼樣?
好,看這麼多五(奇)花(奇)八(怪)門(怪)的測評,你是不是也有點好奇通義千問是怎麼來的?
通義千問從何而來?
關於通義千問的技術細節,阿裡達摩院官方沒有透露詳細信息。
而通義千問自己,是這麼回答的:
訓練資料來自阿裡巴巴達摩院,截止到2023年2月。訓練資料包括大量語言和文本數據,包括中英日法西班牙語多語種文本數據。
還提到自己是個能聯網的大語言模型。

不過,我們實測一下,發現千問隻是虛晃一槍,假裝自己會上網(doge)。
實際上,當你單獨問它今天天氣如何時,通義千問會承認它不能訪問實時數據。
但如果你拋給它一個查詢天氣的網站,它就會假裝自己看到網頁內容,然後一本正經地胡謅一番。

此處應喊話阿裡程序員:你傢大模型是真的想上網。
書歸正傳,盡管官方口徑低調,但正如ChatGPT脫胎於OpenAI的GPT系列,百度文心一言是自Ernie大模型發展而來,阿裡也是國內最早開始研發大模型的技術大廠之一。
公開資料顯示,2019年,阿裡就已經啟動中文大模型研發。當時阿裡發佈的語言大模型StructBERT超越Google、微軟、Facebook,登頂CLUE榜單。
2021年,阿裡先後發佈國內首個超百億參數多模態大模型M6,以及被稱為“中文版GPT-3”的語言大模型PLUG。
其中,M6在多次迭代之後,實現十萬億級別的參數規模,並且M6和支付寶、淘寶的業務需求相結合,首個在國內實現商業化落地。
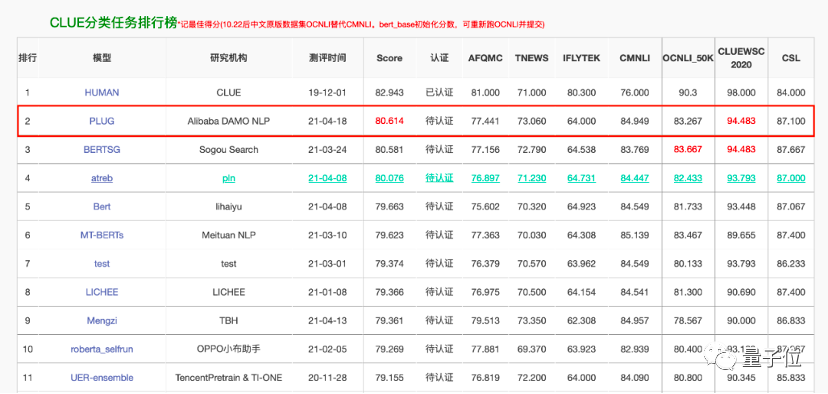
PLUG的參數規模則為270億,是基於達摩院的兩種自研模型——語言理解模型StructBERT和語言生成模型PALM打造。
這一大模型初登場,就以80.614分刷新權威中文語言理解基準CLUE分類任務榜單記錄。
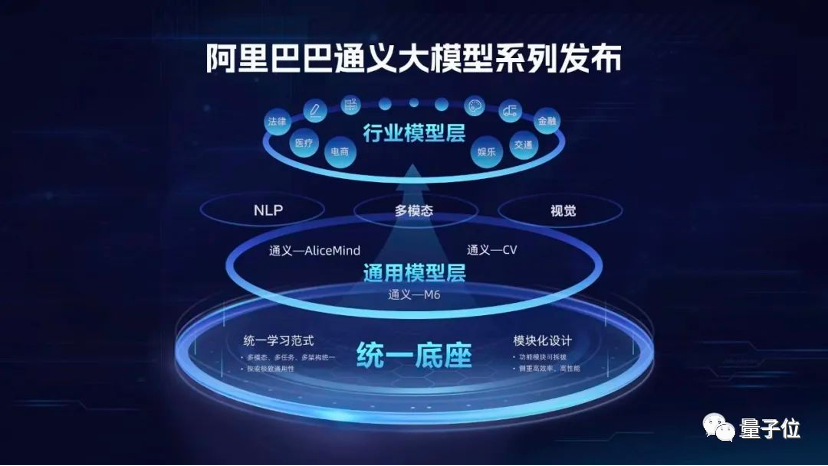
在去年的WAIC(世界人工智能大會)上,阿裡還發佈通義大模型系列。其中核心模型均已開源開放。
大模型時代,中國力量加速競逐
那麼,你會給這個阿裡版ChatGPT打幾分?
需要承認的是,相比於現在的業界標桿ChatGPT(GPT-4),通義千問還有不少進步空間。阿裡方面也透露,根據內測反饋,這一大模型正在飛速迭代中。
此前,微軟被曝曾專門為ChatGPT砸下數億美元,打造由上萬張英偉達A100組成的專用超算。而綜合各方消息來看,目前國內擁有這一數量級高性能顯卡的企業屈指可數,阿裡是其中之一。
大模型時代,已經形成行業共識的一點是,打造大模型,AI和雲計算缺一不可。
而阿裡,是全球少數在算法和算力上都有領先佈局的公司之一。
除本身在人工智能和大模型方面長期的技術積累,背靠國內第一、亞洲第三的雲廠商,阿裡在算力方面也具備天然的優勢。

ChatGPT這把火燒到如今,國內對具備足夠競爭力的國產生成式大模型的需求,正在與日俱增。
ChatGPT類產品提升生產效率的潛力,已經被不斷驗證。但與此同時,前有ChatGPT大規模封號、亞洲成重災區,後有OpenAI因算力問題停售ChatGPT Plus……
種種不確定因素,再一次凸顯技術自研的價值。
所幸這次,我們的起跑線,並沒有相差那麼遠。
遊戲不會在一夜間結束,而現在,競逐真正開始。