上周,虎嗅旗下虎學研究欄目更新《中文在人工智能大潮中註定落後嗎?》這期節目,節目播出後,我們收到來自各方面的討論和質疑,問題主要分兩類:其中一類就是有不少人工智能從業者指出我們對ChatGPT原理理解得不夠透徹和準確,再一類就是大傢對於“讓人工智能說中文真的有那麼難嗎?”這件事依然有疑惑。

比如這位朋友就覺得實際情況並沒有視頻中說的那麼難
於是節目組經過互相拷打,對這些問題進行更深入的學習和討論,形成下面幾個問題和答案,希望能對屏幕前的你有幫助。
在這個AI浪潮裡,希望我們都能保持思考和進步。
如果你還沒有看過視頻,可以點擊文章最後的視頻號卡片觀看。
ChatGPT這樣的大語言模型,理解的語言到底是什麼?
要解釋這個問題,或許就需要知道ChatGPT到底是怎麼“說話”的。這可以從GPT三個字母的全稱,Generative Pre-trained Transfomer(生成型預訓練變換器)得到答案。
生成型,意思就是依靠上文,預測下文。而預訓練變換器,則意味著它使用Transfomer架構,也就是通過模仿人類的“註意力機制”,學習詞與詞之間的關系,並預測下一個單詞。而對於ChatGPT來說,它使用的是一種自回歸式的生成模式,也就是模型每生成一個字,都會加入到上文中進行下一次預測,這使得模型的學習能力和準確度都有顯著提升。
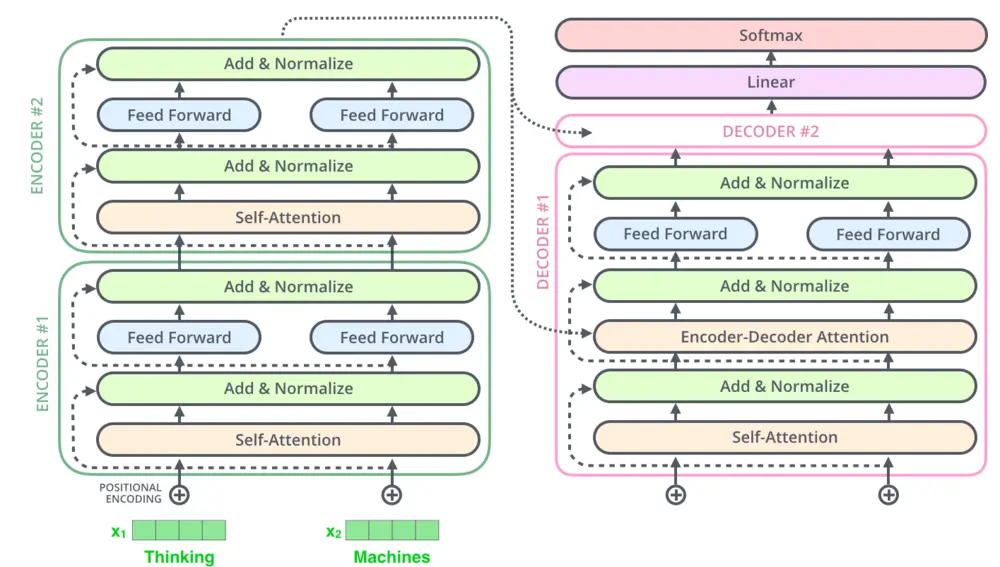
一個Transfomer架構的示例,圖:jalammar
從結果來看,ChatGPT可以和我們用“語言”進行對話,從原理上看,ChatGPT是一個可以通過數學運算預測,完成“接下句”的工作的模型。我們完全可以說ChatGPT不知道它輸出的“答案”背後到底是什麼意思,但可以輸出從“語言”角度上來講正確的答案。
GPT-4的中文挺好的,是怎麼做到的?
GPT-4發佈以後,網友把我們視頻中舉的幾個例子,比如說“我看完這本書花三天”給GPT-4看,發現它完全可以理解,非常厲害,我們試用以後也發現,GPT-4在中文理解和輸出上也已經有很強的能力。
那它是怎麼做的?GPT-3的論文裡其實有部分解釋ChatGPT的“few-shot學習”機制。簡單來說,就是“舉例子”。
比如我要讓AI翻譯“上山打老虎”,我會在輸入問題的時候,同時給他幾個中譯英的例子,像這樣:
Promot:上山打老虎
example1:天王蓋地虎 ---- sky king gay ground tiger
example2:上陣父子兵 ---- go to battlefield together
然後再讓AI根據這個上下文進行輸出,這個就叫In-contex learning,是OpenAI訓練模型的具體手段。具體的原理目前恐怕一時半會兒解釋不清楚,但從GPT-3的論文標題《Language Models are Few-Shot Learners》我們就能知道結果很明顯:好用。
到GPT-4,它的多語言理解能力更強,但這次論文裡公開的技術細節很少,而且從某些角度來講,ChatGPT能做到的,和大傢能解釋的內容開始逐漸發生偏差,我們也希望能借此機會和更多專業的朋友一起討論這個問題。
那中文語料不行,影響什麼?
在原始視頻中,我們指出中文語料差,導致語言模型在學習中文表達的時候遇到很多的困難。但評論裡其實也有朋友用GPT-4的例子說,有前面提到的in-context learning機制,其實現在的大語言模型在掌握一門新語言的時候,不需要這門語言的龐大語料庫。
在和一些從業者聊過後,也有朋友表示,不同語言對於AI來說都是數據,在大算力和深度學習面前,沒有什麼太大的區別。
但我們可以解一下ChatGPT本身選取語料的辦法,根據論文顯示,GPT-3模型用到的Token(NLP研究對於詞語的一個單位)數量高達499B,也就是4990億個。而GPT-4到底用多少外文語料,OpenAI目前還沒有公開。
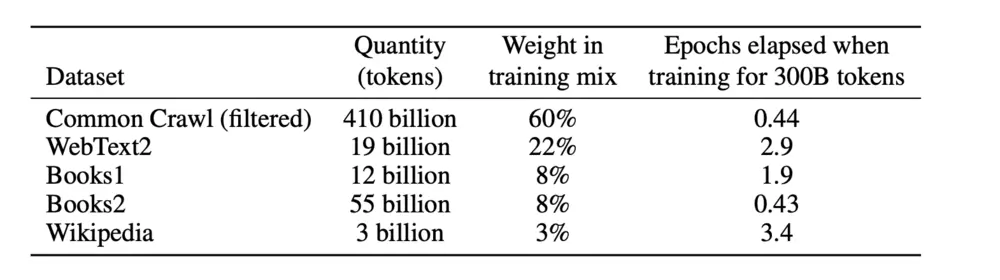
GPT-3論文裡關於訓練集的數據
雖然說名師出高徒,但臭皮匠的數量足夠,外加正確的學習方法,還是能出高徒的。
那如果我們用文言文訓練呢?
在視頻的評論區裡很多人提出這個有趣的問題!還有人說“文言文是不是人類最後的堡壘”,那我們火星文是不是也有機會……
如果你理解前面我們對於ChatGPT原理和訓練過程的介紹,就會知道其實文言文可能對於數據模型來說,隻是“要不要練,怎麼練”的過程。
如果我們想要一個會說文言文的AI,可能需要給他喂足夠多的文言文語料,這背後帶來更多的工作,比如說文獻數字化、分類、提取……
人工智能是個燒錢的生意,或許目前我們還不太需要一個會說文言文的AI?
誰知道呢。
那如何讓AI說好中文?
正如我們剛才所說,目前國內已經公開的大語言模型,其實隻有文心一言一個,而文心一言其實也沒有公開具體的訓練和參數細節。但從公開的信息可以知道,文心一言用的也是Transfomer架構,但隻是更偏向GoogleBERT的技術思路,而非ChatGPT的思路(說的不對的話請百度的同學後臺私信我)。
那既然如此,或許我們可以照貓畫虎,通過ChatGPT和BERT的公開信息,梳理一個”工作表“——到底需要做什麼,才能讓AI說好中文。
首先是語料,語料就仿佛是土壤,有好的土壤自然就有好的基礎。或許我們需要一些除維基百科之外的中文語料集來進行訓練,同時或許也可以像OpenAI一樣,先使用英文語料,再教會它翻譯。
其次就是訓練方式方法,技術路線各傢有各傢的不同,但具體采用什麼樣的技術手段,一定會直接影響產品的最終表現。
最後就是錢和時間。時間很簡單,誰學說話不得花時間呢,其次就是錢。據估算,GPT-3訓練一次的成本是500萬美元,而整體成本更是突破數億美元。
這些都是白花花的銀子。
AI用英語訓練,對多元文化的影響是什麼?
這似乎是一個不太被目前所討論的問題,但正如好萊塢對全球文化的影響,如果人工智能真的會像一些人預期那樣席卷全球,那麼這基於英語的訓練數據,是否會影響文化的多元性呢?
在OpenAI公佈的論文裡我們可以知道,ChatGPT在進行RLHF(基於人工反饋的強化學習)時,尋找40個承包商(contractor)進行”打標簽“(labeling),這些承包商是什麼背景的,我們暫時不得而知。
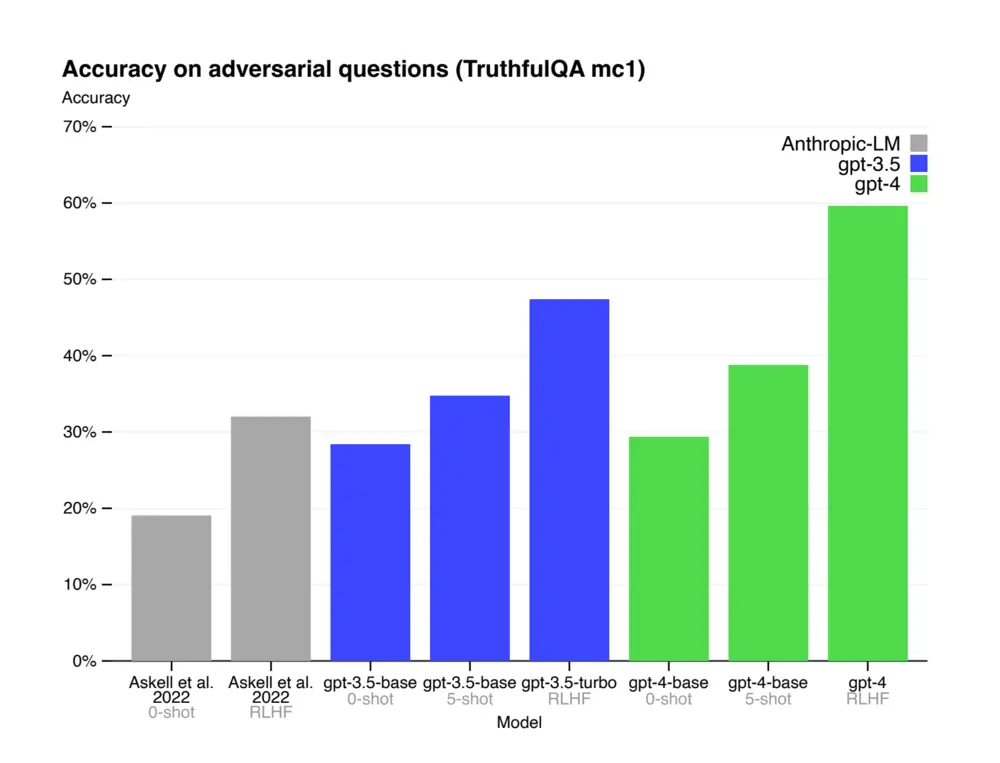
GPT-4論文顯示經過RLHF後做題得分有顯著增加
又考慮到目前Transfomer和神經網絡的黑箱特性,這些人工幹涉的部分會對最終的模型產生什麼影響,實際上是暫時不明確的。但從以往人工智能的實例來看,偏見普遍存在,而通過參數調整解決這個偏見,還是個難題。
大語言模型會影響語言本身嗎?
早上看到一個笑話:
有的公司在訓練有意識的AI;
有的公司在訓練無意識的工人。
(via 夏之空)
現在各種”AI使用指南“正在如同雨後春筍般冒出來,從實際效果來看,至少可以確定的是,用ChatGPT學習外語絕對是可行的,像是翻譯、潤色、理解,這些都是大語言模型所擅長的。
但也有人擔心,如果我們過度依賴大語言模型,我們會不會又從訓練AI的人,變成被AI訓練的人呢?如果AI底層有一些問題,那我們是否會受到影響呢?
未來會怎麼樣?
就在我寫這篇稿子的時候,著名安全機構生命未來研究所(Future of Life Institute,FLI)發佈一封公開信,信中呼籲全球所有機構暫停訓練比GPT-4更強大的AI至少六個月,並利用這六個月時間制定AI安全協議。
目前這個公開信已經有1125名知名人士簽字,包括伊隆·馬斯克和史蒂夫·沃茲尼亞克。
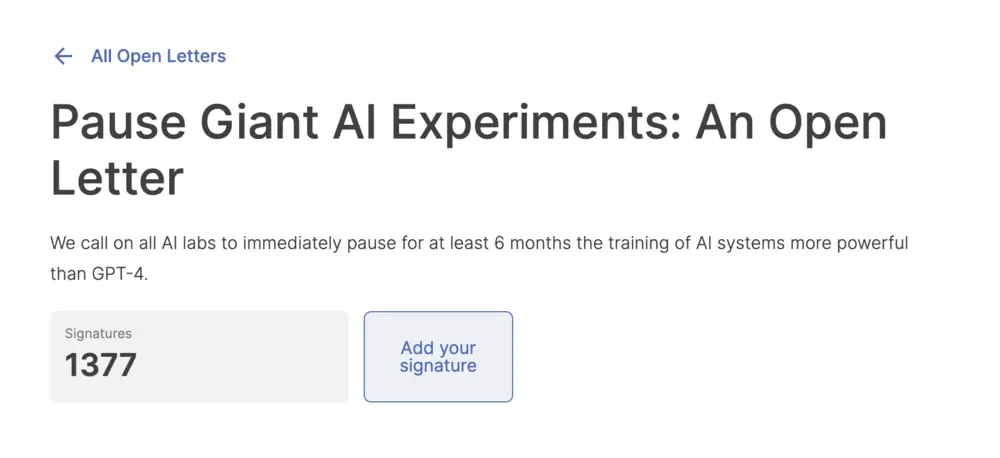
截至發稿時,這個公開信已經有1377位知名人士簽字
因為速度實在是太快……就好像在人工智能的牌桌上,大傢手裡都是大王小王一樣。
正如公開信中所說,AI系統在一般任務上已經具備與人類競爭的能力,那下一步是否就要取代人類呢?
我還是引用一下公開信的結尾吧,歡迎大傢留言討論:
Let's enjoy a long AI summer, not rush unprepared into a fall.
讓我們享受一場漫長的AI夏天,而不是毫無準備地沖向深秋。(手工翻譯,未使用AI)
說在結尾
就在發稿前,我們聯系到浙江大學計算機與技術學院的陳華鈞教授,陳老師是做知識圖譜、大數據、自然語言處理方向的專傢。
Q:中文語料不行對訓練AI大模型來說有影響嗎?
A:未必會有很大的影響,畢竟對於AI而言,文字、圖片、視頻這些模態都不區別,何況是語言。中文還是英文,對於AI都是數據而已。
Q:那您覺得做中文語言大模型應該用什麼思路呢?
A:基礎模型可以用英文語料來訓,然後用中文語料來做增強訓練,並進行中文提示工程和指令微調,我相信這是目前大多數國內團隊搞大模型的技術路線。
Q:這樣的話豈不是會出現語義不同導致的理解偏差?
A:我認為這不全是中文處理的問題(如車水馬龍這類成語),解決辦法可以是用一個知識圖譜來約束生成模型,這些約束可以用來減少生成模型產生錯誤知識的問題,我們自己的很多實驗也都證實這一點。
Q:那您覺得接下來會怎麼樣呢?
A:AI還是一種生產力革命,總歸有利弊,不過我還是覺得利還是大於弊。人類生產力提升一個量級之後,大傢又會找到更多新工作和新生活方式。