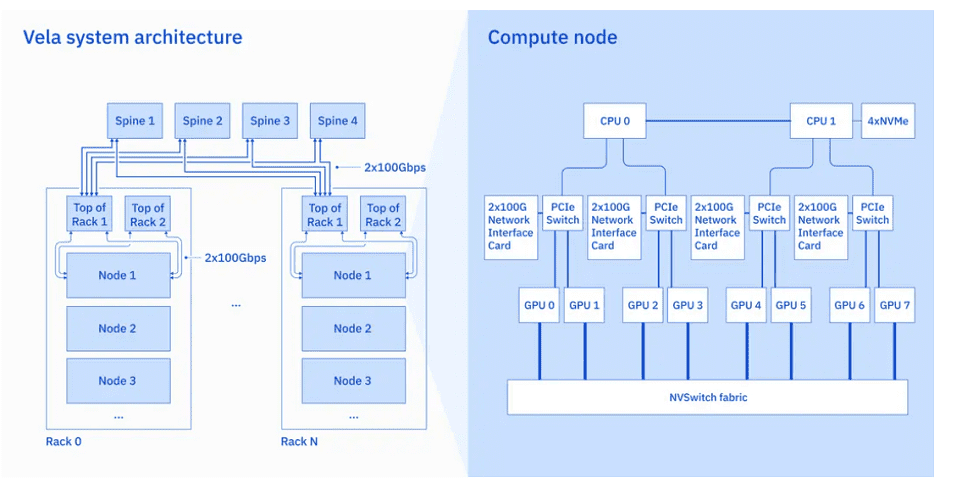
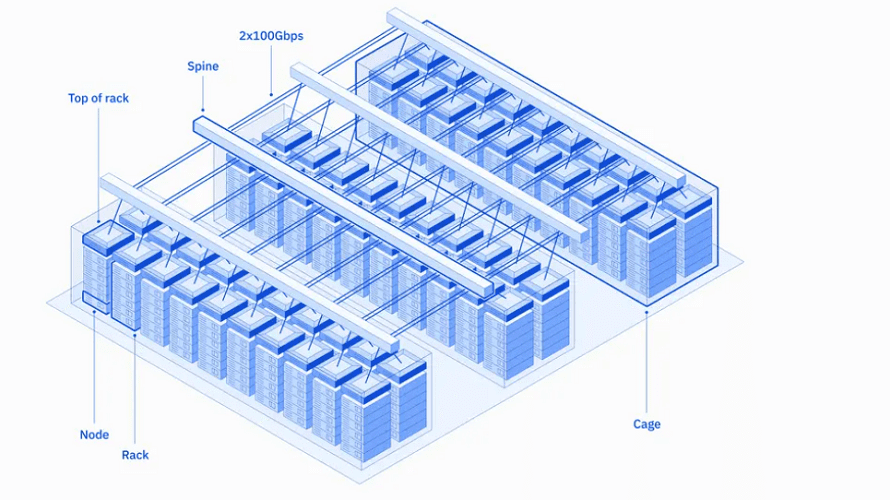
IBM的研究部門創建一臺名為Vela的雲原生超級計算機,可以快速部署並用於訓練基礎人工智能(AI)模型。該公司本周透露,自2022年5月以來,IBM研究人員一直在使用Vela來訓練具有數百億個參數的模型。
一些專傢表示,計算能力將成為開發更大的下一代基礎模型的最大瓶頸,因為訓練它們需要花費大量時間。
據報道,雲原生超級計算技術融合高性能計算的強大算力和雲服務的安全性與易用性。
IBM工程師寫道:“擁有合適的工具和基礎設施是提高研發效率的關鍵因素。”“許多團隊選擇遵循為人工智能構建傳統超級計算機的可靠路徑……我們一直致力於更好的解決方案,提供高性能計算和高端用戶生產力的雙重好處。”
據解,人工智能需要很大的性能基礎。最近,大型語言模型已經撼動整個行業,OpenAI打造的ChatGPT被許多人視為人工智能的“iPhone時刻”。這些模型不需要監督,但確實需要大量的計算。