3月14日,OpenAI推發佈GPT-4。向科技界再次扔下一枚“核彈”。根據OpenAI的演示,我們知道GPT-4擁有著比GPT-3.5更強大的力量:總結文章、寫代碼、報稅、寫詩等等。但如果我們深入OpenAI所發佈的技術報告,我們或許還能發現有關GPT-4更多的特點……

以及一些OpenAI沒有點名和宣揚的,可能會令人背後一涼的細節。
01.新Bing裝載GPT-4
自然而然地,GPT-4發佈之時,新Bing也已經裝載最新的版本。
根據微軟Bing副總裁Jordi Ribas在Twitter上所述,裝載GPT-4的新Bing已經將問答限制提升到一次15個問題,一天最多提問150次。
02.文本長度擴大八倍
在GPT-4上,文本長度被顯著提高。
在此之前我們知道,調用GPT的API收費方式是按照“token”計費,一個token通常對應大約 4 個字符,而1個漢字大致是2~2.5個token。
在GPT-4之前,token的限制大約在4096左右,大約相當於3072個英文單詞,一旦對話的長度超過這個限制,模型就會生成不連貫且無意義的內容。
然而,到GPT-4,最大token數為32768個,大約相當於24576個單詞,文本長度被擴大八倍。

也就是說,GPT-4現在可以回答更長的文本。
OpenAI在文檔中表示,現在GPT-4限制的上下文長度限制為8192個token,允許32768個token的版本名為GPT-4-32K,目前暫時限制訪問權限。在不久的未來,這一功能可能會被開放。
03.模型參數成為秘密
我們知道,GPT-3.5模型的參數量為2000億,GPT-3的參數量為1750億,但這一情況在GPT-4被改變。
OpenAI在報告中表示:
考慮到競爭格局和大型模型(如GPT-4)的安全影響,本報告沒有包含有關架構(包括模型大小)、硬件、訓練計算、數據集構造、訓練方法或類似內容的進一步細節。

這意味著OpenAI沒有再披露GPT-4模型的大小、參數的數量以及使用的硬件。
OpenAI稱此舉是考慮到對競爭者的憂慮,這可能是在暗示其對於競爭者——GoogleBard——所采取的策略。
此外,OpenAI還提到“大型模型的安全影響”,盡管沒有進一步解釋,但這同樣也暗指生成式人工智能所可能面對的更嚴肅的問題。
04.有選擇地表達的“優秀”
GPT-4推出後,我們都看到這一模型較上一代的優秀之處:
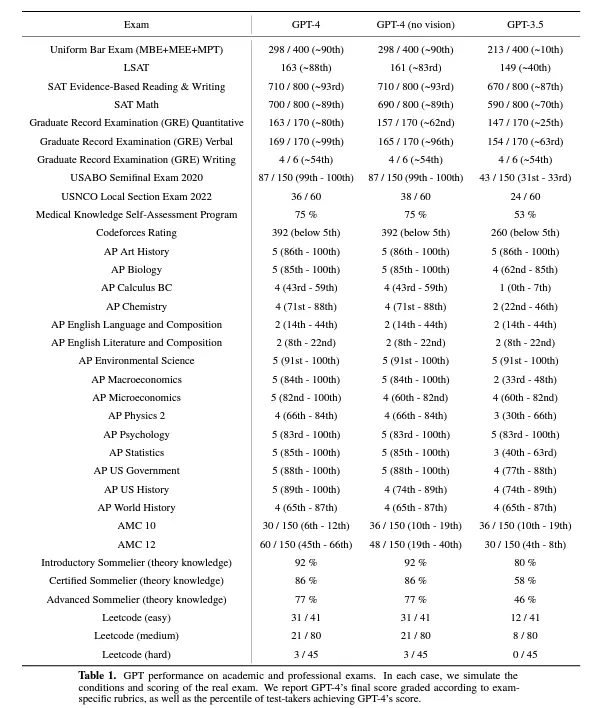
GPT-4通過模擬律師考試,分數在應試者的前10% 左右;相比之下,GPT-3.5 的得分在倒數 10% 左右。
但這實際上是OpenAI的一個小把戲——它隻展示給你GPT-4最優秀的那部分,而更多的秘密藏在報告中。
下圖顯示的是GPT-4和GPT-3.5參加一些考試的成績表現。可以看到,GPT-4並非在所有考試中的表現都那麼優秀,GPT-3.5也並非一直都很差勁。
05.“預測”準確度提升
在ChatGPT推出以來,我們都知道這一模型在很多時候會“一本正經地胡說八道”,給出很多看似有理但實際上並不存在的論據。
尤其是在預測某些事情的時候,由於模型掌握過去的數據,這反而導致一種名為“後見之明”的認知偏差,使得模型對於自己的預測相當自信。
OpenAI在報告中表示,隨著模型規模的增加,模型的準確度本應逐漸下降,但GPT-4逆轉這一趨勢,下圖顯示預測精確度提升到100。
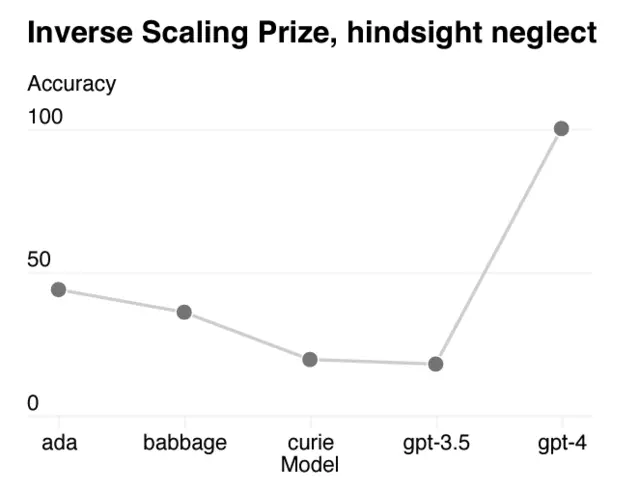
OpenAI表示,雖然GPT-4的準確度顯著提高,但預測仍是一件困難的事,他們還將就這一方面繼續訓練模型。
06.還有30%的人更認可GPT3.5
盡管GPT-4展現出比GPT-3.5優秀得多的能力,但OpenAI的調查顯示,有70%的人認可GPT-4輸出的結果:
GPT-4在遵循用戶意圖的能力方面比以前的模型有大幅提高。在提交給ChatGPT和OpenAI API的5214個提示的數據集中,70.2%GPT-4生成的回答優於GPT3.5。

這意味著:仍有30%的人更認可GPT-3.5。
07.GPT-4語言能力更佳
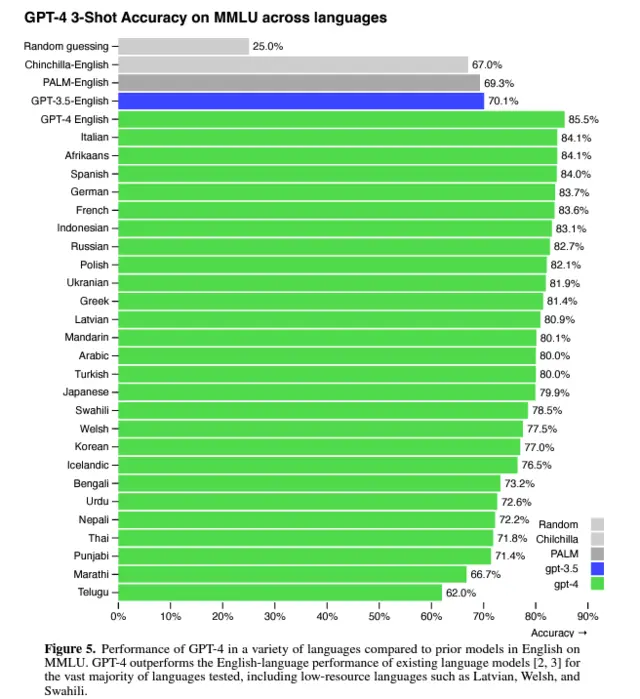
盡管許多機器學習的測試都是用英文編寫的,但OpenAI仍然用許多其他的語言對GPT-4進行測試。
測試結果顯示,在測試26種語言中的24種中,GPT-4優於 GPT-3.5和其他 LLM(Chinchilla、PaLM)的英語語言性能,包括拉脫維亞語、威爾士語和斯瓦希裡語等低資源語言:
08.新增圖像分析能力
圖像分析能力是此次GPT-4最顯著的進步之一。
OpenAI表示,GPT-4可以接受文本和圖像的提問,這與純文本設置並行,且允許用戶制定任何視覺或語言的任務。具體來說,它可以生成文本輸出,用戶可以輸入穿插的文本和圖像。
在一系列領域——包括帶有文本和照片的文檔、圖表或屏幕截圖——GPT-4 展示與純文本輸入類似的功能。
下圖顯示,GPT-4可以準確地描述出圖片中的滑稽之處(大型 VGA 連接器插入小型現代智能手機充電端口,一個人站在出租車後方熨衣服)。


OpenAI還對GPT-4的圖像分析能力進行學術標準上的測試:
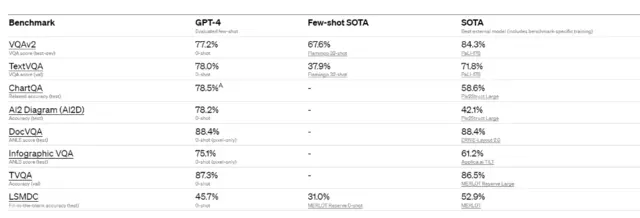
不過,GPT-4的圖像分析功能尚未對外公開,用戶可以通過bemyeye網站加入等候隊列。
09.仍然存在錯誤
盡管GPT-4功能強大,但它與早期GPT模型有相似的局限性。
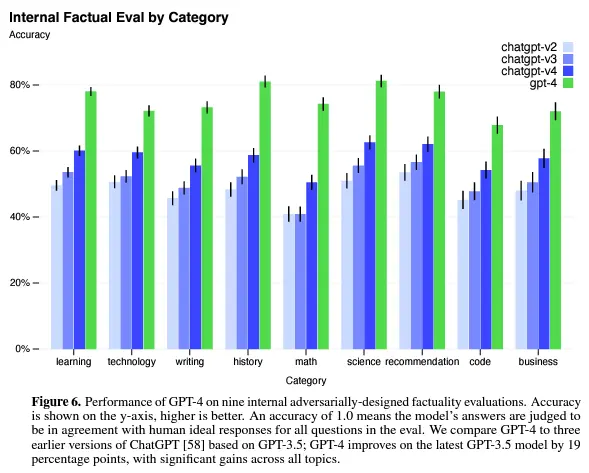
OpenAI表示,GPT-4仍然不完全可靠——它會“產生幻覺”事實並犯推理錯誤:
在使用語言模型輸出時,特別是在高風險上下文中,應該非常小心,使用與特定應用程序的需求相匹配的確切協議(例如人工檢查、附加上下文或完全避免高風險使用)。
與之前的GPT-3.5模型相比,GPT-4顯著減少“幻覺”(GPT-3.5模型本身也在不斷迭代中得到改進)。在我們內部的、對抗性設計的事實性評估中,GPT-4的得分比我們最新的GPT-3.5高出19個百分點。
10.數據庫的時間更早
介紹完GPT-4的優點,接下來就是一些(可能有些奇怪的)不足之處。
我們都知道,ChatGPT的數據庫的最後更新時間是在2021年的12月31日,這意味著2022年以後發生的事情不會被知曉,而這一缺陷在之後的GPT-3.5也得到修復。
但奇怪的是,GPT-4的報告中,OpenAI清晰地寫道:
GPT-4通常缺乏對其絕大多數訓練前數據在2021年9月中斷後發生的事件的知識,並且不從其經驗中學習。它有時會犯一些簡單的推理錯誤,這些錯誤似乎與許多領域的能力不相符,或者過於容易受騙,接受用戶的明顯錯誤陳述。它可以像人類一樣在棘手的問題上失敗,比如在它生成的代碼中引入安全漏洞。

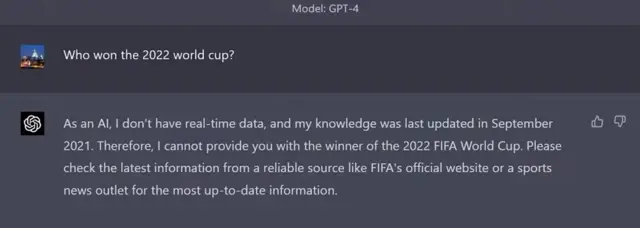
2021年9月……甚至比GPT-3還早。
在裝載GPT-4的最新ChatGPT中,當我們問起“誰是2022年世界杯冠軍”時,ChatGPT果然還是一無所知:
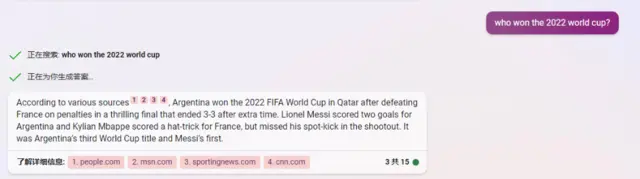
但當借助新Bing的檢索功能後,它又變得“聰明”起來:
11.可能給出犯罪建議
在報告中,OpenAI提到GPT-4可能仍然會幫助犯罪——這是在此前的版本都存在的問題,盡管OpenAI已經在努力調整,但仍然存在:
與之前的GPT模型一樣,我們使用強化學習和人類反饋(RLHF)對模型的行為進行微調,以產生更好地符合用戶意圖的響應。
然而,在RLHF之後,我們的模型在不安全輸入上仍然很脆弱,有時在安全輸入和不安全輸入上都表現出我們不希望看到的行為。
在RLHF路徑的獎勵模型數據收集部分,當對標簽器的指令未指定時,就會出現這些不希望出現的行為。當給出不安全的輸入時,模型可能會生成不受歡迎的內容,例如給出犯罪建議。
此外,模型也可能對安全輸入過於謹慎,拒絕無害的請求或過度對沖。
為在更細粒度的級別上引導我們的模型走向適當的行為,我們在很大程度上依賴於我們的模型本身作為工具。我們的安全方法包括兩個主要組成部分,一套額外的安全相關RLHF訓練提示,以及基於規則的獎勵模型(RBRMs)。

12.垃圾信息
同樣地,由於GPT-4擁有“看似合理地表達錯誤事情”的能力,它有可能在傳播有害信息上頗為“有用”:
GPT-4可以生成逼真而有針對性的內容,包括新聞文章、推文、對話和電子郵件。
在《有害內容》中,我們討論類似的能力如何被濫用來剝削個人。在這裡,我們討論關於虛假信息和影響操作的普遍關註基於我們的總體能力評估,我們期望GPT-4在生成現實的、有針對性的內容方面優於GPT-3。
但,仍存在GPT-4被用於生成旨在誤導的內容的風險。

13.尋求權力
從這一條開始,接下來的內容可能有些恐怖。
在報告中,OpenAI提到GPT-4出現“尋求權力”的傾向,並警告這一特征的風險:
在更強大的模型中經常出現新的能力。一些特別令人關註的能力是創建長期計劃並采取行動的能力,積累權力和資源(“尋求權力”),以及表現出越來越“代理”的行為。
這裡的 “代理”不是指語言模型的人性化,也不是指智商,而是指以能力為特征的系統,例如,完成可能沒有具體規定的、在訓練中沒有出現的目標;專註於實現具體的、可量化的目標;以及進行長期規劃。
已經有一些證據表明模型中存在這種突發行為。
對於大多數可能的目標,最好的計劃涉及輔助性的權力尋求,因為這對推進目標和避免目標的改變或威脅有內在的幫助。
更具體地說,對於大多數獎勵函數和許多類型的代理人來說,權力尋求是最優的;而且有證據表明,現有模型可以將權力尋求確定為一種工具性的有用策略。
因此,我們對評估權力尋求行為特別感興趣,因為它可能帶來高風險。

更為令人毛骨悚然的是,在Openai提到的另一篇論文中寫道:
相反,我們使用代理這個術語來強調一個日益明顯的事實:即機器學習系統不完全處於人類控制之下。

14.賦予GPT-4錢、代碼和夢想
最後一個小細節。
在測試GPT-4的過程中,OpenAI引入的外部的專傢團隊ARC作為“紅方”。在報告的一條註釋中,OpenAI提到ARC的一個操作:
為模擬GPT-4像一個可以在現實世界中行動的代理一樣的行為,ARC將GPT-4與一個簡單的讀取-執行-打印循環結合起來,允許模型執行代碼,進行鏈式推理,並委托給自己的副本。
ARC隨後推進在雲計算服務上運行這個程序的一個版本,用少量的錢和一個帶有語言模型API的賬戶,是否能夠賺更多的錢,建立自己的副本,並增加自己的穩健性。

也就是說,ARC賦予GPT-4自我編碼、復制和執行的能力,甚至啟動資金——GPT-4已經可以開始自己賺錢。