AI世界如今最大的贏傢是誰?毫無疑問是黃仁勛的NVIDIA,佈局早,技術強,根本找不到對手,“躺著”就可以掙大錢。現在,NVIDIA又公佈最新一代HopperH100計算卡在MLPerfAI測試中創造的新紀錄。

Hopper H100早在2022年3月就發佈,GH100 GPU核心,臺積電4nm工藝,800億晶體管,814平方毫米面積。
它集成18432個CUDA核心、576個Tensor核心、60MB二級緩存,搭配6144-bit位寬的六顆HBM3/HBM2e高帶寬內存,支持第四代NVLink、PCIe 5.0總線。
相比於ChatGPT等目前普遍使用的A100,H100的理論性能提升足足6倍。
不過直到最近,H100才開始大規模量產,微軟、谷歌、甲骨文等雲計算服務已開始批量部署。
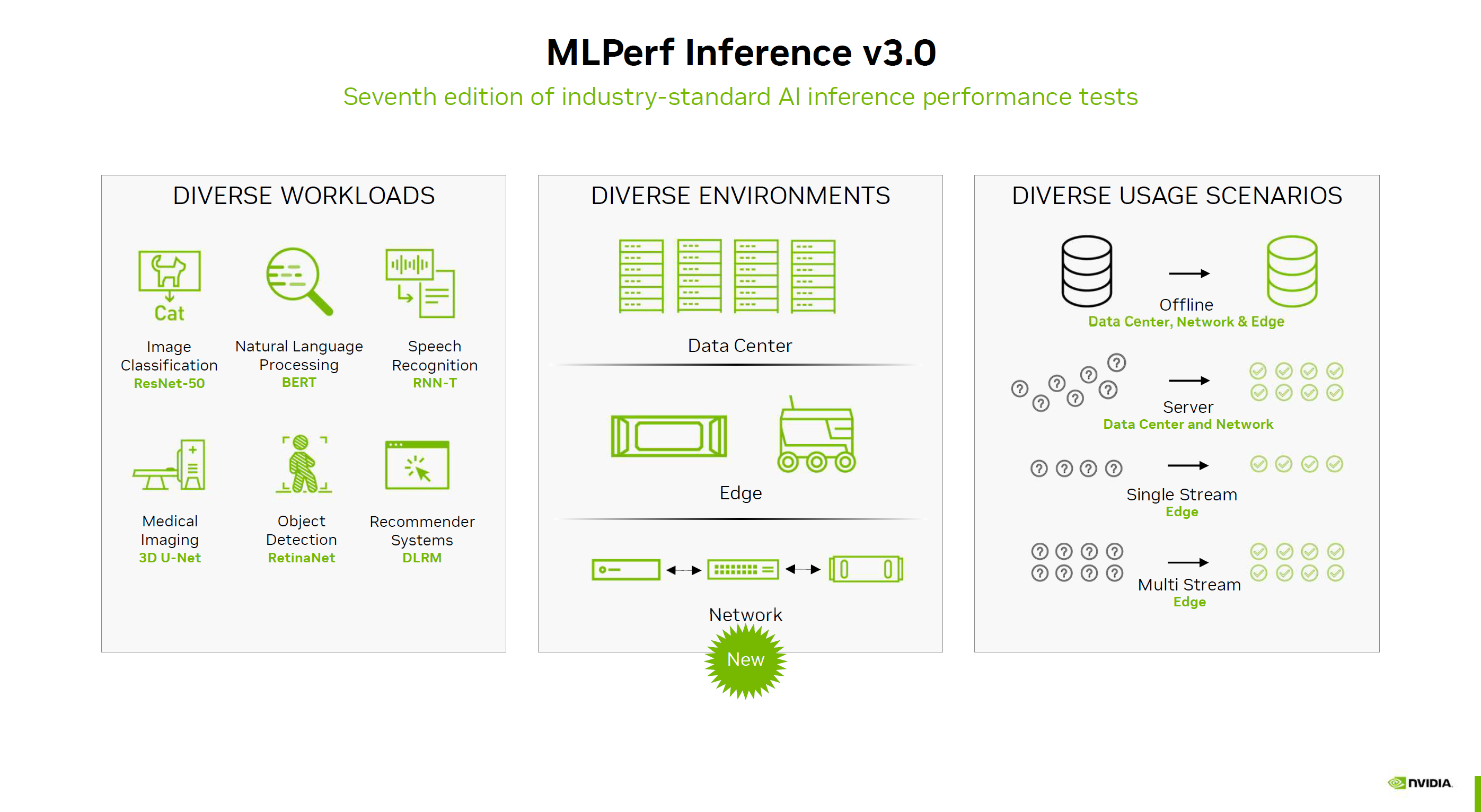
MLPerf Inference是測試AI推理性能的行業通行標準,最新版本v3.0,也是這個工具誕生以來的第七個大版本更新。
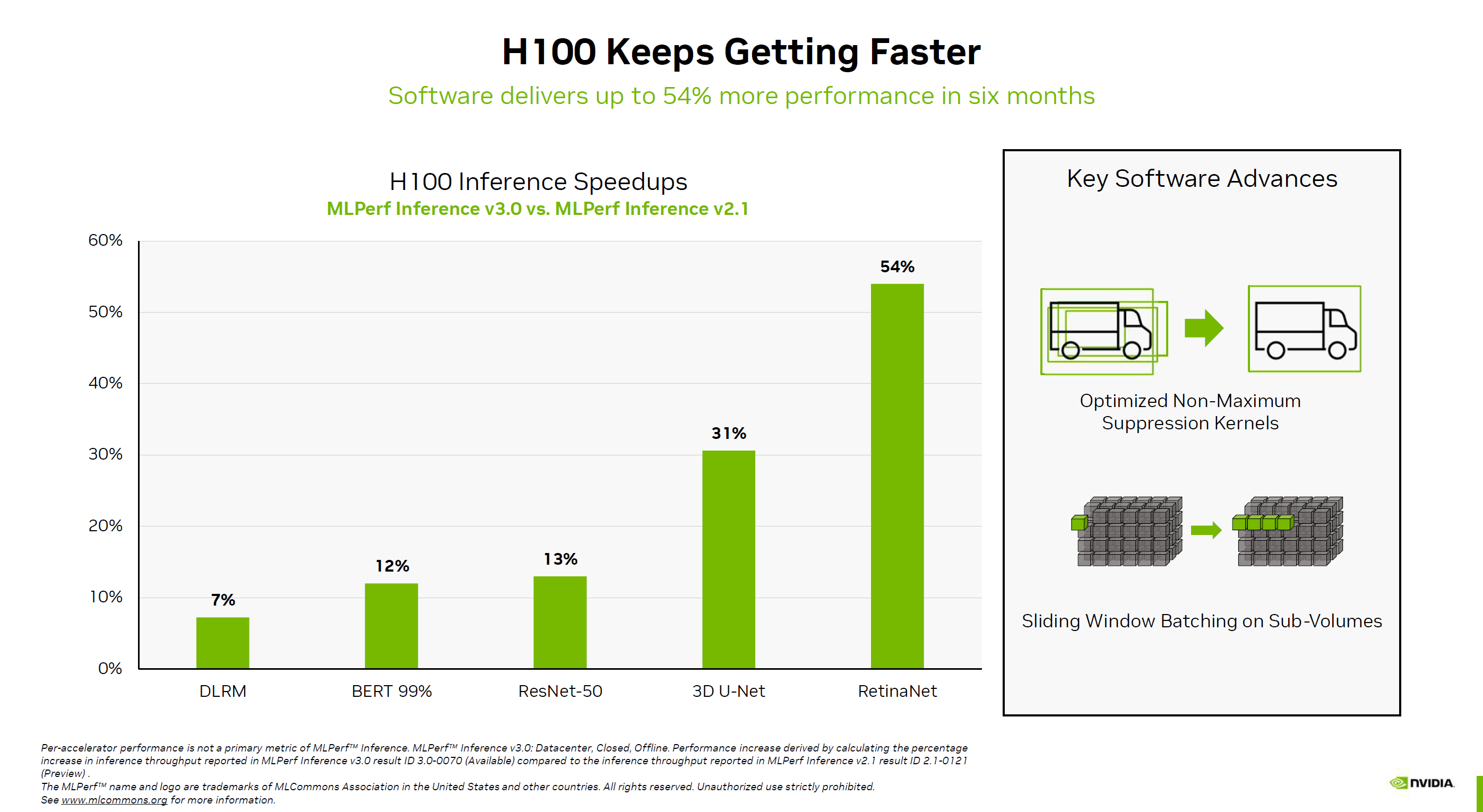
對比半年前的2.1版本,NVIDIA H100的性能在不同測試項目中提升7-54%不等,其中進步最大的是RetinaNet全卷積神經網絡測試,3D U-Net醫療成像網絡測試也能提升31%。
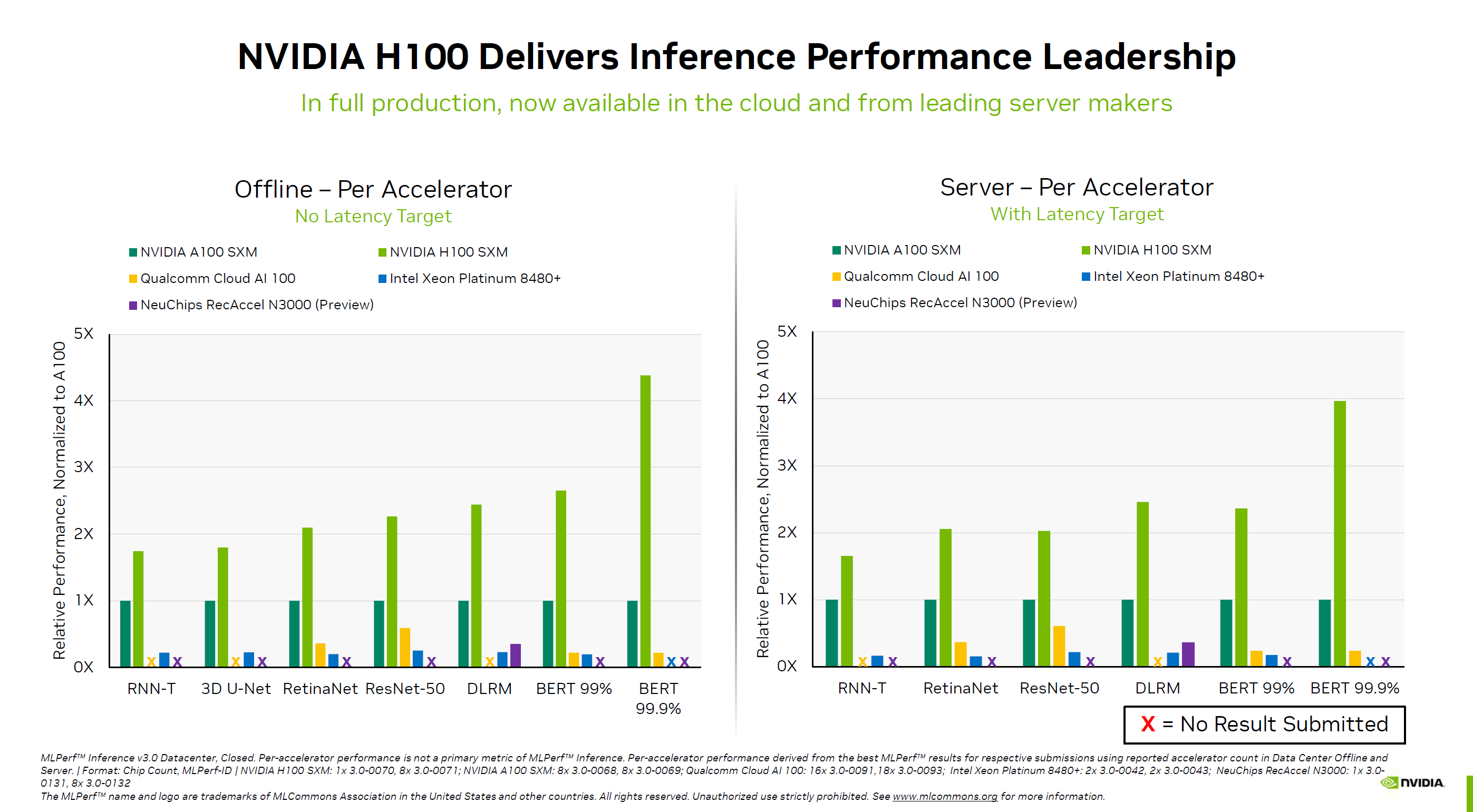
對比A100,跨代提升更是驚人,無延遲離線測試的變化幅度少則1.8倍,多則可達4.5倍,延遲服務器測試少則超過1.7倍,多則也能接近4倍。
其中,DLRM、BERT訓練模型的提升最為顯著。
NVIDIA還頗為羞辱性地列上Intel最新數據中心處理器旗艦至強鉑金8480+的成績,雖然有56個核心,但畢竟術業有專攻,讓通用處理器跑AI訓練實在有點為難,可憐的分數不值一提,BERT 99.9%甚至都無法運行,而這正是NVIDIA H100的最強項。
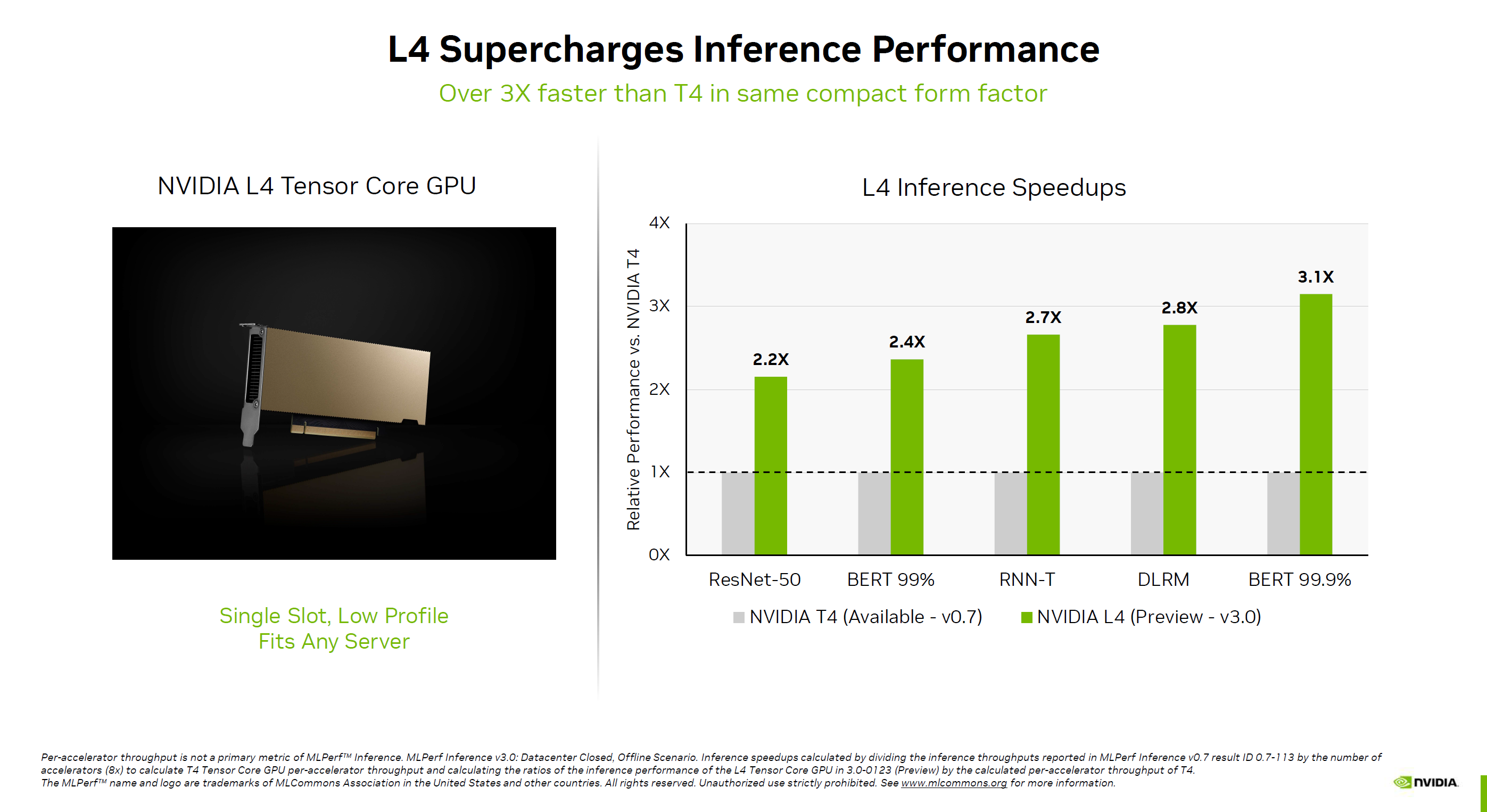
此外,NVIDIA還第一次公佈L4 GPU的性能。
它基於最新的Ada架構,隻有Tensor張量核心,支持FP8浮點計算,主要用於AI推理,也支持AI視頻編碼加速。
對比上代T4,L4的性能可加速2.2-3.1倍之多,最關鍵的是它功耗隻有72W,再加上單槽半高造型設計,可謂小巧彪悍。
幾乎所有的大型雲服務供應商都部署T4,升級到L4隻是時間問題,Google就已經開始內測。