今年6月份,AMD在美國舊金山宣佈新一代AI/HPC加速器InstinctMI300系列,包括全球首款APU加速器MI300A、新一代GPU加速器MI300X。當時,AMD隻公佈一部分技術細節,對於CPU/GPU核心數量、性能/功耗/能效等指標均未提及,也缺乏足夠多的應用案例。現在,魔術師終於揭曉他全部的秘密。
北京時間12月7日凌晨,美國加州聖何塞,AMD Advancing AI大會上,AMD正式公佈Instinct MI300系列加速器的詳細規格與性能,以及眾多的應用部署案例,將AI人工智能、HPC高性能計算提升到新的層次。

AI人工智能概念的誕生已經有將近70年歷史,歷經長期演化,已經深入人們工作生活的各個角落,隻是很多時候感知性並沒有那麼強,更多時候人們是通過一些節點性時間感受AI的威力。
早期像是IBM深藍超級計算機戰勝國際象棋大師卡斯帕羅夫,近期像是AlphaGo與李世石和柯潔的圍棋大戰,最近最火爆的當然是ChatGPT引發的大語言模型、生成式AI浪潮。
坦白說,大語言模型眼下似乎有些過熱,但從技術和前景的角度而言,AI絕對是未來,不管它以什麼形勢體現,這都是大勢所趨,也是一個龐大的市場,尤其是對算力的需求空前高漲。

一年前,AMD內部估計全球數據中心AI加速器市場在2023年的規模可達約300億美元,今後每年的復合增長率都能超過50%,到2027年將形成超過1500億美元的價值,不可限量。
如今看來,這個數據太保守,AMD已經將2023年、2027年的數據中心AI加速器市場規模預期分別調高到400億美元、4500億美元,年復合增長率超過70%。

AMD作為擁有最全解決方案的廠商,可以從各個角度滿足AI尤其是生成式AI對於超強算力、廣泛應用的需求:
GPU方面有世界領先的EPYC處理器,GPU方面有不斷壯大的Instinct加速器,網絡方面則有Alveo、Pensando等技術,軟件方面還有ROCm開發平臺,從而形成一個有機的、完整的解決方案。

AMD早期的計算加速器底層技術都來自和遊戲顯卡相同的RDNA架構,顯然缺乏針對性,於是誕生專門針對計算的CDNA架構。
第一代產品Instinct MI100系列是AMD首個可為FP32/FP64 HPC負載提供加速的專用GPU,第二代產品Instinct MI200系列則快速進化,在眾多超算系統中占據一些之地。
第三代的Instinct MI300系列基於CDNA3架構,分為數據中心APU、專用GPU兩條路線,重點提升統一內存、AI性能、節點網絡等方面的表現,再加上先進封裝、更高能效,以滿足生成式AI的強勁需求。

Instinct MI300X:1920億晶體管怪獸 完勝NVIDIA H100

Instinct MI300X屬於傳統的GPU加速器方案,純粹的GPU設計,基於最新一代CDNA3計算架構。
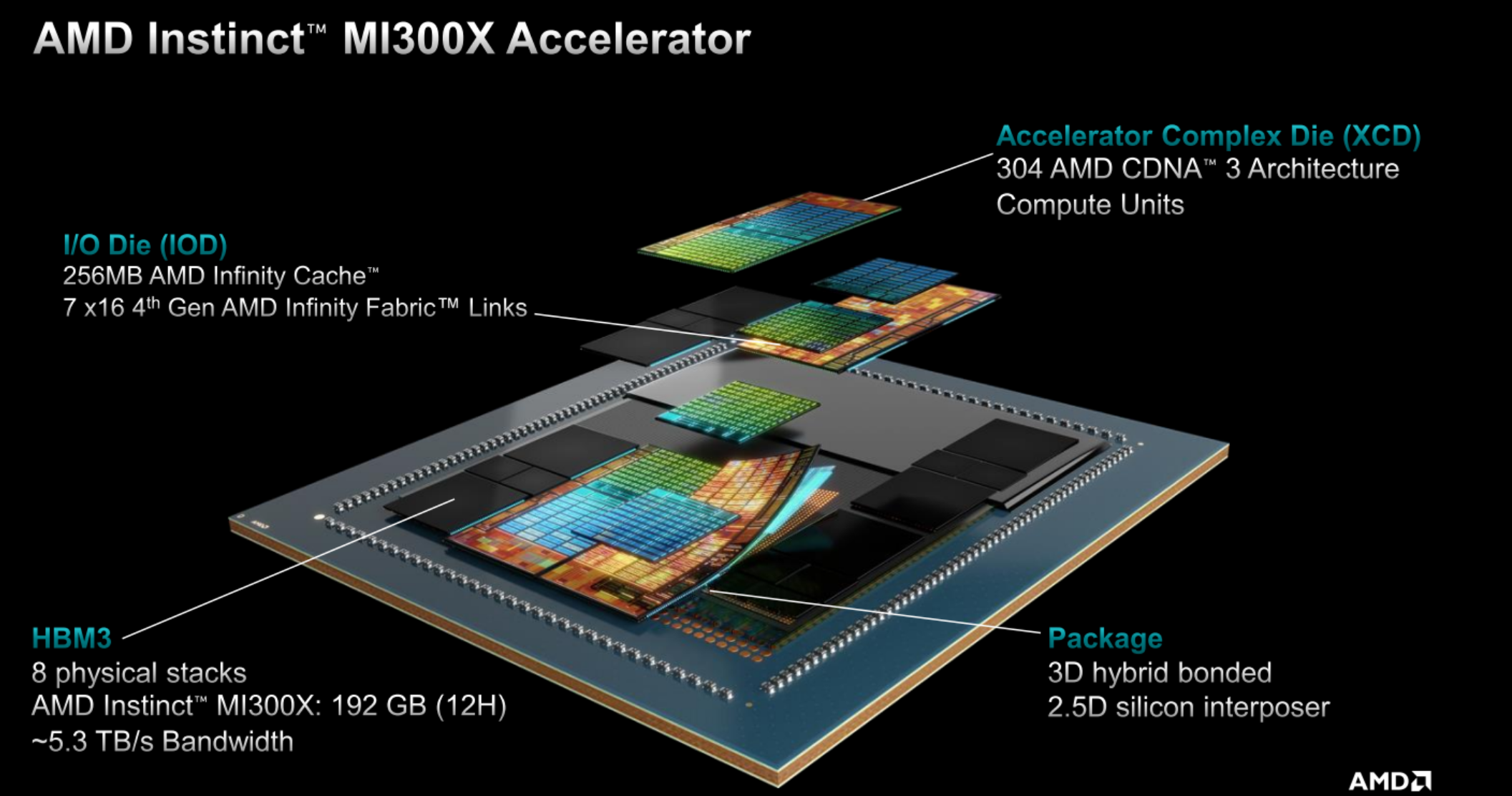

它集成八個XCD加速計算模塊(Accelerator Compute Die),每一個XCD擁有38個CU計算單元,總計304個單元。
每兩個XCD為一組,在它們底部放置一個IOD模塊,負責輸入輸出與通信連接,總共四個IOD提供多達七條滿血的第四代Infinity Fabric連接通道,總帶寬最高896GB/s,還有多達256MB Infinity Cache無限緩存。
XCD、IOD外圍則是八顆HBM3高帶寬內存,總容量多達192GB,可提供約5.3TB/s的超高帶寬。
AI/HPC時代,HBM無疑是提供高速支撐的最佳內存方案,AMD也是最早推動HBM應用和普及的。
以上所有模塊,都通過2.5D矽中介層、3D混合鍵合等技術,整合封裝在一起,AMD稱之為3.5D封裝技術。
總計晶體管數量多達1530億個,其中XCD計算核心部分是5nm工藝,負責中介、互連的部分則是6nm工藝。
順帶一提,結構示意圖中位於HBM內存之間的小號矽片,一共八顆,並無實際運算和傳輸作用,而是用於機械支撐、保證整體結構穩定。
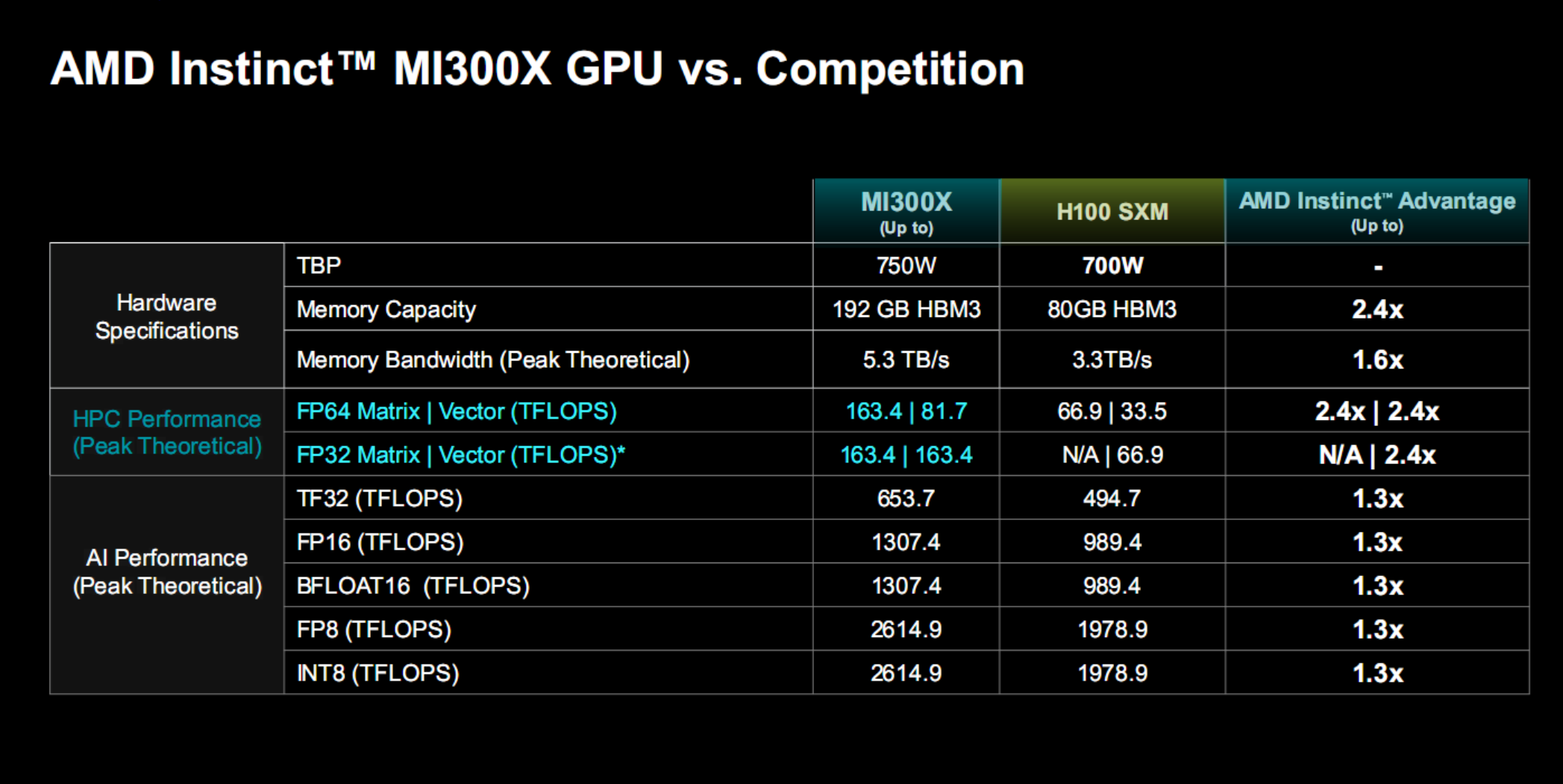
MI300X的各項性能指標都可以勝出NVIDIA H100(H200已宣佈但要到明年二季度才會上市所以暫時無法對比),還有獨特的優勢。
HPC方面,MI300X FP64雙精度浮點矩陣、矢量性能分別高達163.4TFlops(每秒163.4萬億次計算)、81.7TFlops,FP32單精度浮點性能則都是163.4TFlops,分別是H100的2.4倍、無限倍、2.4倍、2.4倍——H100並不支持FP32矩陣運算。
AI方面,MI300X TF32浮點性能為653.7TFlops,FP16半精度浮點、BF16浮點性能可達1307.4TFlops,FP8浮點、INT8整數性能可達2614.9TFlops,它們全都是H100的1.3倍。
TF32即Tensor Float 32,一種新的浮點精度標準,一方面保持與FP16同樣的精度,尾數位都是10位,另一方面保持與FP32同樣的動態范圍(指數位都是8位)。
BF16即Bloat Float 16,專為深度學習而優化的浮點格式。
另外,同樣適用HBM3高帶寬內存,MI300X無論容量還是帶寬都完勝H100,而整體功耗控制在750W,相比H100 700W高一點點。


更進一步,AMD還打造MI300X平臺,由八塊MI300X並聯組成,兼容任何OCP開放計算標準平臺。
這樣一來,在單個服務器空間內,就總共擁有2432個計算單元、1.5TB HBM3內存、42.4TB/s內存帶寬。
性能更是直接飛升,BF16/FP16浮點性能甚至突破10PFlops,也就是超過1億億次計算每秒,堪比中等規模的超級計算機。
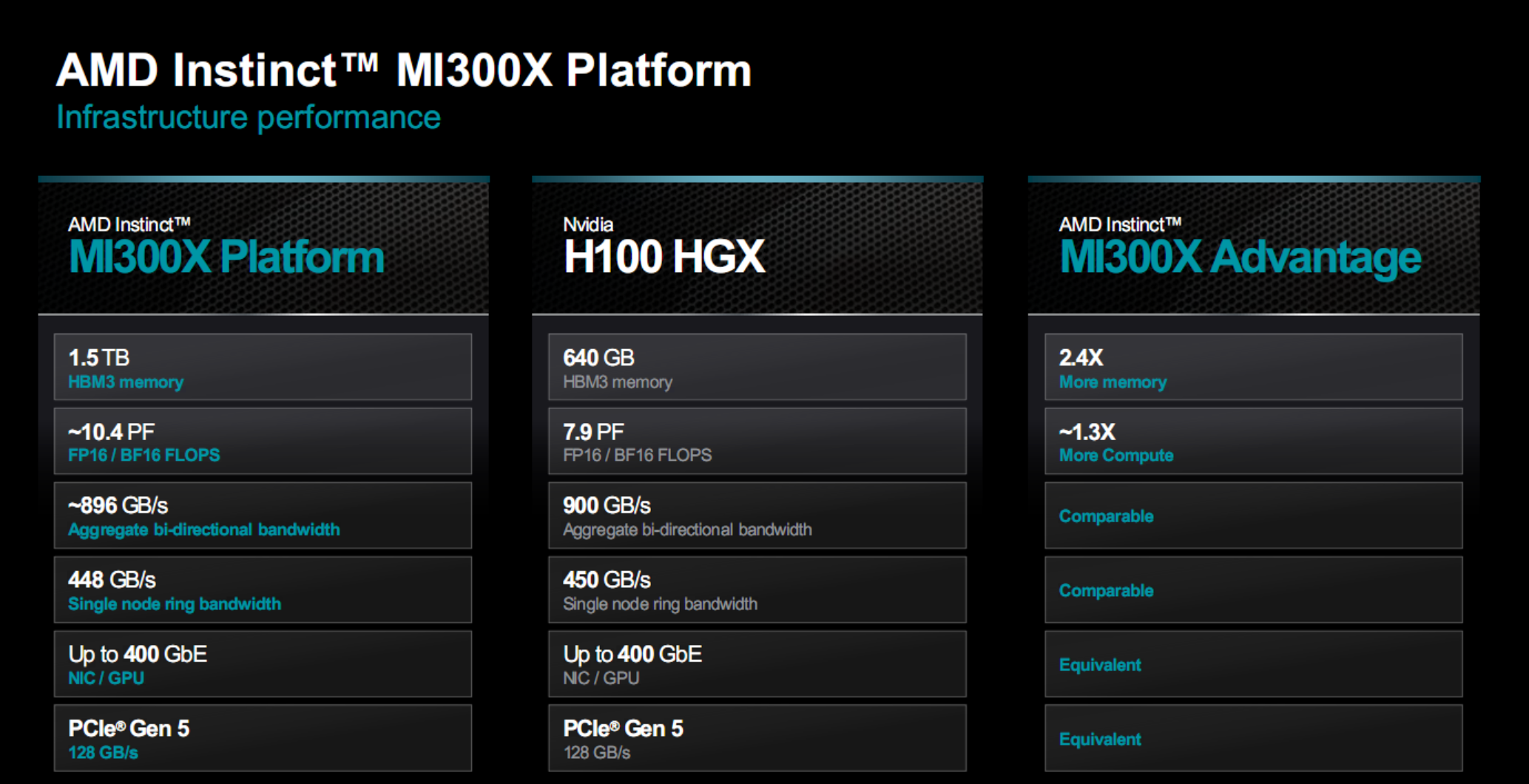
對比同樣八顆H100組成的計算平臺H100 HXG,它在計算性能、HBM3容量上也有不少的優勢,而在帶寬、網絡方面處於相當的水平。
尤其是每顆GPU可運行的大模型規模直接翻倍,可以大大提升計算效率、降低部署成本。
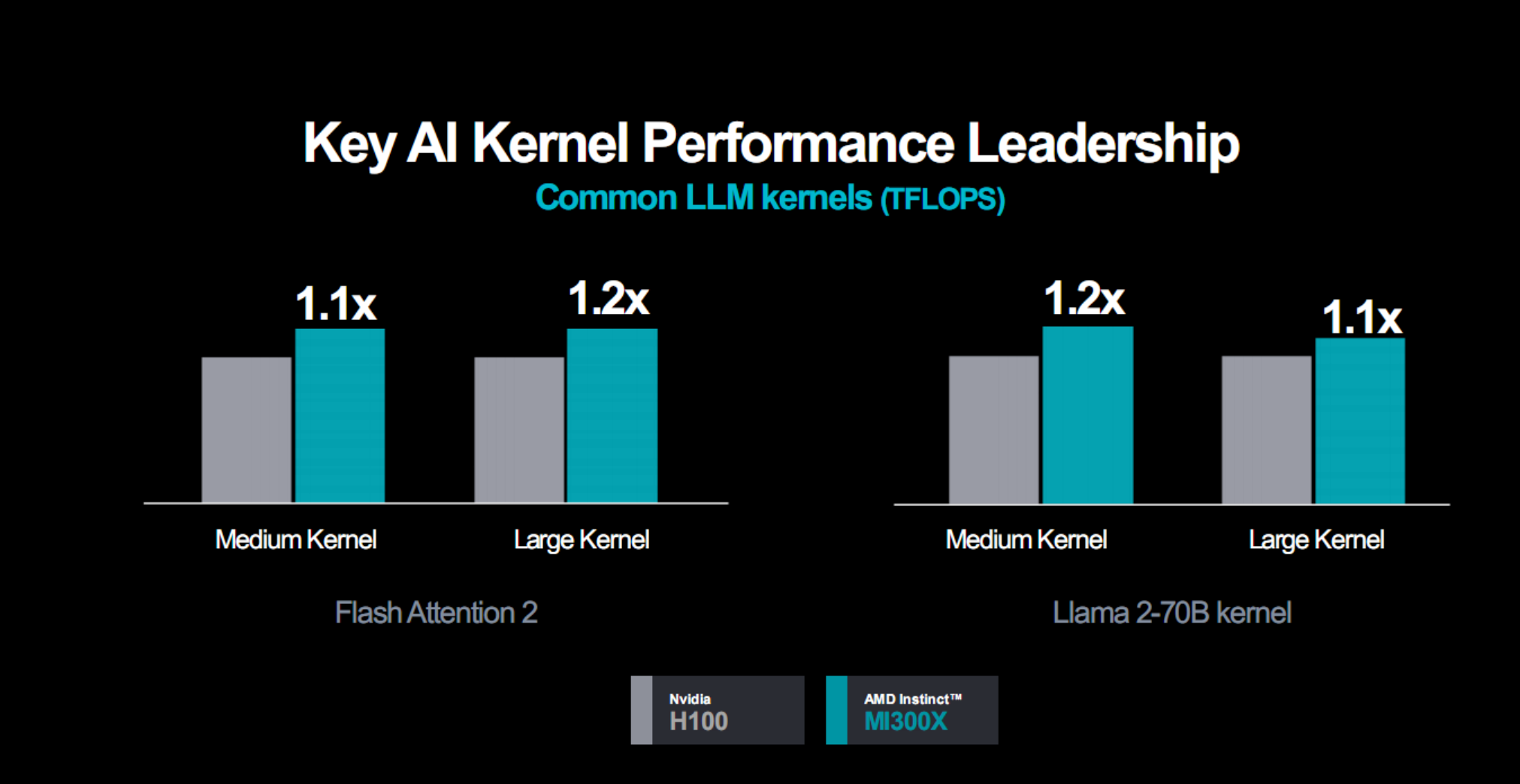
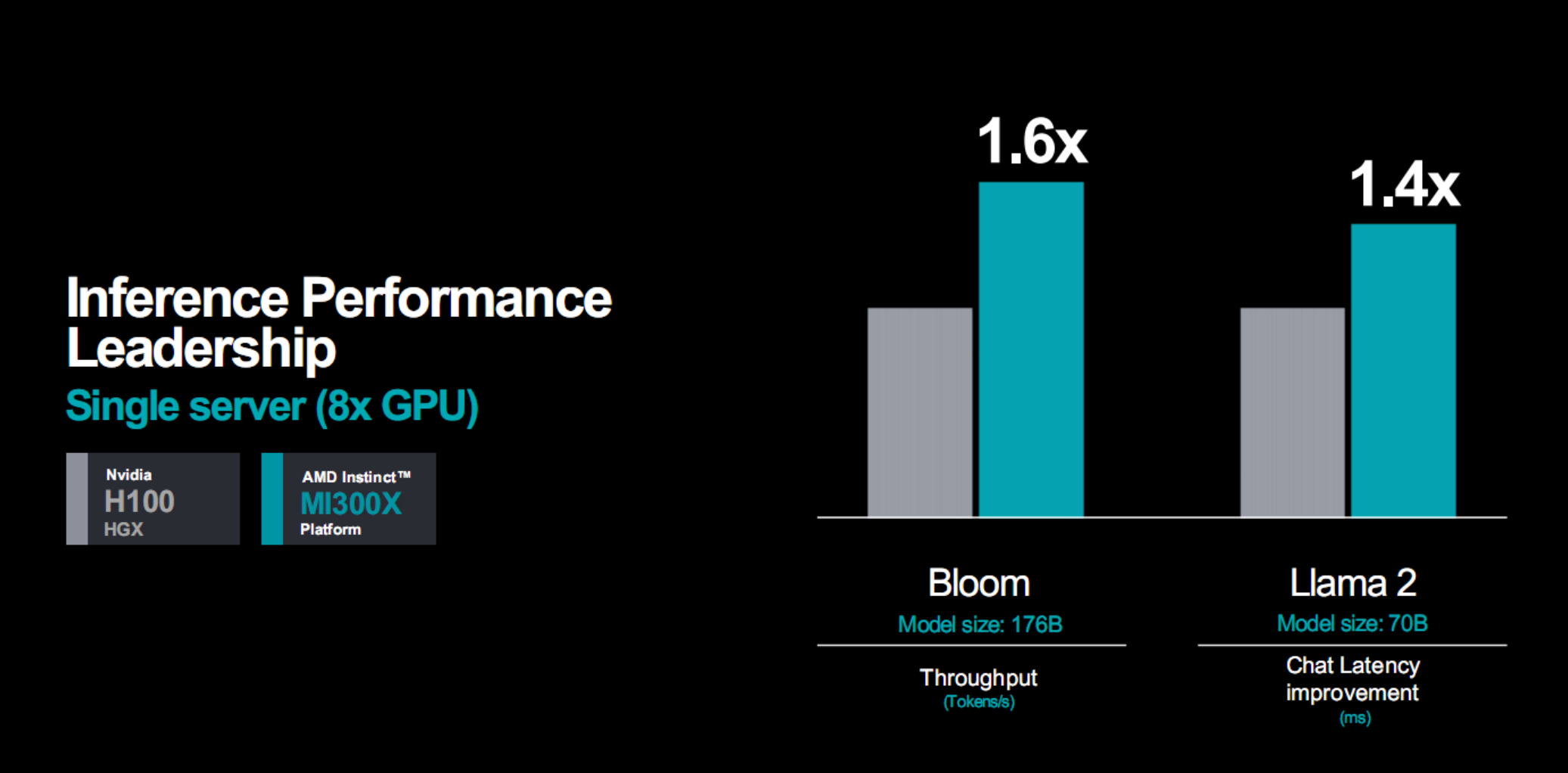


實際應用性能表現方面,看看AMD官方提供的一些數據,對比對象都是H100。
通用大語言模型,無論是中等還是大型內核,都可以領先10-20%。
推理性能,都是八路並聯的整套服務器,1760億參數模型Bloom的算力可領先多達60%,700億參數模型Llama 2的延遲可領先40%。
訓練性能,同樣是八路服務器,300億參數MPT模型的算力不相上下。
總的來說,無論是AI推理還是AI訓練,MI300X平臺都有著比H100平臺更好的性能,很多情況下可以輕松翻倍。



產品強大也離不開合作夥伴的支持,MI300X已經贏得多傢OEM廠商和解決方案廠商的支持,包括大傢耳熟能詳的慧與(HPE)、戴爾、聯想、超微、技嘉、鴻佰(鴻海旗下/富士康同門)、英業達、廣達、緯創、緯穎。
其中,戴爾的PowerEdge XE9680服務器擁有八塊MI300X,聯想的產品2024年上半年登場,超微的H13加速器采用第四代EPYC處理器、MI300X加速器的組合。

在基礎架構中引入MI300X的合作夥伴也相當不少,包括:Aligned、Arkon Engergy、Cirrascale、Crusoe、Denvr Dataworks、TensorWare,等等。
客戶方案方面,比如微軟的Azure ND MI300X v5系列虛擬機,比如甲骨文雲的bare metal(裸金屬) AI實例,比如Meta(Facebook)數據中心引入以及對於ROCm 6 Llama 2大模型優化的高度認可,等等。

Instinct MI300A:全球首個融合計算APU 沖擊二百億億次

如果說MI300X是傳統GPU加速器的一次進化,MI300A就是一場革命,CPU、GPU真正融合的方案目前隻有AMD可以做到。
相比之下,NVIDIA Grace Hopper雖然也是CPU、GPU合體,但彼此是獨立芯片,需要通過外部連接,放在一塊PCB板上,層級上還差一個檔位。
Intel規劃的融合方案Falcon Shores因為各方面原因已經暫時取消,短期內還是純GPU,未來再沖擊融合。
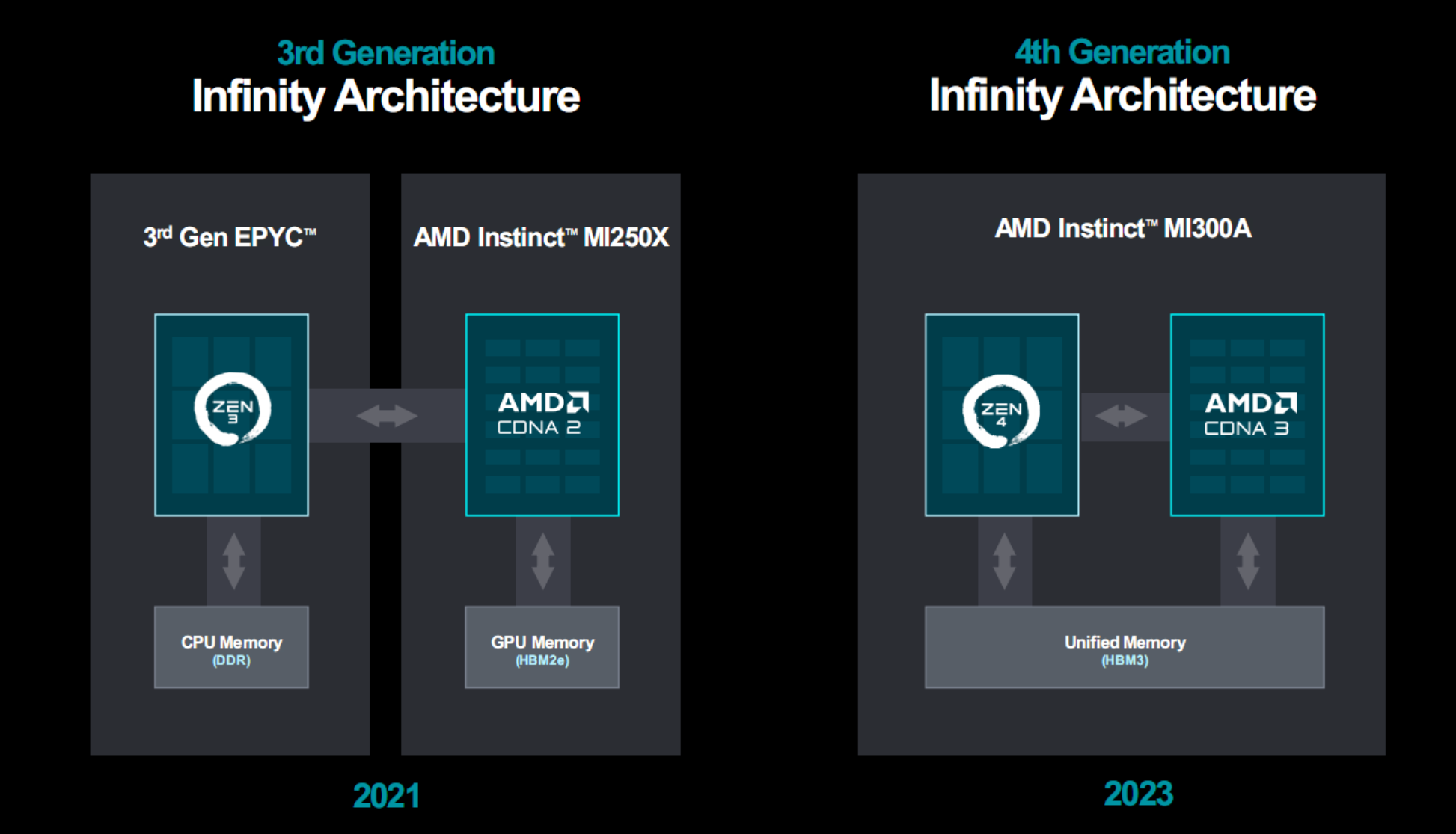
MI300A是全球首款面向AI、HPC的APU加速器,同時將Zen3 CPU、CDNA3 GPU整合在一顆芯片之內,統一使用HBM3內存,彼此全部使用Infinity Fabric高速總線互聯,從而大大簡化整體結構和編程應用。
這種統一架構有著多方面的突出優勢:
一是統一內存,CPU、GPU彼此共享,無需重復拷貝傳輸數據,無需分開存儲、處理。
二是共享無限緩存,數據傳輸更加簡單、高效。
三是動態功耗均衡,無論算力上側重CPU還是GPU,都可以即時調整,更有針對性,能效也更高。
四是簡化編程,可以將CPU、GPU納入統一編程體系,進行協同加速,無需單獨進行編程調用。
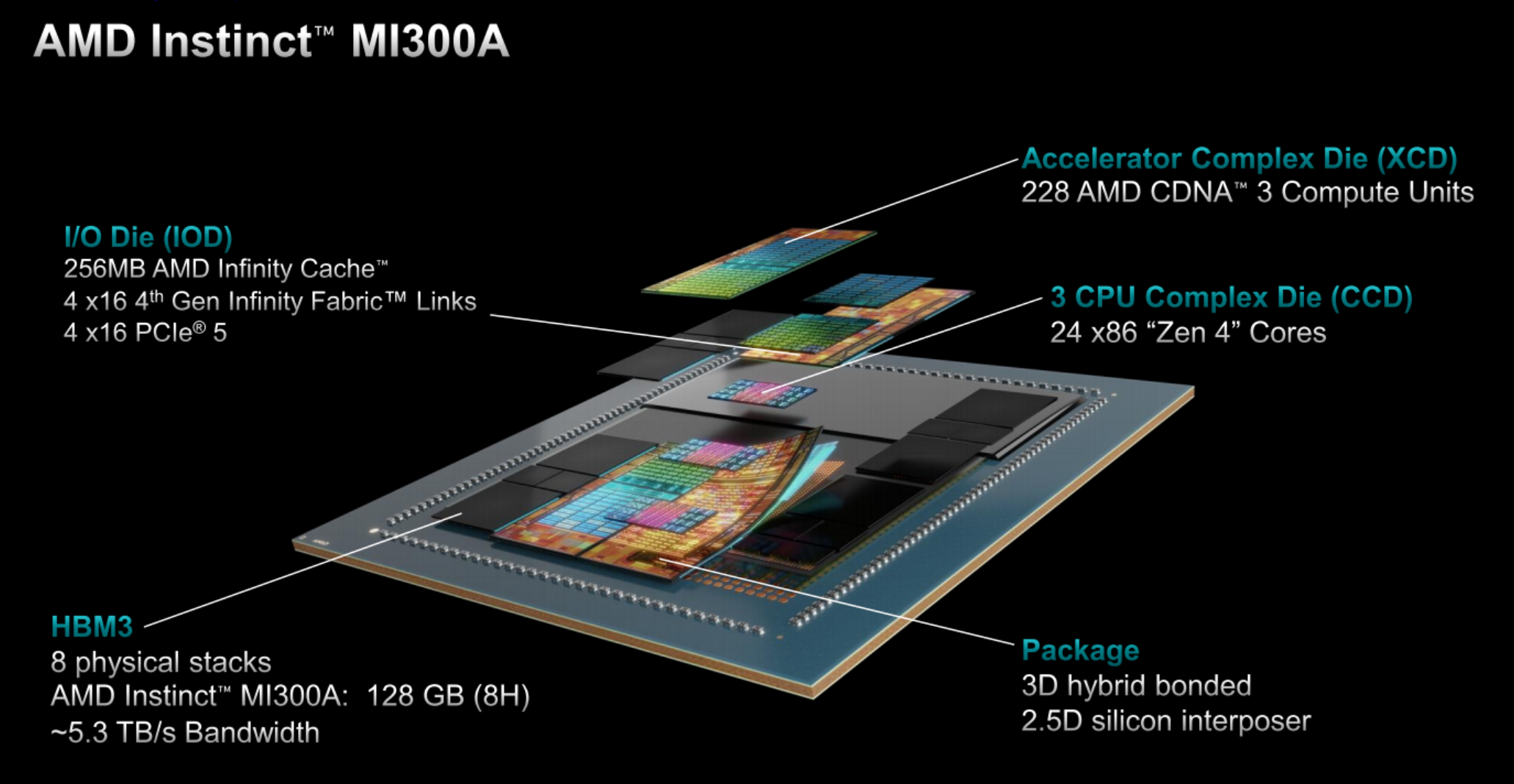

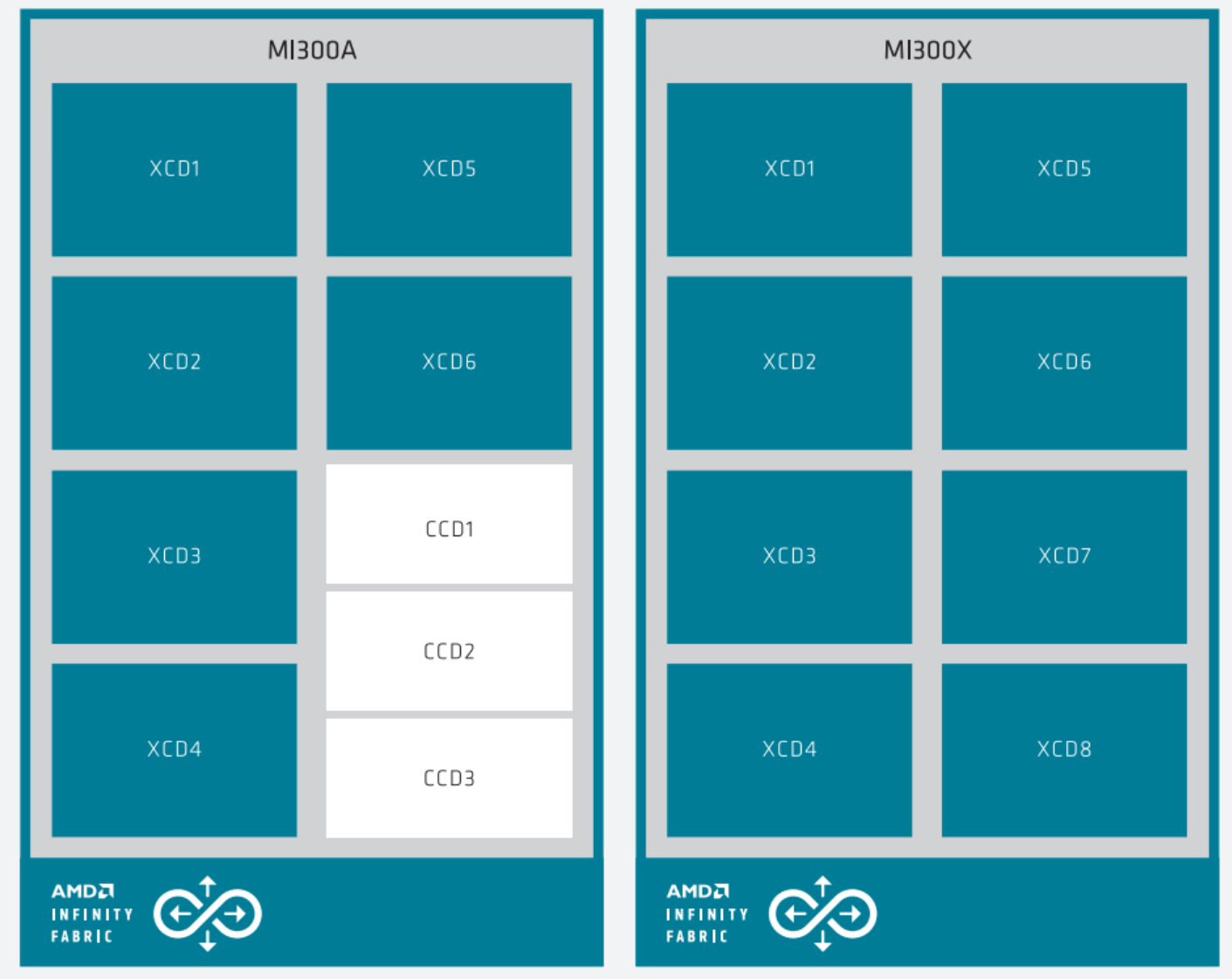
MI300A有六個XCD模塊,總計228個計算單元,另外兩個在MI300X上屬於XCD的位置換成三個CCD,總計24個CPU核心,後者和第四代EPYC 9004系列的CCD一模一樣,直接復用。
四個IOD、256MB無限緩存、八顆HBM3內存、3.5D封裝則都是和MI300X完全一致,唯一區別就是HBM3內存從12H堆疊降至8H堆疊,單顆容量從24GB降至16GB,總容量為128GB,但這不影響帶寬是同樣的5.3TB/s。
晶體管總量1460億個,其中XCD、CCD工藝都是5nm,中介、互連部分還是6nm,對外為獨立的Socket封裝接口。
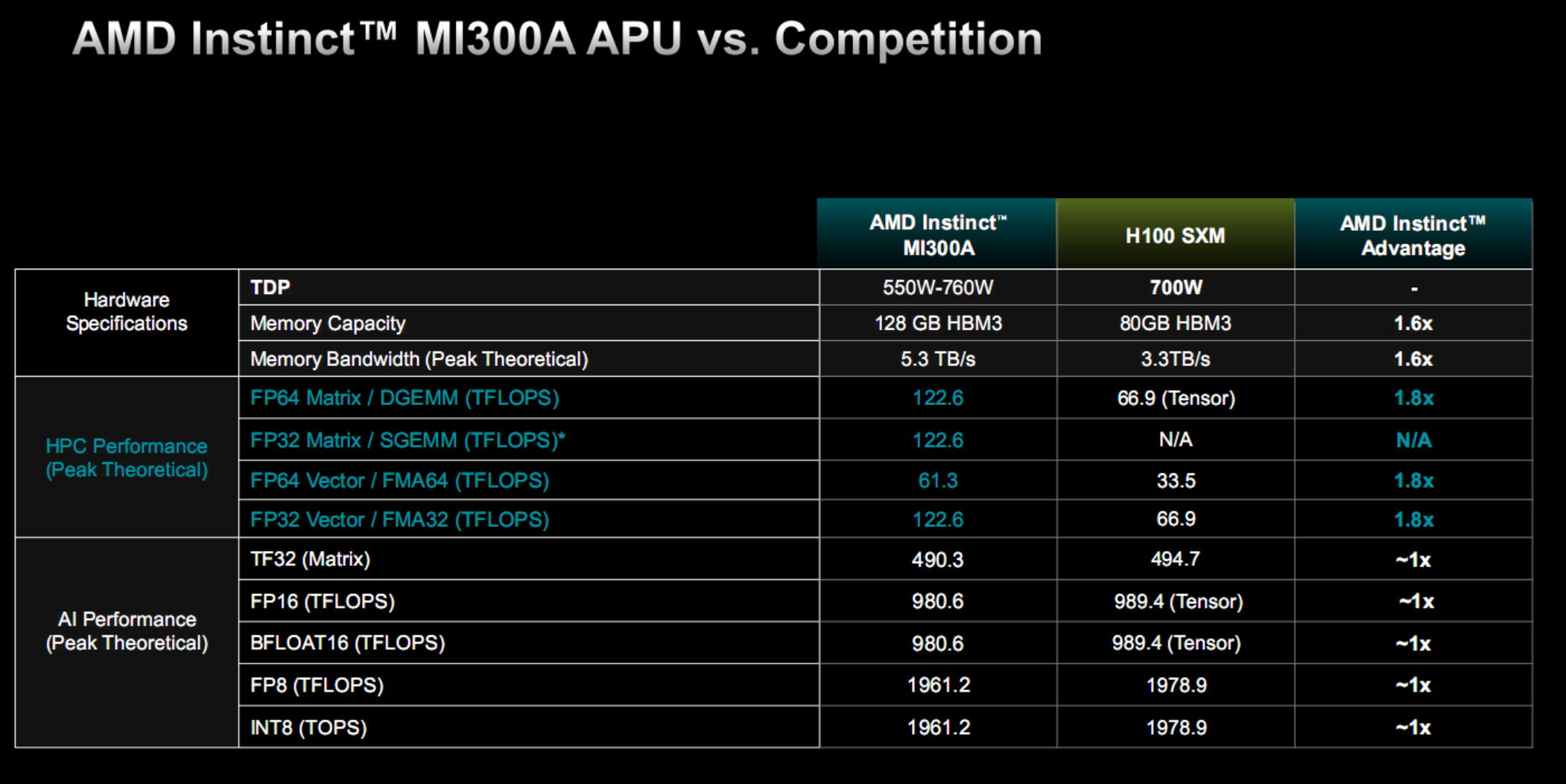
性能方面,MI300A FP64矩陣/矢量、FP32矢量表現都是HJ100的1.8倍(都不支持FP32矩陣),TF32、FP16、BF16、FP8、INT8則都是旗鼓相當。
其中,FP64矩陣、FP32/矢量性能都是122.6TFlops,FP64矢量性能則是61.3TFlops,都相當於MI300X的75%。
TF32性能493.0TFlops,FP16、BF16性能980.6TFlops,FP8、INT8性能1961.2TFlops,同樣也是MI300X的75%。
為什麼都是75%?因為XCD模塊少1/4,GPU核心自然就減少1/4,換言之這裡都是GPU性能,沒有包括CPU部分。
MI300A的整體功耗在550-760W范圍內,具體看頻率的不同規格設定。
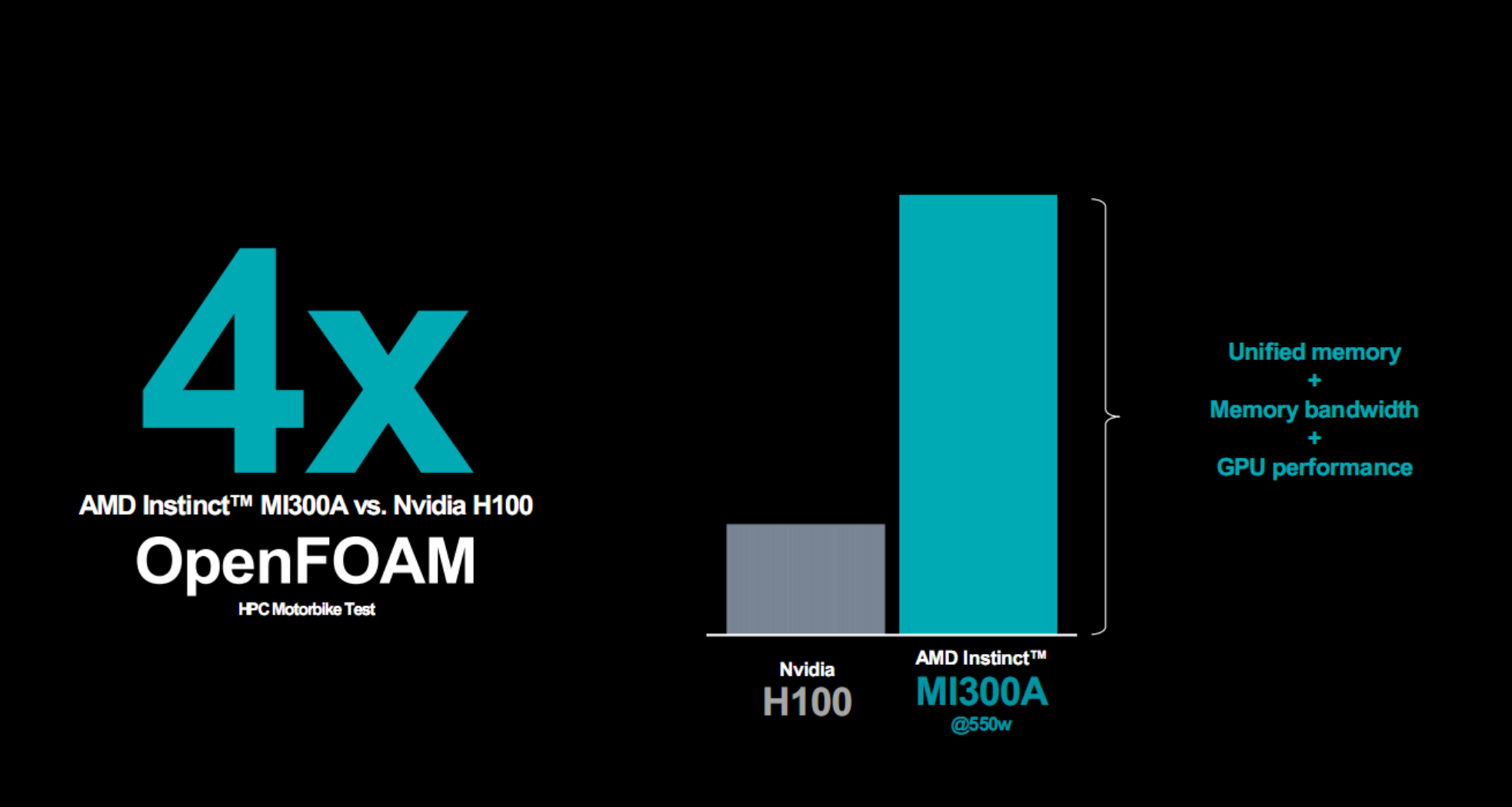
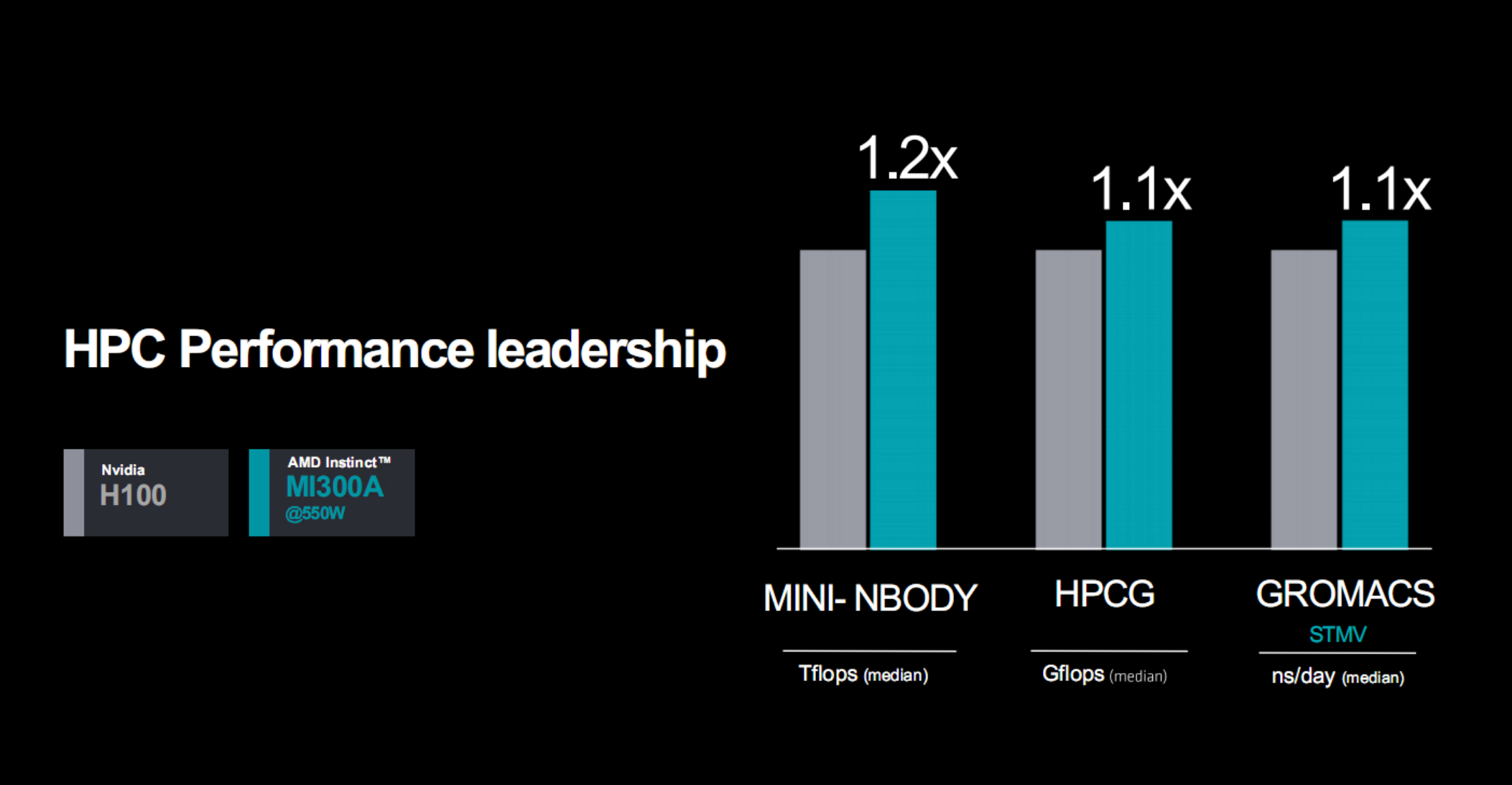
對比H100,MI300A隻需550W功耗就能在OpenFOAM高性能計算測試中取得多達4倍的優勢,不同實際應用中可領先10-20%。
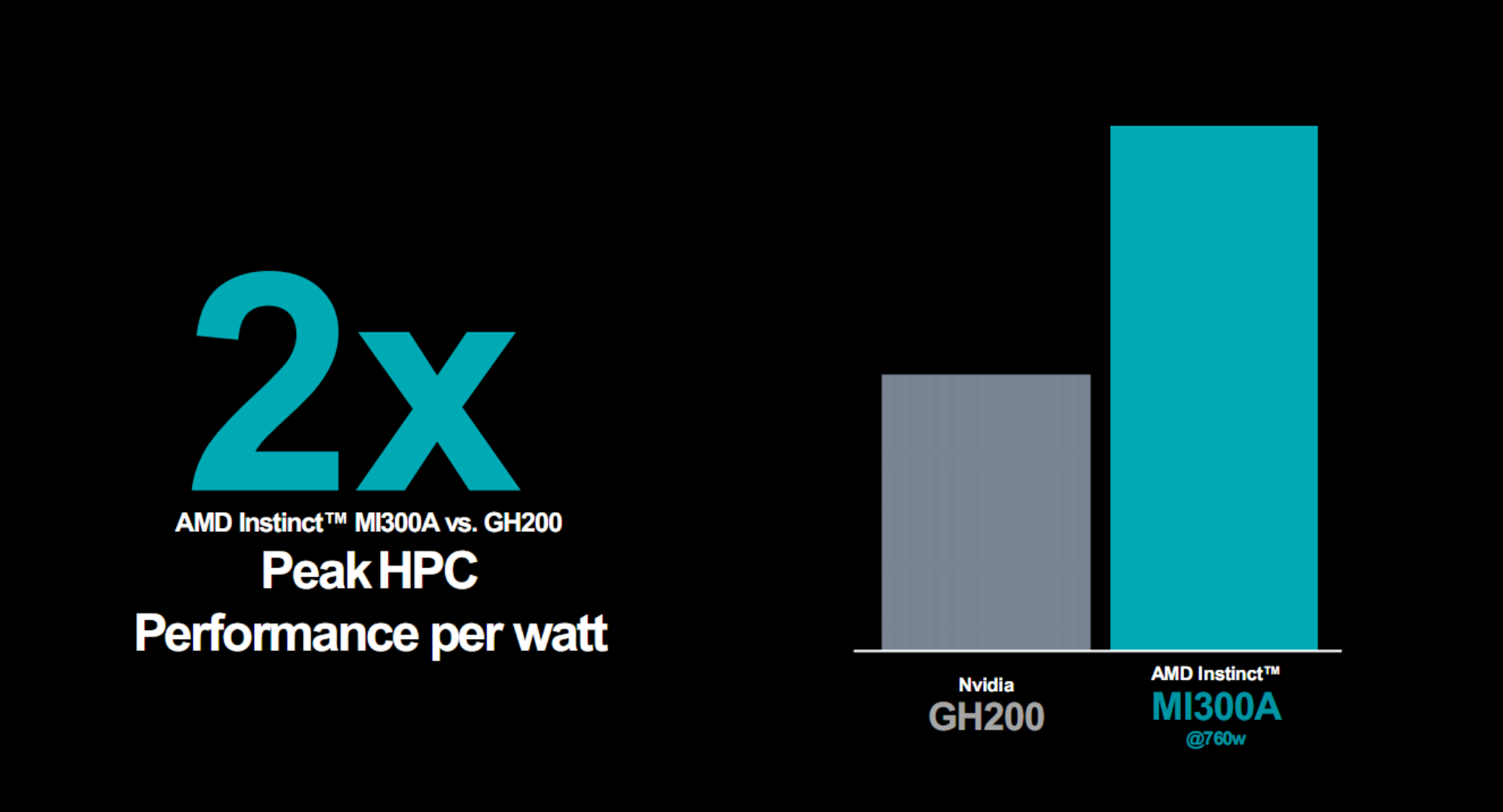
對比最新的GH200,MI300A 760W峰值功耗下的能效優勢,更可以達到2倍。

MI300A已經在美國勞倫斯利弗莫爾國傢實驗室的新一代超級計算機El Capitan中安裝。
它的設計目標是成為全球第一套200億億次超算,這也是第二套基於AMD平臺的百億億次級超算。

MI300A的OEM和方案合作夥伴陣容也在不斷擴大,目前已有慧與、Eviden(隸屬法國Atos)、技嘉、超微。
其中,慧與EX255a是首個基於MI300A的超算加速器刀片服務器,將於2024年初上市。

目前,AMD Instinct系列加速器已經在眾多企業、高校、科研機構得到應用,尤其是在超級計算機領域初露崢嶸,11月份發佈的最新一期超算500排行榜上拿下前25名的5個席位,比如第一名的美國橡樹嶺國傢實驗室Frontier、第五名的芬蘭LUMI,都應用MI250X。
同時,Instinct加速器還占據綠色超算500排行榜上前10名中的7個席位,包括6個MI250X、1個MI210,其中Frontier TDS第二、LUMI第三,足可見其高能效。
這也是AMD 30x25目標的一個重要節點——AMD致力於在2020-2025年間將服務器處理器、AI/HPC加速器的能效提升多達30倍。
軟件生態:ROCm 6全面進化 軟硬結合提速8倍
好馬配好鞍,一如遊戲顯卡必須有驅動程序配合才能釋放性能潛力,AI/HPC加速器的發揮也離不開開發平臺和工具的全力輔佐。


AMD ROCm就是這樣的一套開放軟件平臺,如今來到全新一代ROCm 6。
它重點針對大語言模型額和生成式AI進行優化和提升,以及強化支持開放開源、拓展生態支持、加入更多AI庫等等。

比如在大語言模型優化方面,支持開源大模型推理加速框架vLLM,並優化推理庫,延遲性能提升可達2.6倍;
支持的高性能圖形分析與學習框架HIP Graph,優化運行時,延遲性能可提升1.4倍;
支持高效內存的註意力算法Flash Attention,優化內核,延遲性能可提升1.3倍。
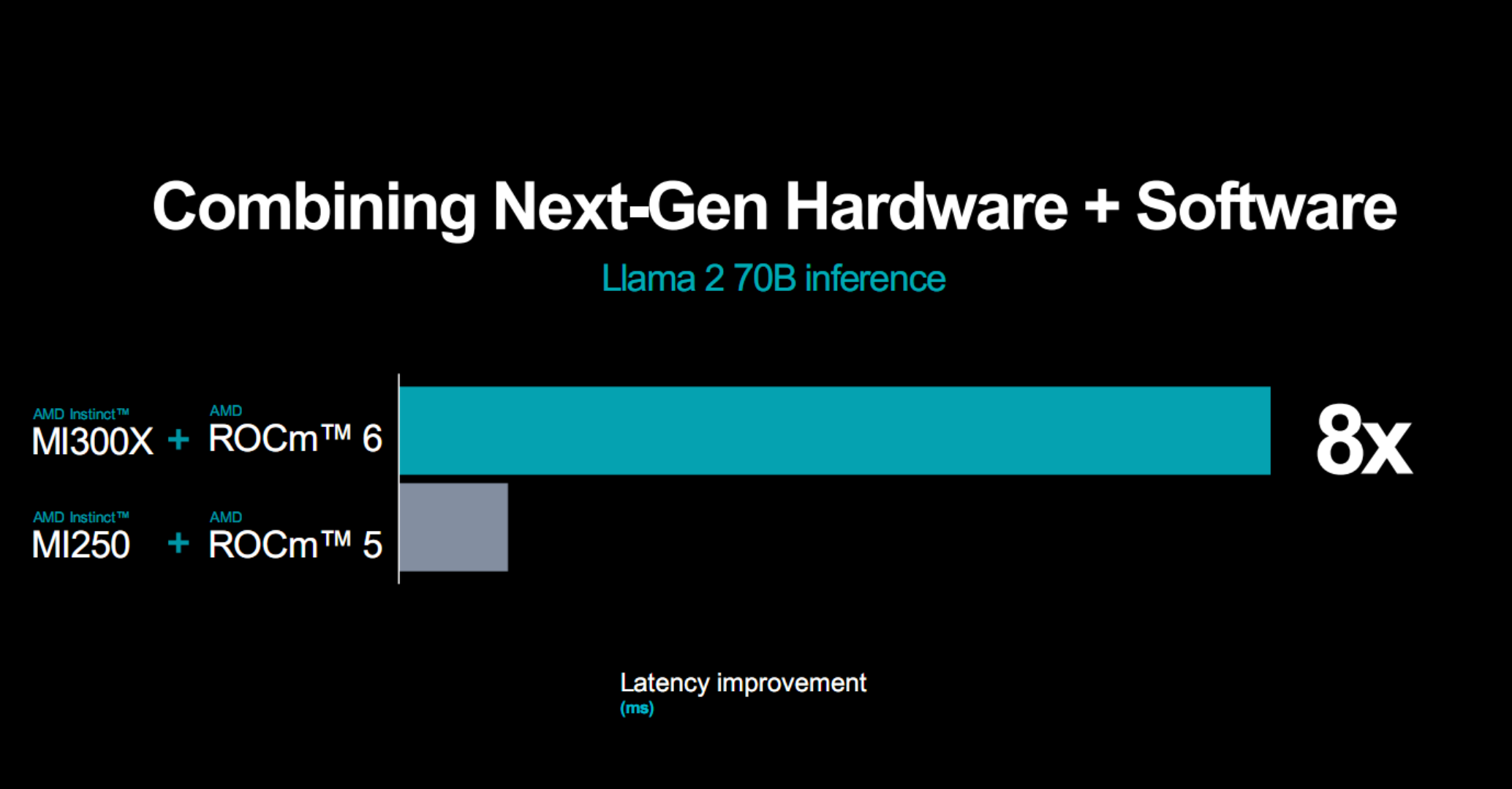
新一代硬件加新一代開發平臺的威力是相當猛的,比如MI300X、ROCm 6的組合相比於MI250X、ROCm 5,運行270億參數Llama 2大模型推理,延遲性能可改善多達8倍!
當然,ROCm 6平臺也會陸續支持老平臺硬件,進一步挖掘潛力。
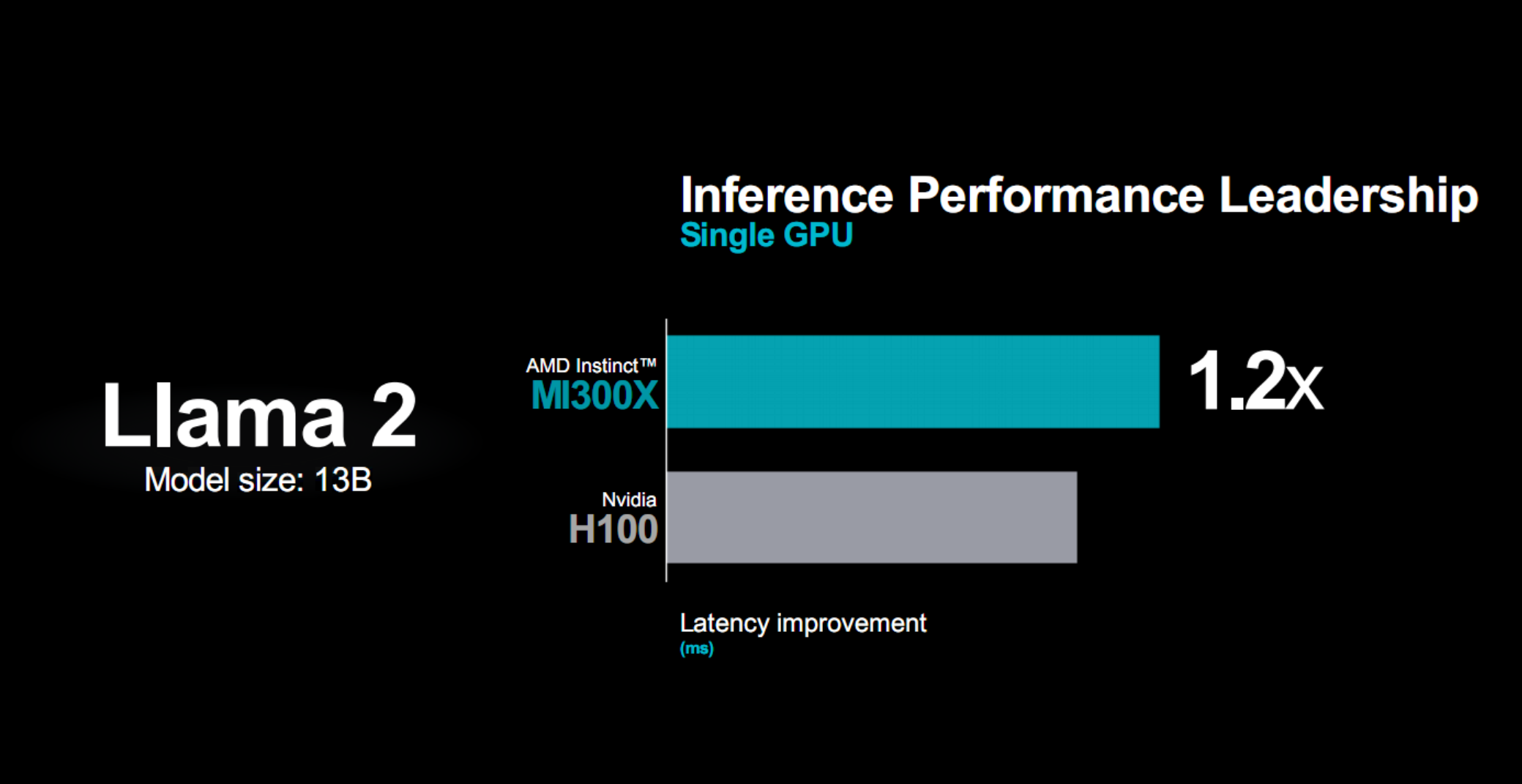
而對標競品,比如130億參數的Llama 2大模型,MI300X的延遲性能相比H100可以領先20%。

生態支持方面,ROCm 6也在快速拓展,尤其是基於AMD一貫以來的開放開源路線,一方面積極為開源社區貢獻自己的開發庫,另一方面可以充分利用各種開放開源的AI模型、算法和框架,包括Hugging Face、PyTorch、TensorFlow、Jax、OAI Triton、ONNX,等等。
其中,OpenAI會在即將發佈的Triton 3.0版本中正式支持AMD GPU,未來和你對話的ChatGPT背後可能就是AMD Instinct在驅動。

總的來看,AMD新一代Instinct MI300X/MI300A加速器在硬件上有著藝術級的精妙設計和世界領先的計算性能、能效,尤其是真正融合的APU走在行業的最前列,開拓全新的可能。
再加上EPYC CPU處理器、網絡方案的配合,為生成式AI推理、訓練和應用提供強大的算力平臺基礎。
在軟件開發、生態合作上,AMD同樣積極與時俱進,開放擁抱社區、擁抱產業,簡化開發與應用流程,大大增強自身競爭力,前途無量,值得期待。
