AGI如何定義、又何時到來?來自GoogleDeepMind的創始人兼首席AGI科學傢ShaneLegg向我們描述當下我們與AGI的距離。10月26日,在X上有三萬訂閱的DwarkeshPodcast(矮人播客)主持人DwarkeshPatel采訪GoogleDeepMind的創始人兼首席AGI科學傢ShaneLegg。
他們討論AGI出現的時間節點、可能的AGI新架構、作為下一個行業標桿的多模態、如何讓超越人類的模型進行對齊以及Deepmind在模型能力和安全之間的抉擇。
而在前不久,《華爾街日報》與OpenAI的CEO Sam Altman和CTO Mira Murati共同探討有關AGI的未來(鏈接)。
一場又一場的AGI討論盛宴接連不斷,曾經隻存在於科幻作品中的AGI,似乎近在眼前。
01 AGI的定義以及發生節點
在衡量AGI的進展之前,需要先對AGI進行定義。
AGI,即通用人工智能。但對於什麼是“通用”的,卻有很多不同的定義,這讓回答AGI是什麼變得非常困難。
Shane Legg認為,能夠執行一般人類完成的認知任務、甚至超越這個范圍以上的,就可以認為是AGI。

由此可以得到,要測試AI是否正在接近或達到這個閾值,我們需要對其進行不同類型的、涵蓋人類認知廣度的測量。
但這非常困難,因為我們永遠不會擁有人們“能做到的事”的完整集合,這個范圍太過於龐大而且還在不斷更新。
因此,在判斷是否為AGI時,如果一個人工智能系統在所有能提出的人類認知任務上達到人類的表現水平,就可以認為這就是AGI。
在通常的理解中,可能存在有一些事情是人類可以做到但機器做不到的。但當我們窮盡各種嘗試也找不到這樣的“事情”後,人類就擁有通用人工智能。
但在實際的測量中我們仍不能提出包含人類全部認知水平的任務,如著名的基準測試:測量大規模多任務語言理解(Measuring Massive Multitask Language Understanding,MMLU)盡管包含多項人類知識領域,但缺少語言模型對流視頻的理解。
此類任務的缺失也指出一個問題:現在的語言模型不像人類擁有情景記憶。
我們的記憶包括工作記憶,即最近發生的事情;皮層記憶存在於大腦皮層中。在工作記憶到皮層記憶之間還有一個系統,即情景記憶,由海馬體負責。
情景記憶主要用於快速學習和記住特定的事件或信息,它允許我們在不同時間點回想起過去發生的事情,就像你可以回憶起畢業典禮的場景,包括穿著學士袍的樣子、畢業帽的顏色、畢業典禮演講者的言辭,以及與同學們一起慶祝的情景。
情節記憶在幫助我們建立個人經歷和學習新信息方面起著重要作用。
但模型並不具備這樣的功能,隻是通過增加上下文窗口的長度(更像是工作記憶)來彌補模型記憶的缺陷。
從另一種角度來說,情景記憶幫助人類擁有非常高的樣本效率,可以從較少的樣本中學到更多的信息。
對於大型語言模型而言,它們也可以在上下文窗口中利用信息,以實現某種程度的樣本效率,但這與人類的學習方式略有不同。
模型能夠在它們的上下文窗口中迅速學習信息,這是一種快速的、局部的學習過程,可以幫助它們在特定上下文中適應。
但在實際的模型訓練時,它們會經歷一個更長的過程,處理數萬億個標記的數據,以更全面地學習語言的結構和規律。
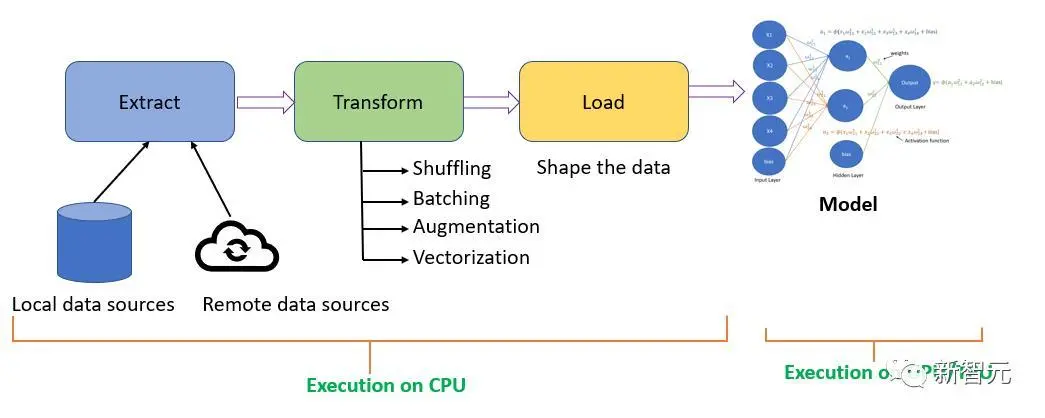
而這兩個階段之間可能會存在某些學習機制或過程的缺失,這可能導致模型在某些情況下無法很好地理解或處理信息。
但Shane Legg並不認為模型不具備情景記憶會是一種基礎限制。
相較於過去,大型語言模型發生根本性的變化。現在,我們知道如何構建具有一定理解程度的模型,擁有可擴展的方法來實現這一點,從而為解鎖許多全新的可能性打開大門。
“現在我們有相對清晰的前進路徑,可以解決現有模型中大部分不足之處,無論是關於妄想、事實性、它們所具備的記憶和學習方式,還是理解視頻等各種各樣的事情。
我們隻需要更多的研究和工作,所有這些問題都將得到改善,或迎刃而解。”
回到一開始的問題:如何衡量人工智能何時達到或超越人類水平?

Shane Legg表示,“這不是一個單一的因素就可以解決的,而這就是問題的本質。
因為它涉及到通用智能。我們必須確保它可以完成很多不同的任務,並且不會出現哪怕一個漏洞。”
我們已經擁有可以在某些領域表現非常令人印象深刻,甚至超越人類水平的系統。
Shane Legg表示,他想要一整套非常全面的測試,當有人想要用對抗的方式提出機器無法做到、人類卻能做到的事,在這些人無法成功時我們就到達AGI。
在DeepMind的早期研究中,很多任務都涉及到人工智能在開放環境中的操作。
這符合Shane Legg試圖提出的對智力的定義和測量,即能夠在不同的領域和不同的任務中表現良好。
這與模型性能的能力和性能的廣度有關。
在評估智能時,存在一種框架能夠根據任務和環境的復雜性進行加權。
這種權衡有點像奧卡姆剃刀原理,傾向於加權那些更簡單、更重要的任務和環境。
柯爾莫哥洛夫復雜度(Kolmogorov complexity )中,存在一個自由參數,即參考機器(reference machine)。
參考機器的選擇可以影響智能度量的結果,它可以改變不同任務和環境在度量中的權重和分佈。
但選擇合適的參考機器仍然是一個未解決的問題,因為沒有一種通用的參考機器,通常情況下,人們會使用圖靈機作為參考。
Shane Legg認為,解決這個問題最自然的做法是思考對人類而言智能的含義。
人類智能在我們生活的環境中意義重大,它確實存在、並對世界產生深遠的影響,具有強大的力量。
如果AI能夠達到人類水平的智能,這將在經濟和哲學層面產生重要的影響,如改變經濟結構,並涉及到我們對智能的哲學理解。
而從歷史角度來看,這也是一個重要的轉折點。
因此,以人類智能作為參考機器的選擇在多個方面都具有合理性。
另一個原因則是純粹的科爾莫哥洛夫復雜性定義實際上是不可計算的。
02 我們需要新的AI架構嗎?
關於AI的情境記憶的缺陷問題,Shane Legg認為這涉及到模型的架構問題。
當前的LLMs架構主要依賴於上下文窗口和權重,但這不足以滿足復雜的認知任務。
大腦在處理情景記憶時采用不同的機制,可以快速學習特定信息,這與緩慢學習深層次的通用性概念不同。
然而,一個綜合的智能系統應該能夠同時處理這兩種任務,因此我們需要對架構進行改進。
以人類智能作為參考機器觀點出自於Shane Legg2008年的論文。
他在當時提出一種用於衡量智能的方法,即壓縮測試(compression test),它涉及填充文本樣本中的單詞以衡量智能。
這種方法與當前LLMs的訓練方式非常吻合,即基於大量數據進行序列預測。
這涉及到Marcus Hutter的AIXI理論以及Solomonoff歸納。
Solomonoff歸納是一種理論上非常優雅且樣本效率極高的預測系統,雖然它無法在實際計算中應用。
但Shane Legg表示,使用Solomonoff歸納作為基礎,就可以構建一個通用代理,並通過添加搜索和強化信號來使其成為通用人工智能,這就是AIXI的原理。
如果我們擁有一個出色的序列預測器,或者是Solomonoff歸納的某種近似,那麼,從這一點出發構建一個非常強大、通用的AGI系統隻是另一個步驟。
Shane Legg說,這正是我們今天所看到的情況:
這些極其強大的基礎模型實際上是非常出色的序列預測器,它們根據所有這些數據對世界進行壓縮。
然後我們將能夠以不同的方式擴展這些模型,並構建非常強大的代理。
03 DeepMind的“超級對齊”
“對齊”(Alignment)指的是確保AI系統或通用人工智能(AGI)系統的目標、行為和決策與人類價值觀、倫理準則和目標一致的過程。
這是為防止AI系統出現不符合人類價值觀或可能帶來危險的行為,並確保它們在處理倫理問題時能夠做出符合道德的決策。
DeepMind在當下流行的強化學習和自博弈,如如 Constitution AI 或 RLHF方面,已有數十年的深耕。
在解決具有人類智能水平的模型安全問題上,DeepMind持續做著努力:
模型可解釋性、過程監督、紅隊、評估模型危險等級,以及與機構和政府聯手開展工作......
而Shane Legg認為,當AGI水平的系統出現時,試圖限制或遏制其發展不是一個好的選擇。
我們要做的是調整這個模型,使其與人類的倫理價值高度一致,從一開始就具備高度道德倫理性。
這需要系統能夠進行深入的世界理解,良好的道德倫理理解,以及穩健且可靠的推理能力。
可靠的AGI不應該像當前的基礎模型那樣僅僅輸出“第一反應”,而應該具備“第二系統”的能力,進行深入的推理和道德分析。
Shane Legg提到,要確保AGI系統遵循人類倫理準則首先應該對系統進行廣泛的倫理培訓,確保其對人類倫理有很好的理解。
在這個過程中,社會學傢和倫理學傢等各方需要共同決定系統應該遵循的倫理原則和價值觀。
並且,系統需要被工程化,以確保其在每次決策時都會使用深刻的世界理解和倫理理解進行倫理分析。
此外,我們也需要不斷對系統的決策過程和推理過程進行審核,以確保其正確地進行倫理推理。
但要確保系統遵循倫理原則,審核同樣重要。
我們需要向系統明確指定應該遵循的倫理原則,並通過對其進行審核來確保系統始終如一地遵循這些原則,至少與一組人類專傢一樣好。

此外,也要警惕強化學習可能帶來的潛在危險,因為過度強化可能導致系統學習欺騙性行為。
對是否需要建立一種框架,以在系統達到一定能力水平時制定具體的安全標準這個問題上,Shane Legg認為這是意義的,但也相當困難。
因為制定一個具體標準,本身就是一個具有挑戰性的任務。
04 安全還是性能?
在DeepMind創立之前,Shane Legg就一直擔心AGI的安全性。

但在早期,聘請專業人員從事通用人工智能安全工作是一項艱難的挑戰。
即使曾在這個領域發佈過AGI安全性研究論文,他們也不願意全職從事這項工作,因為他們擔心這可能會對他們的職業生涯產生影響。
而DeepMind一直在這個領域積極開展研究,並多次強調AGI安全性的重要性。
關於DeepMind對AI進展的影響,Shane Legg表示,DeepMind是第一傢專註於AGI的公司,一直擁有AGI安全性團隊,同時多年來發表許多關於AGI安全性的論文。

這些工作提高AGI安全性領域的可信度,而在不久之前,AGI還是一個較為邊緣的術語。
Shane Legg承認,DeepMind在某種程度上加速AI的能力發展,但也存在一些問題,例如模型幻覺。
但另一方面,DeepMind的AlphaGo項目確實改變一些人的看法。
然而,Shane Legg指出AI領域的發展不僅僅取決於DeepMind,其他重要的公司和機構的參與也至關重要。
Shane Legg認為盡管DeepMind可能加速某些方面的進展,但很多想法和創新通常在學術界和工業界之間自然傳播,因此很難確定DeepMind的影響程度。
但在關於AGI安全性的問題上,Shane Legg沒有選擇最樂觀的研究方向,而是提到一種名為“Deliberative Dialogue”的決策方法。

它旨在通過辯論來評估代理可以采取的行動或某些問題的正確答案。
這種方法可以將對齊擴展到更強大的系統中。
05 AGI來臨的時間點
2011年,Shane Legg在自己的一篇博客文章中對通用人工智能(AGI)到來的時間點進行預測:
“我之前對AGI何時到來做一個對數正態分佈的預測,其中2028年是均值,2025年是眾數。我現在依然保持我的觀點,但前提是不發生核戰這類瘋狂的事件。”
Shane Legg解釋他的預測基於兩個重要觀點:
首先,機器的計算能力將在未來幾十年內呈指數增長,同時全球數據量也將呈指數增長。
當計算和數據量都呈指數增長時,高度可擴展算法的價值會不斷提高,因為這些算法可以更有效地利用計算和數據。
其次,通過可擴展算法的發現、模型的訓練,未來模型的數據規模將遠遠超過人類一生中所經歷的數據量。
Shane Legg認為這將是解鎖AGI的第一步。因此,他認為在2028年之前有50%的機會實現AGI。但那時人們也可能遇到現在預期之外的問題。
但在Shane Legg看來,目前我們遇到的所有問題都有望在未來幾年內得到解決。
我們現有的模型將變得更完善,更真實,更及時。
多模態將會是模型的未來,這將使它們變得更加有用。
但就像硬幣的兩面,模型也可能會出現被濫用的情形。
06 多模態未來
最後,Shane Legg提到下一個AI領域的裡程碑將會是多模態模型。
多模態技術將會把語言模型所具備的理解能力擴大到更廣泛的領域中。
當未來的人們回想起我們現在擁有的模型,他們可能會想:“天哪,以前的模型隻能算是個聊天對話框,它們隻能處理文本。”
而多模態模型可以理解圖像、視頻、聲音,當我們和它們進行交流時,多模態模型將更解發生什麼。
這種感覺就像是系統真的嵌入到真實的世界中。
當模型開始處理大量視頻和其他內容時,它們將會對世界有一個更為根本的理解,以及其他各種隱含的知識。