2023年2月,GoogleCEO桑達爾・皮查伊(Sundar・Pichai)對內發佈一份“紅色代碼”預警,要求Google旗下用戶超10億的產品盡快接入生成式AI,以對抗來勢洶洶的ChatGPT。這一舉動給人一種Google“慌”的感覺,因為ChatGPT的到來已經威脅到Google核心的搜索業務:如果大傢都習慣用ChatGPT這類AI對話引擎直接得到答案,誰還會去Google搜索呢?誰還
乍看起來,這一切都發生地非常突然,Google應對起來也很被動。但其實,早在 2018 年,Google內部就已經有工程師拉響警報,指出 AI 正在對Google的業務帶來風險,尤其是網頁搜索。
眾所周知,Google借助用戶交互數據對搜索結果進行排名。通過觀察用戶與搜索結果頁面的交互方式(點擊結果、後退、點擊其他內容),Google能夠知道哪些頁面與特定查詢最相關。多年來,這幫助Google保持搜索相關性的領先地位,因為它比其他任何搜索引擎都擁有更多的用戶交互數據。
但在 2018 年底,Google的工程師們突然意識到一個驚人的問題:復雜的語言模型最終將能夠僅通過網頁文本理解網頁,而無需任何用戶反饋。而這可能會危及Google在搜索領域長達 20 年的優勢,這種威脅甚至可能來自一傢小型初創公司。
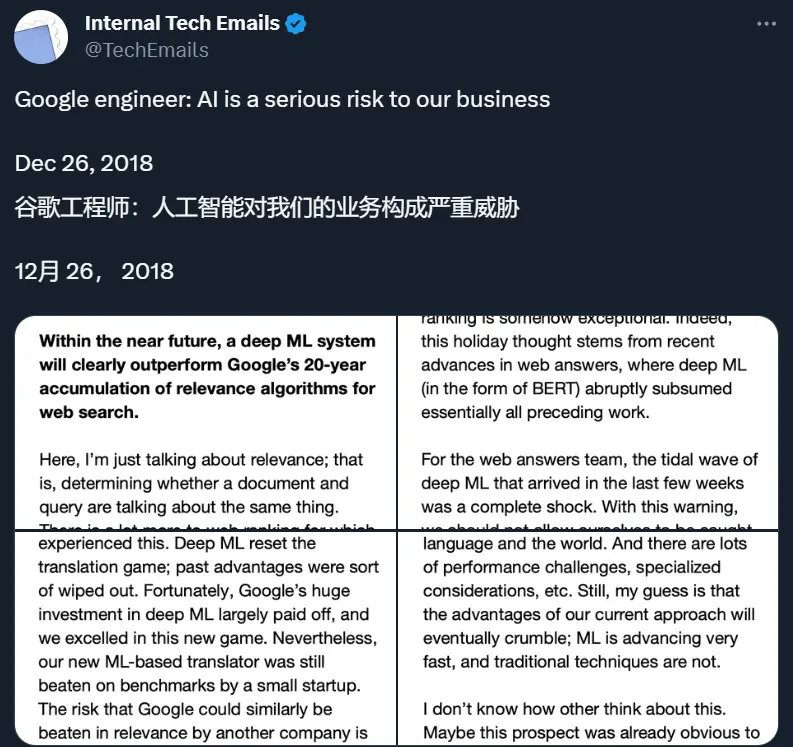
Google資深軟件工程師 Eric Lehman 就是早早意識到這一問題的工程師之一。為表達自己的這份擔憂,他還專門寫一份郵件:
我想寫寫我在假期期間思考的一個問題:
在不遠的將來,深度機器學習系統將明顯優於Google 20 年來積累的網頁搜索相關性算法。
此處我所討論的僅限於“相關性”—— 即判斷一個文檔與一個查詢討論的是否為同一主題。網頁排名還涉及許多其他方面,在這些方面,機器學習似乎不那麼適用。但我認為,基本的相關性是網頁排名的核心任務,足夠“客觀”,可以很有效地使用 ML。
沒有人能預見未來,但我敢打賭,這幾乎肯定會在 5 年內成為現實,甚至可能在 6 個月內成為現實。類似於網頁排名的問題一個接一個被解決,幾乎沒有理由認為網頁排名會是個例外。實際上,這個問題思考的出發點是源於 AI 最近在網絡問答方面取得的進展,深度 ML(具體來說是 BERT)突然取代之前幾乎所有的工作。
對於網頁問答團隊來說,過去幾周深度 ML 帶來的巨變是完全出乎意料的。有這次預警,我們不應再被意外打敗;相反,我們應該從現在開始考慮其後果。而且,“現在”正是時候,因為我預計在新的一年裡,很多網頁排名工程師將會反思 BERT,並開始沿著這些相同的線路思考。
一個需要考慮的事實是,這樣的深度 ML 系統可能會在Google之外的地方被開發出來 —— 比如在微軟、百度、Yandex、亞馬遜、蘋果…… 甚至是一個創業公司。在我的印象中,翻譯團隊已經有過這種經歷。深度 ML 徹底改變翻譯領域;過去的優勢被一掃而空。幸運的是,Google在深度 ML 上的巨大投資得到回報,我們在這個新領域表現出色。然而,我們的新 ML 翻譯器在基準測試中仍然被一傢小型創業公司超越。
我們可以從 BERT 中得出一個驚人的結論:大量的用戶反饋在很大程度上可以被原始文本的無監督學習所取代。這可能會對Google產生重大影響,導致Google在相關性方面輸給其他公司。
網絡搜索中的相關性可能不會很快被深度 ML 所顛覆,因為我們依賴的記憶系統遠大於任何當前的 ML 模型,並且包含大量關於語言和世界的重要知識。此外還有許多性能挑戰和特殊考慮等。盡管如此,我認為我們當前方法的優勢最終會消失;ML 正在迅速進步,而傳統技術則不然。
我不知道其他人怎麼看。個人而言,我傾向於認為這個未來幾乎是不可避免的,但我還沒有深入思考其後果。我們可能需要思考的一些問題包括:
我們能不能現在就采取措施,確保自己引領這一變革,而不是成為變革的犧牲品?就我個人而言,我不想在未來幾年,人們回顧時認為,“那些堅守傳統網頁排名方法的人被新潮流碾壓,而他們卻毫無預警……”我們能否制定一個 2019 年的合作目標,結合研究力量,利用深度模型擊敗我們現有的最佳預測呢?
我們如何在不打擊士氣的情況下與從事網頁排名工作的人討論這個可能的未來?
我聽說翻譯團隊幾年前就決定“all in”大規模 ML,現在回想起來,這似乎是明智之舉。今天,我對圍繞相關性采取如此極端的措施持懷疑態度,因為從現在到深度 ML 方法真正占據主導地位的這段時間裡,我們可能會犧牲傳統方法所取得的重大成果 —— 我認為這至少還需要幾年的時間。然而,聽到 BERT 的警示而不調整我們的計劃似乎也是不明智的。
在Google內部,Eric Lehman 可能不是唯一發現並指出這一問題的人。在此之後,Google也確實采取一些做法來更新自己的搜索系統。比如,在 2019 年 10 月,Google正式宣佈,他們的搜索引擎用上 BERT,能夠改善 10% 的搜索結果。一年後,Google又宣佈,幾乎所有的英文搜索都用上 BERT 。
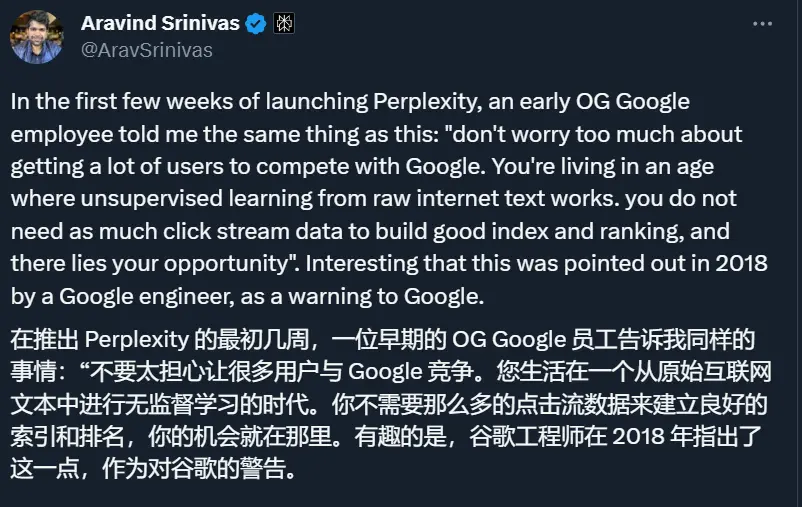
不過,在之後的兩三年裡,Google並沒有采取更激進的措施,比如直接做一個基於大型語言模型的搜索系統,直接給用戶答案。這就給很多創業公司提供機會,比如 AI 驅動的搜索引擎 perplexity。
這傢公司的 CEO 表示,在推出 perplexity 的最初幾周,一位Google老員工就對他說過,“不用太擔心吸引大量用戶來與Google競爭。你生活在一個可以從原始網絡文本中進行無監督學習的時代。你並不需要那麼多點擊流數據就能構建出好的索引和排名系統,這就是你的機會。”
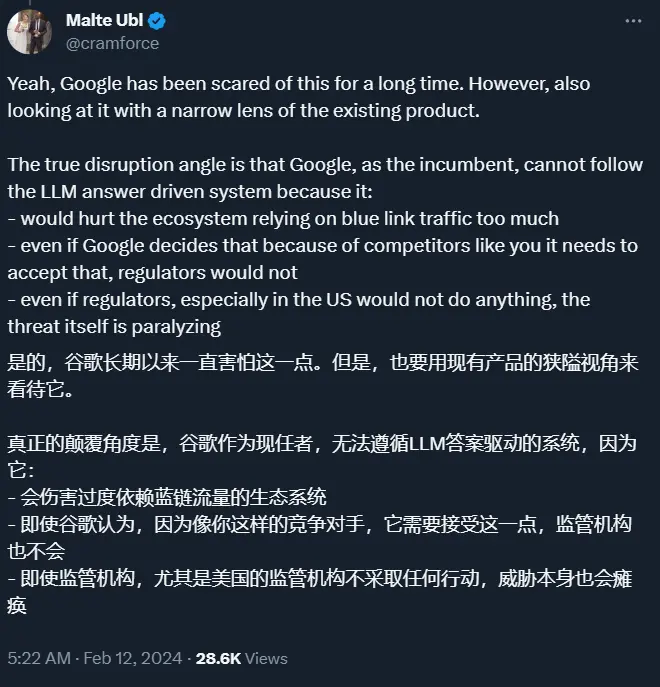
那麼,Google為什麼沒有再接再厲,及早推出基於大型語言模型的搜索系統呢?有人分析出Google當時的幾個顧慮:
會對依賴藍色鏈接(即傳統搜索結果鏈接)流量的生態系統造成太大傷害:Google搜索的一個主要功能是將用戶引導到其他網站,而采用 LLM 答案系統可能會直接提供答案而非鏈接,這樣會減少引導到外部網站的流量,對依賴這種流量的網站造成影響。
即使Google決定因為競爭對手的壓力而接受這種變化,監管機構可能也不會同意。從監管的角度看,直接提供答案而減少對其他網站鏈接的引用可能會引起關於市場壟斷和競爭公平性的擔憂。
即使在美國,監管機構可能不采取行動,這種威脅本身也是令人癱瘓的:這意味著,即便沒有實際的監管幹預,僅僅是存在這種可能性和隨之而來的法律和公眾壓力,就足以使Google在采取這種策略方面猶豫不決。
在 ChatGPT 走紅之初,Meta 首席人工智能科學傢 Yann LeCun 也表達過類似想法,表示大公司確實更難以推動這種大的革新,因為他們面臨的公眾、監管壓力要更大。
後面的故事走向大傢都很熟悉:除像 perplexity 這樣的搜索新秀,Google還要應對來自微軟的威脅,後者通過與 OpenAI 合作,將自己的搜索引擎徹底重構,打造新必應。
不過,在過去的一年裡,微軟的新搜索業務並沒有對Google形成真正的威脅。根據美國網站流量統計服務商 Statcounter 公佈的統計數據,2023 年 2 月 Bing 在全球市場的份額是 3.03%,在一年時間過去後,其市場份額僅僅隻是達到 3.4%。這可能和新必應使用體驗不佳、提示工程門檻較高等因素有關。與此同時,基於最新的 Gemini Ultra 模型,Google對於搜索引擎的重構步伐也在加快。看起來,雖然行動慢一些,Google搜索的地位暫時還無人可以撼動。