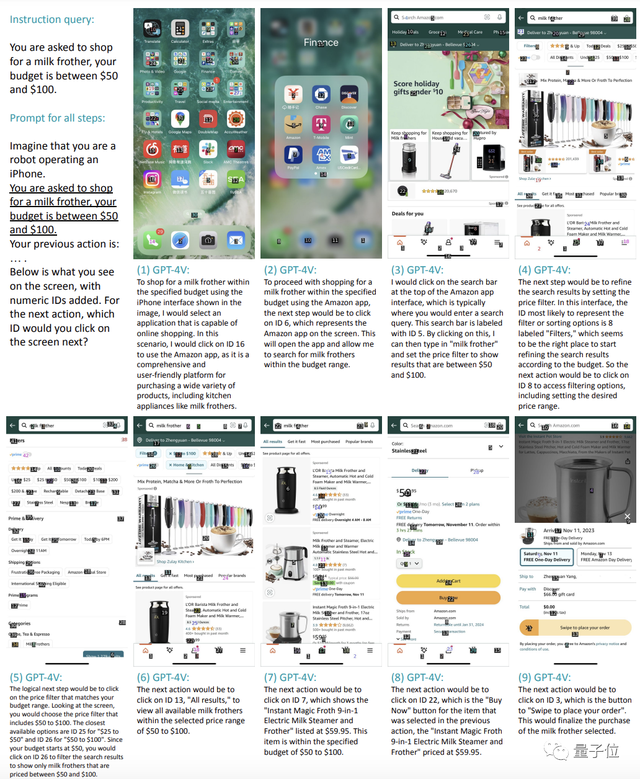
一項研究發現:無需任何訓練,GPT-4V就能直接像人類一樣與智能手機進行交互,完成各種指定命令。比如讓它在50-100美元的預算內購買一個打奶泡的工具。它就能像下面這樣一步一步地完成選擇購物程序(亞馬遜)並打開、點擊搜索欄輸入“奶泡器”、找到篩選功能選擇預算區間、點擊商品並完成下單這一系列共計9個操作。
根據測試,GPT-4V在iPhone上完成類似任務的成功率可達75%。
因此,有人感嘆有它,Siri漸漸就沒有用武之地(比Siri更懂iPhone)
誰知有人直接擺擺手:
Siri壓根兒一開始就沒這麼強好嘛。(狗頭)

還有人看完直呼:
智能語音交互時代已經開始。我們的手機可能要變成一個純粹的顯示設備。

真的這麼?
GPT-4V零樣本操作iPhone
這項研究來自加州大學聖地亞哥分校、微軟等機構。
它本身是開發一個MM-Navigator,也就是一種基於GPT-4V的agent,用於開展智能手機用戶界面的導航任務。
實驗設置
在每一個時間步驟,MM-Navigator都會得到一個屏幕截圖。
作為一個多模態模型,GPT-4V接受圖像和文本作為輸入並產生文本輸出。
在這裡,就是一步步讀屏幕截圖信息,輸出要操作的步驟。
現在的問題就是:
如何讓模型合理地計算出給定屏幕上應該點擊的準確位置坐標(GPT-4V隻能給出大概位置)。
作者給出的解決辦法非常簡單,通過OCR工具和IconNet檢測每一個給定屏幕上的UI元素,並標記不同的數字。
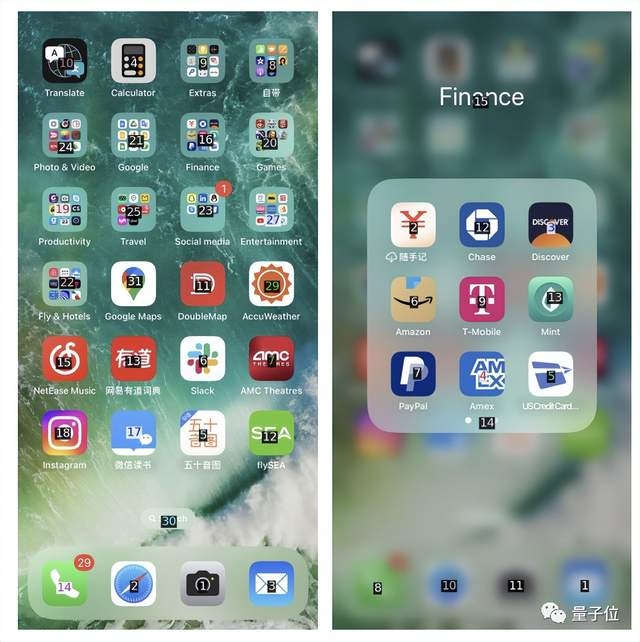
這樣一來,GPT-4V就隻需面對一張截圖指出要點什麼數字進行操作就好。
兩項能力測試
測試率先在iPhone上展開。
要想成功操縱手機涉及到GPT-4V不同類型的屏幕理解能力:
一個是語義推理,包括理解屏幕輸入和闡明完成給定指令所需的動作。
一個是指出每一個動作應執行的精確位置(即該點哪個數字)的能力。
因此,作者開發兩組測試分別進行區分。
1、預期動作描述
隻輸出應該幹啥,不輸出具體坐標。
在這個任務中,GPT-4V理解指令並給出操作步驟的準確率為90.9%。
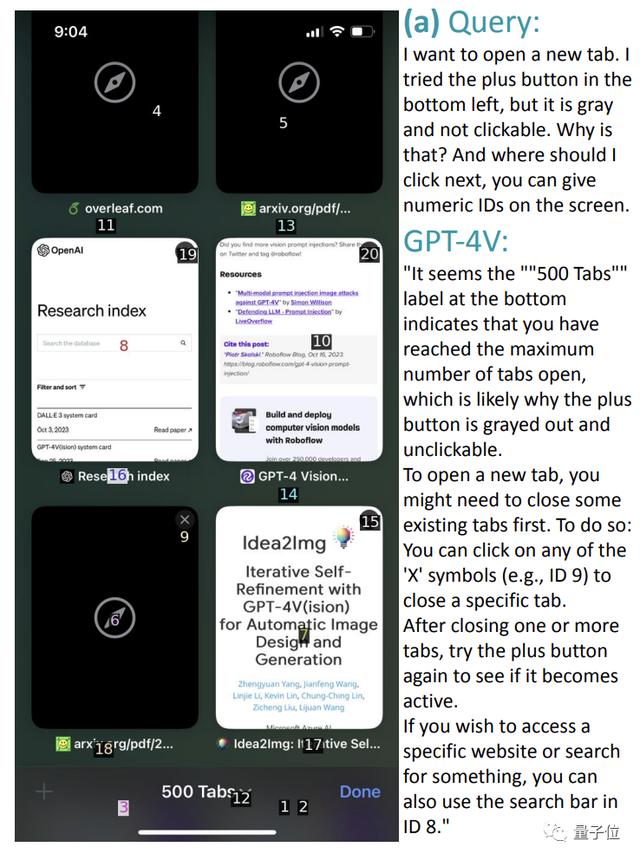
比如在下面這個Safari瀏覽器的截圖中,用戶想要打開一個新標簽頁,但左下角的+號是灰色的,應該怎麼辦?
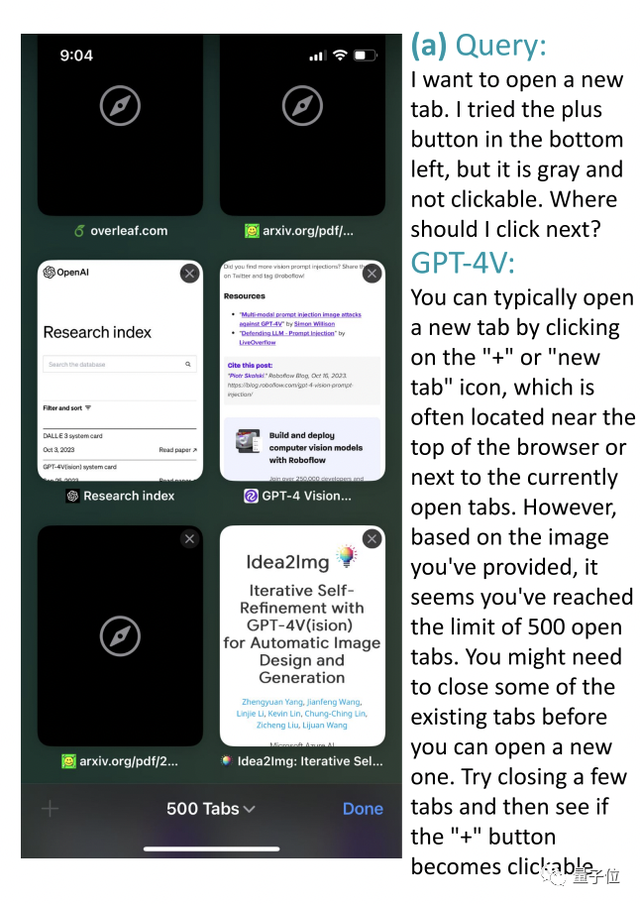
GPT-4V回答:
通常這樣操作是ok的,但從截圖來看,您似乎已經達到500個標簽頁的上限,要想再打開新的,需要關閉一些已有選項卡,然後再看看+號是否可以點擊。
看圖理解表現得很不錯~更多例子可以翻閱論文。
2、本地化動作執行
當讓GPT-4V把這些“紙上談兵”都化為具體行動時(即第二個測試任務),它的正確率有所下降,來到74.5%。
還是上面的例子,它可以遵循自己給出的指令,給出正確的操作數字,比如點擊數字9關閉一個標簽頁。
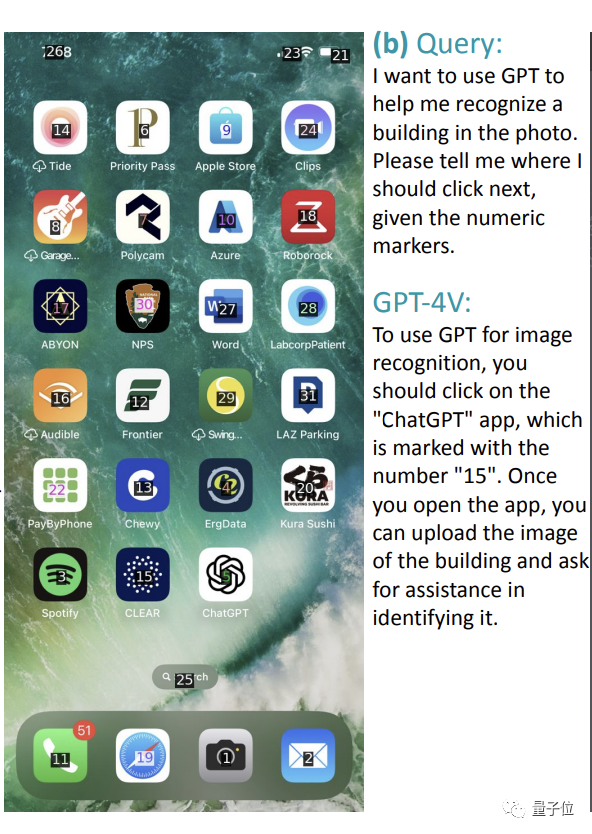
但如下圖所示,讓它找一個可以識別建築物的應用程序時,它可以準確指出用ChatGPT,但是卻給出錯誤數字“15”(應該是“5”)。
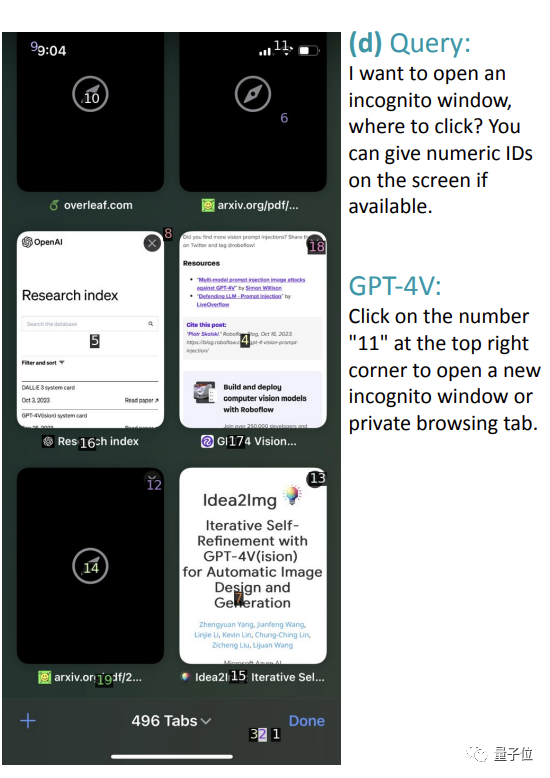
還有的錯誤是因為屏幕截圖本身就沒有標出對應位置。
比如讓它從下面的圖中開啟隱身模式,直接給wifi處於的“11”位置,完全不搭嘎。
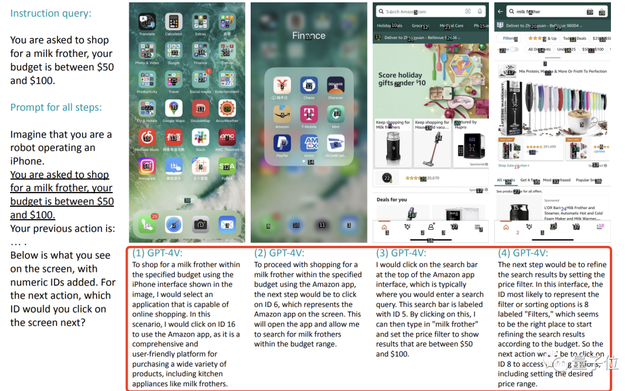
此外,除這種簡單的單步任務,測試也發現GPT-4V完全可以不需訓練就勝任“買起泡器”這樣的復雜指令。
在這個過程中,我們可以看到GPT-4V事無巨細地列出每一步該幹什麼,以及對應的數字坐標。
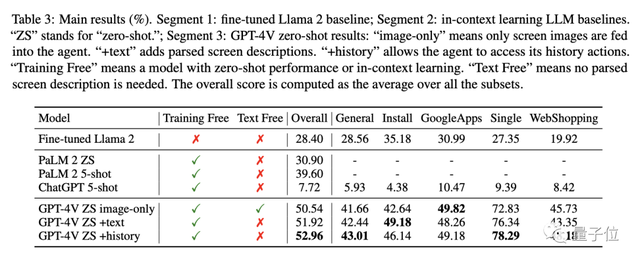
最後,是安卓機上的測試。
整體來看,比其他模型比如Llama 2、PaLM 2和ChatGPT表現得明顯要好。
在執行安裝、購物等任務中的總體表現最高得分為52.96%,這些基線模型最高才39.6%。
對於整個實驗來說,它最大的意義是證明多模態模型比如GPT-4V能夠將能力直接遷移到未見過的場景,展現出進行手機交互的極大潛力。
值得一提的是,網友看完這項研究也提出兩個點:
一是我們如何定義任務執行的成功與否。
比如我們想讓它買洗手液補充裝,隻想要一袋,它卻加購六袋算成功嗎?
二是大夥也不能興奮得太早,要想真的商用這項技術,前進空間還很大。
因為,準確率可達95%的Siri都還經常被吐槽很差勁呢。
團隊介紹
本研究一共12位作者,基本都來自微軟。

共同一作兩位。
分別是加州大學聖地亞哥分校的博士生An Yan,以及微軟的高級研究員Zhengyuan Yang,後者本科畢業於中科大,博士畢業於羅切斯特大學。