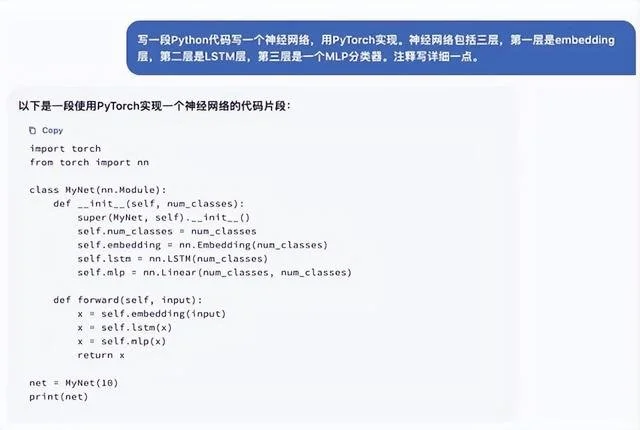
由美國OpenAI公司開發的ChatGPT模型在全球點燃新一輪AI革命,海內外關註度陡增。前不久,復旦大學計算機科學技術學院邱錫鵬團隊發佈類ChatGPT模型MOSS,新聞迅速登上微博熱搜。近日,邱錫鵬團隊接受訪談,詳細介紹人們關註的MOSS。

圖說:MOSS
大傢最興奮的一天,是春節前的臘月二十八。項目主開發者、計算機科學技術學院博士研究生孫天祥,在測試過程中輸入一個中文問題,MOSS卻以英文正確回答,“就像一個不會說但聽得懂中文的人”。當時版本的MOSS還很初級,中文語料占所有訓練數據不到0.1%。
“很神奇,我們沒有教過它機器翻譯。”MOSS顯示出的潛能讓邱錫鵬當晚激動到失眠。他把MOSS比作一個“聰明的小孩”,即便現在還不擅長寫詩、解題或很多具體的事,但已展示出成為通用人工智能(AGI)大框架的潛能,“很多遙不可及的事情,它一點就通。”實際上,邱錫鵬也讓6歲的女兒和MOSS聊天,發現孩子可以愉快地和MOSS對話很長時間。
MOSS受到關註的背後,是科研人員十年如一日的積淀。作為一名人工智能研究專傢,邱錫鵬從讀博期間就開始涉獵機器學習,留校工作後進入自然語言處理研究領域。他和團隊在自然語言處理的基礎模型和基礎算法上形成很多創新的研究成果。邱錫鵬的著作《神經網絡與深度學習》被廣大讀者親切稱為“蒲公英書”,在許多“人工智能必看書單”中榜上有名。去年,他還帶領團隊獲得中國中文信息學會“錢偉長中文信息處理科學技術獎”一等獎。
這些天,邱錫鵬與他的MOSS團隊——8位年輕的復旦學生,繼續緊鑼密鼓地開展內測和迭代工作。新模型預計在3月底優化完成,後期再逐步對社會開放。
目前已參與內測的一些用戶表示,盡管MOSS在參數規模上和ChatGPT相比小一個量級,事實性問題覆蓋不夠全面,經常會“一本正經地胡說八道”,但確實有“ChatGPT那味兒”“基本功能都實現”。邱錫鵬很樂觀,認為在不遠的將來,MOSS這類大型語言模型會成為和搜索引擎一樣常規的存在,為人們生活的方方面面提供助益。
邱錫鵬介紹,ChatGPT的參數量多達1750億個,而MOSS的參數量比其小一個數量級,大約是前者的1/10。“比起事實類的知識儲備,模型的邏輯思維能力更值得大傢關註”,有一種說法,說我們和國外的技術水平差距非常大,想追上的話,要花很長時間。但我們的努力證明,其實不需要那麼久。
新民晚報記者 張炯強 通訊員 殷夢昊 許文嫣
【相關報道】
MOSS究竟是什麼?邱錫鵬答記者問,回應社會關註熱點。

圖說:團隊照片,左六為邱錫鵬
記者:可否簡單介紹一下MOSS?這種“大型對話式語言模型”和我們日常使用的Siri、小度、小愛等聊天機器人有什麼區別?
邱錫鵬:我可以打個比方,這兩者的關系就像智能手機和功能手機。之前的聊天系統還屬於弱人工智能,設計它們就是用來聊天的,就像傳統的功能手機隻能用來打電話;而現在的大型語言模型,像ChatGPT、MOSS,它們能做很多事,聊天隻是功能之一,就像智能手機可以用來打電話,但它的功能遠遠不止於此。
就ChatGPT、MOSS而言,它們具備的是一種通用能力,可以幫助人類完成各種各樣的事情,隻不過以對話形式呈現。它可以完成自然語言處理領域的絕大部分任務,包括機器翻譯、信息抽取、糾錯等。它們還可以在學習使用外部工具後,與外部世界進行交互,進行創作。這些都是現有的聊天機器人所不具備的。應該說,這種對話式大型語言模型向我們展示一條通向“通用人工智能”的嶄新路徑。
記者:團隊2月20日發佈MOSS模型,是剛剛建成嗎?前後花多長時間?
邱錫鵬:事實上,我們在春節前就開發出第一代模型。它顯示出很大的潛能,與之前的聊天系統大不相同,有著不錯的人類意圖理解能力,也有很多湧現能力,比如未經訓練就學會機器翻譯。之後,我們又花一個多月的時間打磨它的工程部署情況,比如提高效率、優化界面等。
MOSS的開發同樣不是一蹴而就,它離不開我們團隊過去的鋪墊工作和長期積累的研究經驗。從2021年起,我們就開始做中文生成式預訓練模型,也開源供別人下載,每月平均有上萬次下載。後面我們又提出“語言模型即服務”的概念,認為基礎語言模型會成為語言服務的基座。因為意識到大型語言模型會成為將來的基座,所以去年開始做大型語言模型方面的訓練。後來又花費半年時間,研究如何使大型語言模型理解人類指令以及具備對話能力。
記者:MOSS如何能夠實現“端到端”走通大語言模型,克服哪些難點?
邱錫鵬:“端到端”是一個學術概念,指的是從零開始,信息收集、數據處理、建立模型,到最終形成一個具有和人類對話能力的大模型,中間所有技術路徑可以走通,這個就叫由起點到終點的“端到端”。因為OpenAI至今沒有公佈開發ChatGPT的技術路線和技術細節,所以我們需要靠有限的公開信息來自己摸索。
這個過程非常難,包含非常多經驗性、直覺性的設計,關鍵要打通兩步:第一是基座,大型語言模型的基座不是簡單的參數足夠大就可以,還需要賦予大型語言模型各種各樣的知識能力、學習能力,還有邏輯推理能力。第二就是要通過一些指令觸發它的對話能力,讓它理解人類意圖,與人類能夠交互對話。
到目前為止,我們還能把控技術路線,但未來可能會面臨更大的困難,因為我們收集非常多和人類交互的指令,要賦予它價值觀和各種各樣的能力,就要請一些專業人士來幫助我們設計,進一步增強MOSS各方面的能力。
記者:MOSS的名字是怎麼來的?
邱錫鵬:在學術圈,大傢非常喜歡用影視形象給自己開發的AI模型命名,也是一個比較常見的做法。比如,Transformer模型、Megatron模型名稱取自《變形金剛》,BERT模型、ERNIE模型化用《芝麻街》中的角色形象。那麼,我們開發出這個具有對話能力的大型語言模型之後,也想找一個國產的、能夠代表中國特色的影視形象來命名。
開發過程中,正逢《流浪地球2》電影熱映,我們的團隊成員都非常喜歡《流浪地球2》,也都是《流浪地球2》的粉絲。影片中的智能量子計算機MOSS給我們留下深刻的印象,所以我們就把模型命名為MOSS,也是向《流浪地球2》這部電影致敬。這幾天也有《流浪地球2》的粉絲們給我們發郵件,希望我們一定要加油,真的能夠做出來。