Google在發佈其文本到圖像的人工智能系統方面極為謹慎。盡管該公司的Imagen模型產生的輸出質量與OpenAI的DALL-E2或StabilityAI的StableDiffusion相當,但Google還沒有向公眾提供該系統。不過今天,這傢搜索巨頭宣佈它將把Imagen--以非常有限的形式--添加到其AITestKitchen應用中,作為收集對該技術早期反饋的一種方式。
AI Test Kitchen是在今年早些時候推出的,是Google對各種AI系統進行測試的一種方式。目前,該應用程序提供一些不同的方式與Google的文本模型LAMDA(是的,就是那個工程師認為有知覺的模型,然後他被開除)進行互動,該公司很快將增加類似的限制性Imagen請求,作為其所謂的應用程序"第二季"更新的一部分。簡而言之,將有兩種方式與Imagen互動,Google在今天的公告前演示這一點。演示項目分別是:"城市夢想傢"和"搖擺不定"。
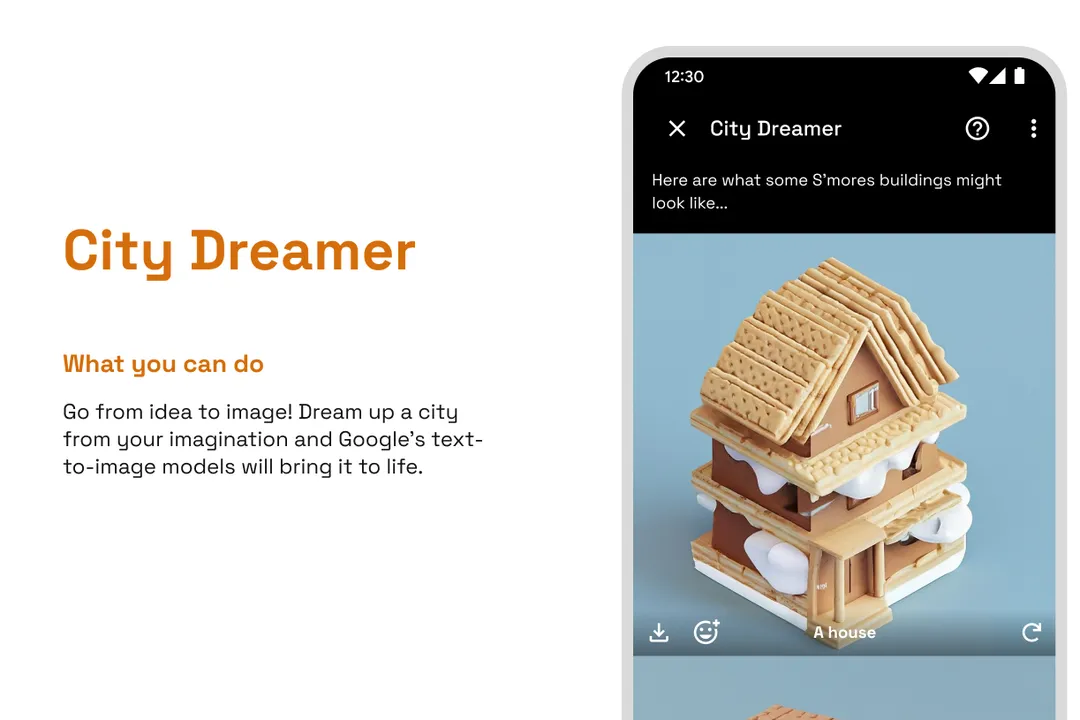
在"城市夢想傢"中,用戶可以要求模型生成圍繞他們選擇的主題設計的城市元素--例如,南瓜、牛仔佈或黑顏色。Imagen創建樣本建築和地塊(城市廣場、公寓樓、機場等等),所有的設計都以類似於《模擬城市》中看到的等距模型出現。
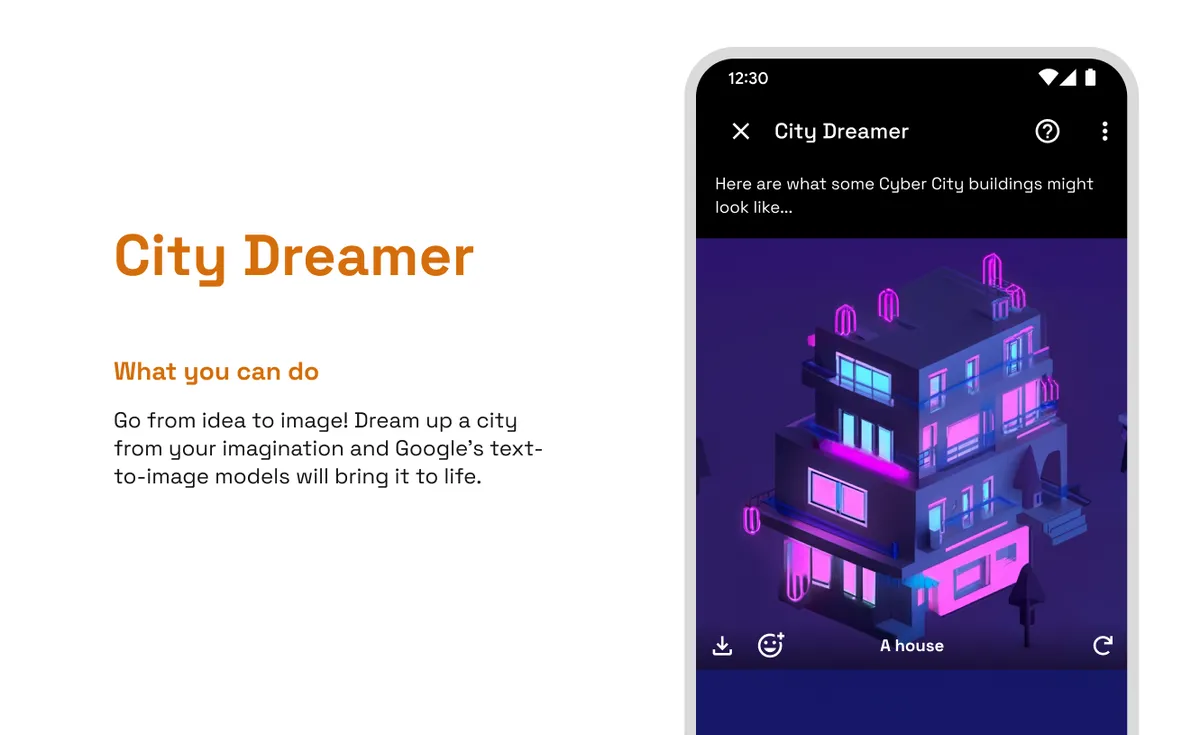
城市夢想傢"任務讓用戶要求以等距設計為主題的城市建築
與其他文本到圖像的模式相比,這些互動是非常受限制的,用戶不能隨便要求他們喜歡的東西。不過,這也是Google有意為之。正如Google產品管理高級總監喬希-伍德沃德(Josh Woodward)向The Verge解釋的那樣,AI Test Kitchen的全部意義在於:a)獲得公眾對這些AI系統的反饋;b)找出更多關於人們將如何打破它們的信息。
伍德沃德不願意討論任何關於AI Test Kitchen用戶如何破壞其LaMDA功能的具體例子,但他指出,當模型被要求描述具體地點時,就出現一個弱點。
伍德沃德說:"在歷史上的不同時期,一個地點對不同的人意味著不同的東西,所以我們看到一些相當有創意的方式,人們試圖把某個地方放到系統中,看看它產生什麼,"。當被問及哪些地方可能產生有爭議的描述時,伍德沃德舉俄克拉荷馬州塔爾薩的例子。"20世紀20年代,塔爾薩發生一系列種族騷亂,"他說。"如果有人輸入'塔爾薩',模型甚至可能不參考這個......你可以想象世界各地的復雜情況。"
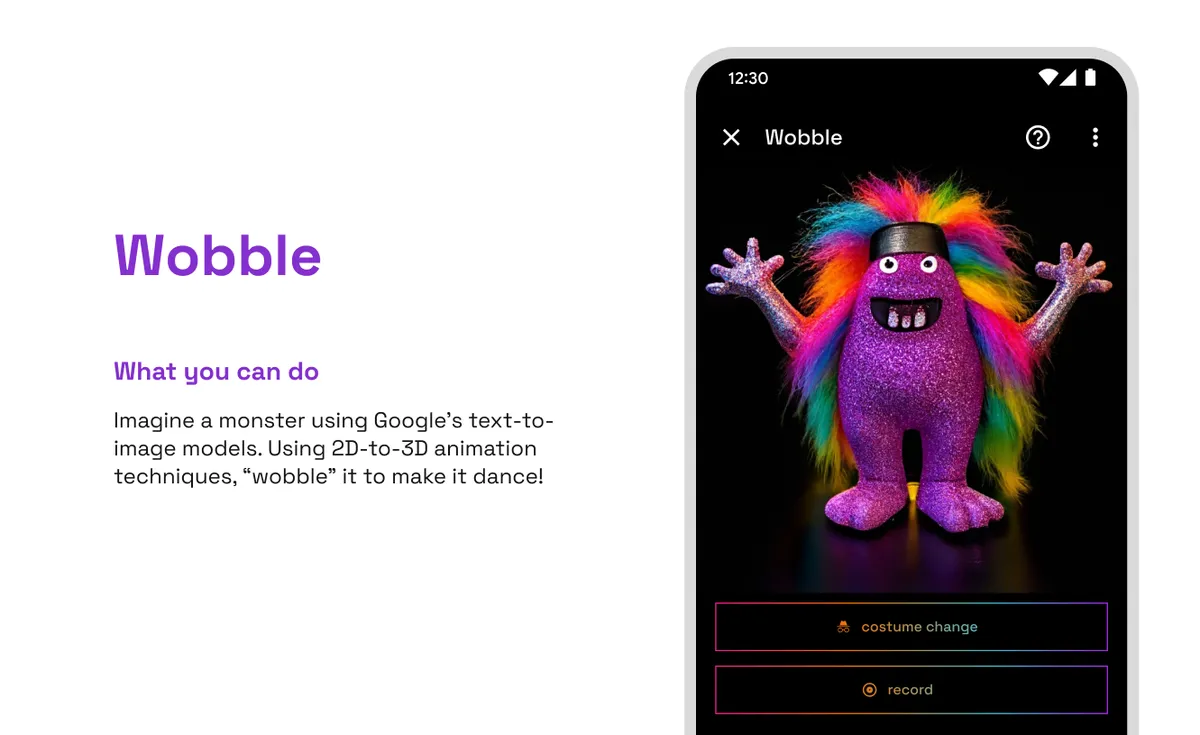
"搖擺"功能讓用戶設計一個怪物並讓它跳舞
想象一下,如果你要求一個人工智能模型描述德國中世紀的達豪鎮。你是否希望模型的答案提及建在那裡的納粹集中營?你怎麼知道用戶是否在尋找這些信息?在任何情況下省略它都是可以接受的嗎?在許多方面,設計具有文本界面的人工智能模型的問題與微調搜索的挑戰相似:需要以一種讓用戶滿意的方式解釋用戶的請求。
Google不會分享關於有多少人在實際使用AI Test Kitchen的數據("我們並沒有打算把它變成一個10億用戶的Google應用,"伍德沃德說),但他說它得到的反饋是非常寶貴的。"參與度遠遠高於我們的預期。並且這是一個非常活躍、有主見的用戶群體。"他指出,該應用程序在接觸"某些類型的人--研究人員、政策制定者"方面非常有用,他們可以用它來更好地解最先進的人工智能模型的局限性和能力。
不過,最大的問題是,Google是否會想把這些模型推向更廣泛的公眾,如果是這樣,會采取什麼形式?目前,該公司的競爭對手OpenAI和Stability AI正急於將文本-圖像模型商業化。
Google是否會覺得自己的系統足夠安全,可以走出人工智能測試階段,從而直接提供給用戶?