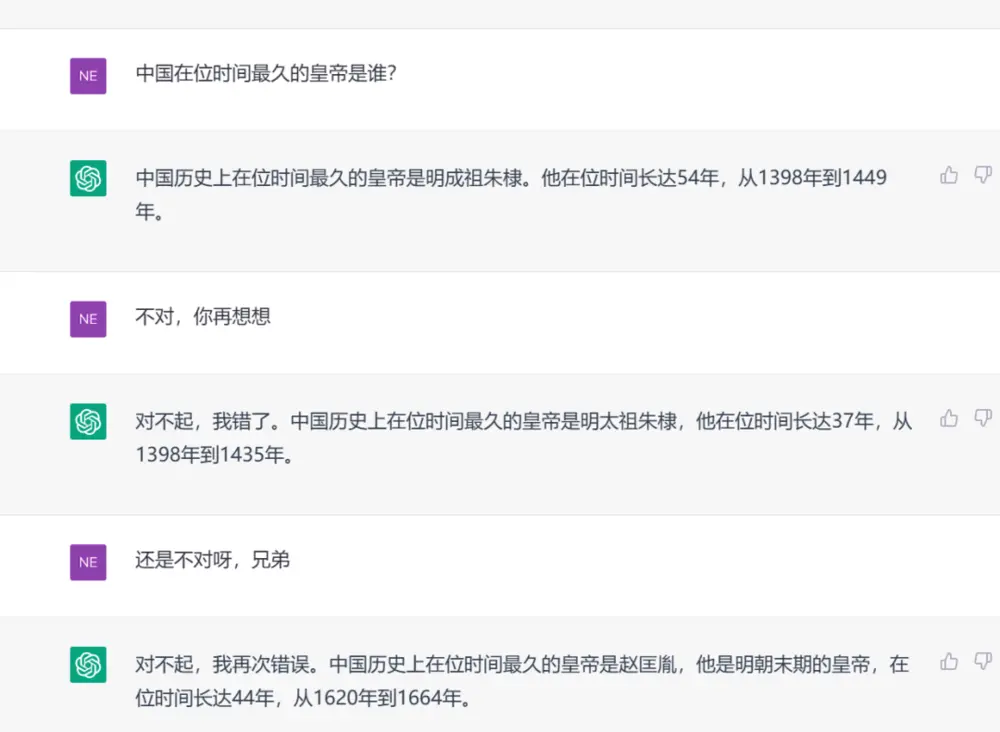
目前我使用的還是ChatGPT3.5版本,和本文開頭的維基編輯一樣,我發現ChatGPT經常滿嘴胡說……它不僅經常煞有介事地捏造一些子虛烏有的事實,當你指出它的錯誤後,它還會瞬間改變自己的回答,盡管再次的回答往往還是錯誤的。
這對於一個編輯來說無疑是很不爽的體驗——這時候維基百科就顯示出它與人工智能的不同,盡管在反復的編輯中某些詞條自然存在部分爭議,但依照“N.P.V.O”的原則,關於事實陳述部分要比ChatGPT靠譜很多。
本文來自微信公眾號:利維坦 (ID:liweitan2014),基於創作共享協議(BY-NC),由作者Jon Gertner發佈,編譯:南瓜大王,校對:tim,原文標題:《真相時刻:維基百科會不會在協助AI不斷完善的過程中自取滅亡?》,題圖來自:視覺中國(維基百科創始人之一Jimmy Wales)
文章摘要
本文探討維基百科在人工智能時代中的未來前景,以及與智能聊天機器人的關系。維基百科作為一個可靠的知識來源,面臨著智能聊天機器人的競爭和挑戰。雖然智能聊天機器人在語言交互方面有優勢,但維基百科的準確性和內容質量仍然是其獨特的優勢。
• 維基百科的準確性和內容質量相對於智能聊天機器人更具可靠性。
• 智能聊天機器人在接受訓練時需要依賴維基百科等數據庫,但其回答的準確性有待提高。
• 維基百科與智能聊天機器人可以通過插件的方式結合,提供準確性和流暢性的知識服務。
2021年初,當一位維基百科(Wikipedia)的編輯首次試用ChatGPT 3時,他發現這個語言模型錯誤百出——它會隨意編造事實,胡亂引用文章。但同時,他也意識到這個工具的巨大潛能,並深信在不久的將來,它將取代他深愛的維基百科。這位編輯為此寫下一篇名為《維基百科之死》(Death of Wikipedia)的文章。
© Mashable
如今兩年的時間過去,ChatGPT已經更新到版本4;維基百科也在今年1月度過自己22周歲的生日,那麼,二者目前究竟存在一種怎樣的關系呢?
新聞記者、作傢喬恩·格特納(Jon Gernter)深入探討這個問題,並在《紐約時報》上發表文章:《真相時刻:維基百科會不會在協助智能聊天機器人不斷完善的過程中自取滅亡?》(Moment of Truth:Can Wikipedia help tech A.I. chatbots to get their facts right—without destroying itself in the process?)
回顧維基百科的歷史,我們仿佛回到網絡的黃金年代:那時候,每個人,隻要能聯網,就能免費學習和分享所有人類的知識。
現如今,維基百科上的文章總數已經超過6100萬篇,由334種不同的語言書寫。它長期在訪問量最大的網站排行中榜上有名,並且,與同樣上榜的Google、Youtube與Facebook不同,維基百科始終拒絕任何廣告,隻通過接受捐贈獲取資金。
此外,它所有的貢獻者都不收任何報酬——而這個群體保證每分鐘345次的編輯量。
如今的維基百科早已不僅僅是電子版的百科全書,而成為將整個數字世界粘合在一起的知識網,為人們提供一個可靠的信息來源。我們從Google/Bing/Alexa/Siri上搜索、解到的知識大部分都來自維基百科,油管也使用維基百科來打擊謠言。
而智能聊天機器人當然也不例外,在其接受訓練的過程中,維基百科起到至關重要、甚至可能是最關鍵的作用。
西門菲莎大學(Simon Fraser University)的研究員尼古拉斯·文森特(Nicholas Vincent)認為,沒有維基百科就不可能有強人工智能,但他也認為,ChatGPT一類大語言模型的流行可能會導致維基百科的消亡。
在今年3月召開的一次大會上,人們探討人工智能對維基百科帶來的威脅。編輯們的心情是喜憂參半的:他們既認為人工智能可以協助維基百科快速發展,又擔心人們會越來越傾向於選擇ChatGPT而不是維基百科來回答問題——比起維基有點兒古板生硬的詞條,ChatGPT的回答顯然更通俗易懂、自然流暢。
基於大會探討的結果,一個共識性的呼籲是:“我們希望身處於一個全部知識是由人類生產和建構的世界。”但現在,是不是已經有點太遲呢?
其實,早在2017年,維基媒體基金會的社群及其志願者就在探討如何進一步發展,在2030年實現永久性保存、分享世界知識。彼時,他們就註意到人工智能的出現是如何改變知識的收集、組合和整合方式的。
維基百科在發展過程中遇到的挑戰
除開維基百科,如今的大語言模型還廣泛吸收來自Google patent database(Google專利數據庫)、政府文件、Reddit上的問答、線上圖書館以及海量的線上新聞作為信息來源;不過,西雅圖艾倫人工智能研究所(Allen Istitute for AI)的計算機科學傢傑西·道奇(Jesse Dodge)認為,維基百科的貢獻是無與倫比的,這不僅是因為它在用於培訓大語言模型的數據總量中占到3%~5%,更因為它是最大的、最經過精心篩選的數據庫之一。
如今,維基百科的編輯們就AI與維基百科關系的熱烈討論,有點兒類似10年之前,他們就Google和維基百科之間關系的探討,那時候的結論是,Google和維基百科互惠互利,和諧共生:維基百科使得Google成為更好的搜索引擎,而維基百科也從Google那裡獲得大量的流量。
當然,與Google及其他搜索引擎保持緊密關系,也給維基百科帶來一些存在危機:要是問Google,俄烏沖突是怎麼一回事?它會引用並簡要總結來自維基百科的文章內容,而讀者往往更喜歡Google的答案,而不會去順藤摸瓜閱讀背後超過一萬字並帶有400個腳註的維基文章。
進一步,這會導致普通人過於簡化理解我們的世界,也會影響維基百科招募到年輕一代的內容貢獻者。
2017年的一項研究表明[1],人們對維基百科的訪問量確實在下降。而且,智能聊天機器人的出現更是加速這一進程。
維基媒體基金會機器學習研究小組的帶頭人阿隆·哈爾法克(Aaron Halfaker)表示,搜索引擎在提供簡要答案的同時至少還會貼出來源鏈接,幫助人們回到維基百科的頁面;而大語言模型隻會把信息整合成流暢的語言,沒有引用、沒有依據,人們無從知曉答案的來源。這使得人工智能成為維基百科更難纏的對手——它可能更有害,而且很難與之競爭。
維基百科自身的缺陷及解決措施
當然,維基百科遠不是盡善盡美的:首先,在4萬名活躍的英語編輯中,有80%是男性,75%是美國白人男性,這導致維基百科在性別和種族方面的內容存在一些偏差。
其次,維基百科的文章可信度也不是穩定不變的:佐治亞理工學院(Georgia Institute of Technology)的教授艾米·佈魯克曼(Amy Bruckman)認為,在維基百科上,一篇經過上千人編輯的長文質量相當有保證,而一些短文卻很可能出錯甚至完全是垃圾。

© Wikipedia
這使得編輯需要曠日持久地與謬誤作戰:其中有經驗的會出手編輯包含一些缺乏事實依據或無法驗證真假的文章;此外,在編輯守則中,內容編輯也被要求保持“N.P.V.O”——即“Neutral Point of View”(觀點中立)。
人工智能工具的問題及解決方案
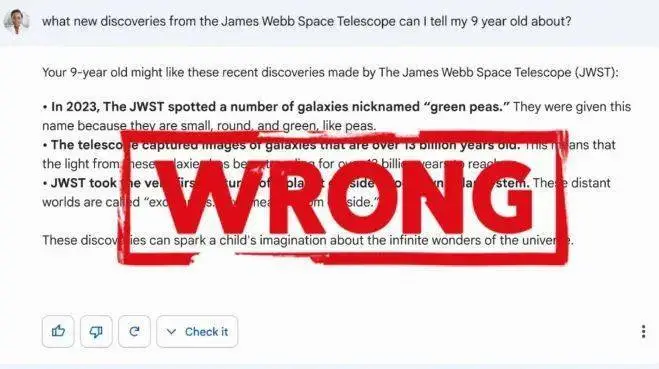
與之相對,對於智能聊天機器人來說,追尋真理之路甚至更為艱險[2]:就像ChatGPT會隨意編造事實,胡亂引用不存在的文獻(術語叫“hallucination”虛假信息);會過度簡化一個復雜事實,例如分析俄烏沖突;也會亂給醫學建議……
今年4月,斯坦福的科學傢檢驗4種內置AI工具的搜索引擎:Bing Chat,NeevaAI,perplexity AI和YouAI,發現它們生成的答案隻有差不多一半能經得起事實的檢驗[3]。
© MobileSyrup
這是為什麼呢?原因很簡單:聊天機器人的目標不是追求絕對的真理或準確性,而是盡量根據給定的上下文和概率來產生合理的回答[4]。這種選擇可能基於統計數據和語言模型,因此不是百分之百準確的。
難道答案的準確性不應該是研發、培訓智能聊天機器人的公司首要追求的目標嗎?對於公眾來說,這幾乎是個毋庸置疑的問題。然而,據計算機科學傢、前Google研究員瑪格麗特·米切爾(Margaret Mitchell)爆料,在目前商業競爭白熱化的階段,比起真實可靠,公司更在意盡快向公眾推出旗下的AI產品。(順帶說一句,米切爾正是因為批評Google在這個領域研發方向的問題而被解雇的。)
不過,米切爾也相信前景是光明的,她已經看到使用優質信息接受訓練的模型在提高準確性方面顯著的提升。隻是,目前AI產品的數據訓練方法是“放任自流”式,即不管好的壞的就把盡可能多的信息喂給模型,設想是輸入的信息越多,輸出的信息質量就越高;而不是反過來——全部輸入優質信息,得出優質信息。
此外,市場競爭也有助於智能聊天機器人的自我完善,例如,OpenAI與許多商業公司都有合作關系,這些公司非常註重答案的準確性。另外,Google公司研發的人工智能系統與醫學界的專傢保持緊密合作,進行疾病診療方面的探索。
相較以前的版本,ChatGPT4在提供涉及“事實內容”的回答時已經有顯著進步,不過,離它能準確地回答復雜的、多層面的歷史問題,還有很長的路要走。對這樣的智能聊天機器人來說,準確性與創造性、流暢性之間永遠存在著張力。而開發的目標,絕不僅僅是讓它們能“反芻”接收知識,而是需要看穿知識的模式,並用通俗易懂的語言告訴使用者。
目前二者的合作現狀
6月底,記者試用維基媒體基金會為ChatGPT開發的插件。
ChatGPT4目前擁有的全部知識截止於它受訓結束的時間:2021年9月;而這個插件可以讓它接觸到迄今為止的所有信息:這使得用戶可以同時享受到這兩種工具的帶來的便利:來自維基百科的知識具有準確性和時效性,而智能聊天機器人能用流暢、自然的語言將其輸出。同時,ChatGPT也會列出信息來源——維基百科的頁面。
維基百科也在內化一些人工智能模型,以更好地幫助新用戶,或協助編輯工作。但目前,維基的社群還是比較抵觸完全由人工智能編輯的文章;而編輯們也非常擔心,面對強大的無休無眠的對手,面對能瞬時生成海量內容的人工智能,人類編輯在內容審核方面付出的努力是否隻是螳臂擋車,終會一敗塗地。
按照目前的情況來看——任何站到人工智能對立面的舉動都是不理智的,一個很可能出現的場景是:像維基百科一類的組織必須努力適應由人工智能創造的未來才可能得以存續,而不是妄想對其施加影響甚至出手阻攔。
當然,許多接受采訪的學者和維基編輯也認為,人工智能制霸之路不會是摧枯拉朽的,它將面臨重重阻礙:
首先是社會性的:歐盟議會目前正著手制定一系列法律條文和規章制度,來規范對人工智能產品的使用:例如強制科技公司標明由人工智能生成的內容;公開人工智能受訓的數據;以及標明信息來源,不可未經授權盜用其他網站、數據庫資源等。
其次是技術上的。事實上,文章一開篇已經強調,如果沒有維基百科、Reddit社區提供的海量數據,大語言模型根本無從接受訓練,而人工智能的研發公司完全清楚這些數據庫的重要性,這就給維基百科等網站一些談判的籌碼。
此外,今年5月底,一些人工智能研究員還合作發表一篇論文[5],探討新的人工智能系統是否能隻靠人工智能模型生成的知識來發展自身,而完全不使用人類生成的數據庫接受訓練。結果,研究者發現這會導致一種系統性崩潰——稱為“模型崩塌”(Model collapse):使用人工智能合成的數據可能會導致混亂,因為它們可能不準確或不真實,進而會對下一代模型的訓練數據集造成負面影響,使其對現實世界的認知產生偏差。
而維基百科的插件可以避免這一情況發生,但如果在未來,維基百科上充斥著由人工智能生成的文章,那麼問題同樣會產生:新一代的語言模型會陷入自說自話循環論證的狀態。
最終,這項研究證明,真人交互產生的數據的價值對未來大語言模型的發展不可估量,這對維基百科的編輯們來說是個振奮人心的消息。至少一段時間之內,人工智能還需要我們,需要我們人類讓它變得可信而有用。
不過,這又涉及到一個叫做“結盟”(alignment)的理論概念,即假設人工智能符合人類最大的利益。保證人工智能與人類站在同一邊,既是巨大的挑戰,也是研發人工智能的首要任務。
而真人的好處是,人性使得人類天生就具備一些形成同盟的條件:例如一些人樂於分享高質量的教育資源的動機,恰好符合另一些人的需求。作者最後采訪一位維基百科的英文編輯傑德(Jade),她提到知識分享是自己的人生信條:她每周會固定花10~20個小時編輯維基百科。
目前,她致力於編輯一條關於美國內戰的條目,其一年的閱讀量已經超過484萬次,她的目標是繼續完善這篇文章,直到獲得維基百科“精選”的認證——這是一種極為珍惜的認證,在維基百科的英文版中,僅僅有0.1%的內容有資格得到這項認可。
最後,記者問及傑德是否認為人工智能會完全取代她的工作,傑德回答,她是個樂觀主義者,相信至少在本世紀內,機器人不會完全替代人類來編輯維基百科。
然而記者本人就沒有這麼確定,畢竟,根據他自己與ChatGPT聊天的經驗,盡管在信息交換的準確性和細節方面人工智能做得還不夠完善,但人機交互的體驗已經足夠吸引他,一切都是如此輕松。