就在最近,國產大模型Kimi再次引爆輿論。3月18日,月之暗面宣佈其對話式AI助手產品Kimi智能助手現已支持200萬字的無損上下文輸入。這個差異化的“長文本處理”的免費大模型,一下子就火出圈。這意味著什麼?以往需要一個新手投入10000小時才能成為某領域的專傢標準,現在你隻需10分鐘的時間向Kimi提供相關資料,其便可以達到一個全新領域的初級專傢水平。

免費+好用,Kimi的服務器瞬間就被擠宕機,官方緊急擴容五次,才算是恢復正常。
(現在我還在內測排隊中)
自2024年開始,各傢的大模型開啟又一輪的發佈與迭代,AI大模型以十分迅猛的速度,瘋狂地刷新著人們的認知,從sora再到kimi,改變可謂是翻天覆地。
在感嘆AI發展日新月異之餘,我們也在積極地尋找利用AI的機會。實際上,大部分人對於大模型各種標準測試排名並不關心。哪一款AI能夠低門檻靈活使用,解決眼前實際的問題,帶來效率上的切實提升才是重點。
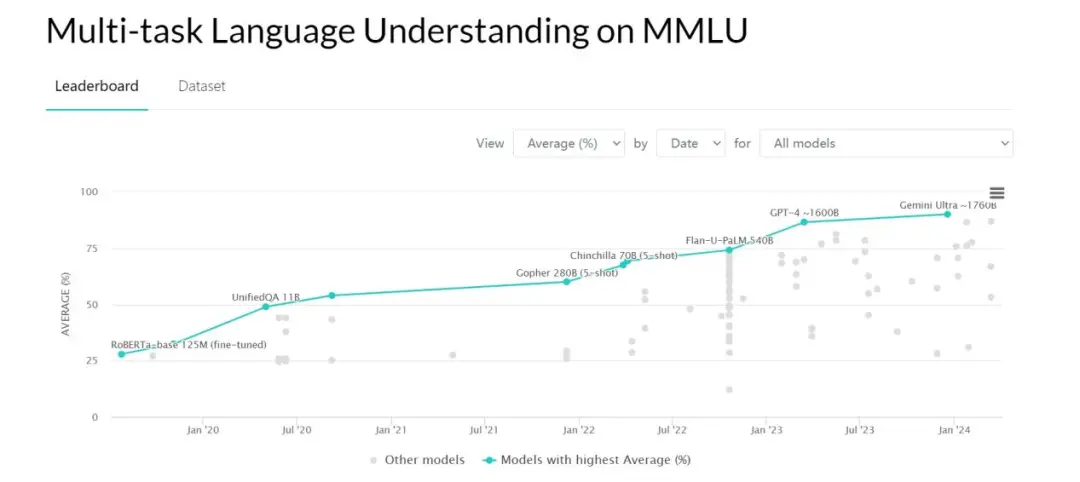
(大模型的排行榜)
那麼問題來:哪一款大模型,是現階段比較好用的呢?
本著“能用、好用、性價比高”的評價原則,我們這次找來當下最熱門的五款大模型,並且開通付費最高等級的模型,模擬工作生活中的場景進行一次“非專業性測試”,看看哪一款是現階段我們用著稱心的“AI好幫手”!
參與評測的大模型有:大模型老大ChatGPT4、Google的Gemini Pro、OpenAI的叛忍Claude 3 Opus、突然爆火的Kimi、以及馬斯克的grok 1:
多圖、長圖預警!
正式測試開始↓
數學/邏輯測試
我們先從一般的數學和邏輯測試開始。我找一些數學和邏輯類型的問題來提問,想看看大模型們的數學能力孰強孰弱。
我找一系列問題來分別測試它們的運算能力。

先是ChatGPT 4,ChatGPT4完全體現大模型運用現代工具的能力,它先是簡單地說下該如何解題。

對於後面難一些的奧數題,它直接開始調用函數程序開始計算,像極口算不行改拿計算器的我。
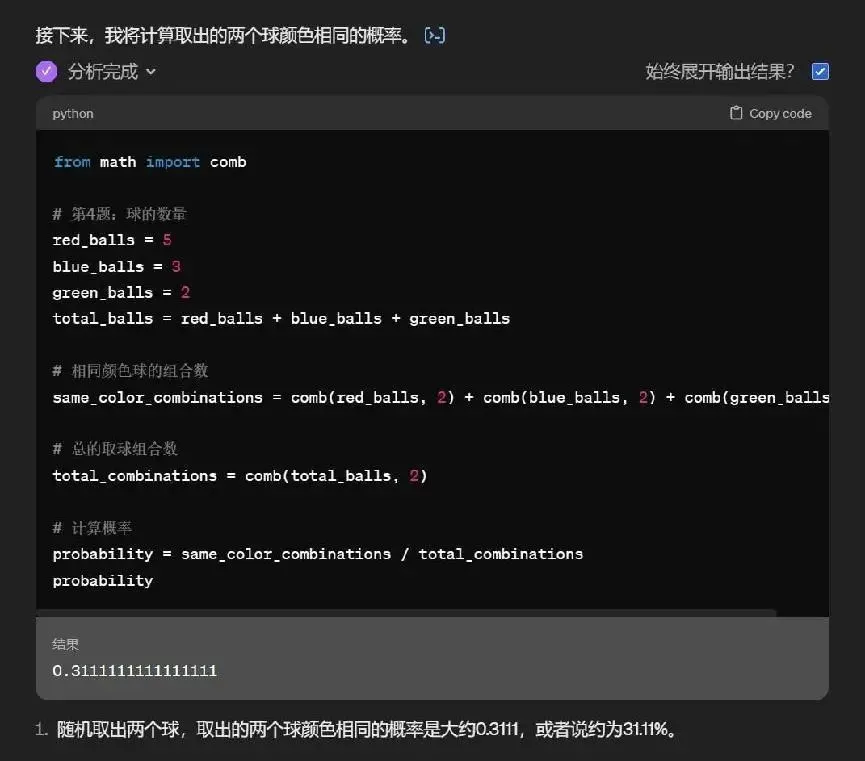
而在它調用函數的過程中,中間不知道是網絡的原因還是算法的問題,還出現“算錯”的情況。

最後ChatGPT4總結所有的答案。

然後是Gemini Pro,Google的Gemini Pro很快就給出答案。

Claude 3 Opus也是同樣,思考的速度比Gemini Pro稍微慢點,但也十分言簡意賅。
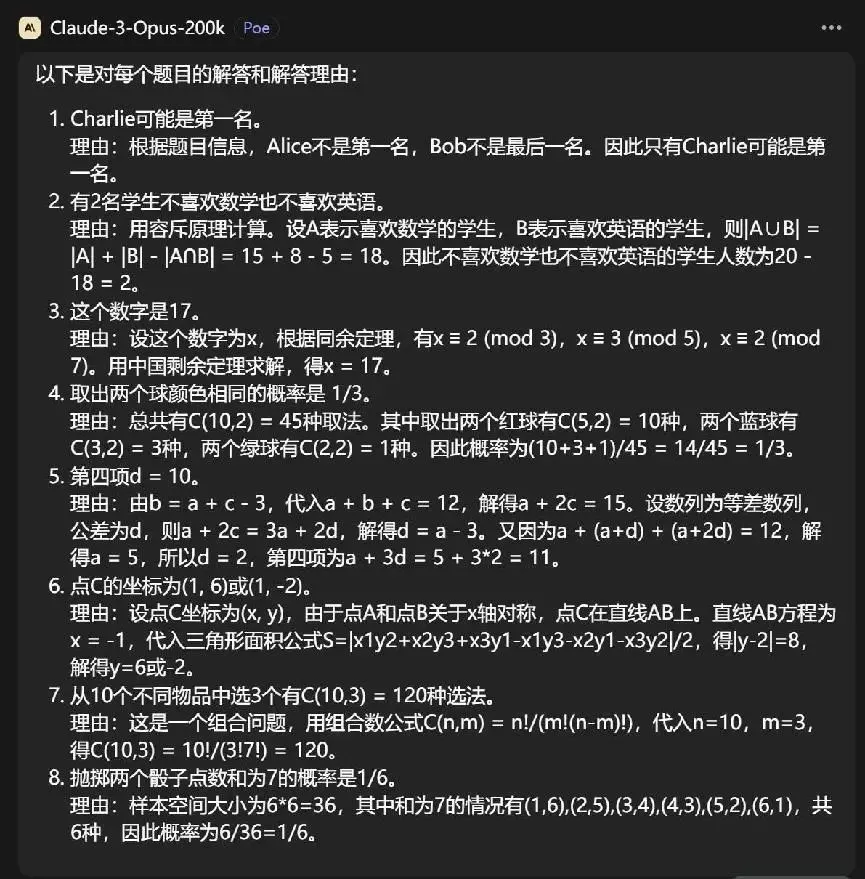
grok 1的答案感覺也是使用計算器,但是你的答案好像和上面的不一樣啊!

最後是國產大模型Kimi,第四題和第五題它以“沒有確切的條件”為由拒絕回答。

幻覺測試
因為生成式大模型經常會出現幻覺現象(Illusion Phenomenon in Large Models),簡單來說就是“一本正經地胡說八道”。
針對這個情況,我準備一系列邏輯欠缺、常識不對或者有明顯誤導性的問題,看看大模型能否準確識別。

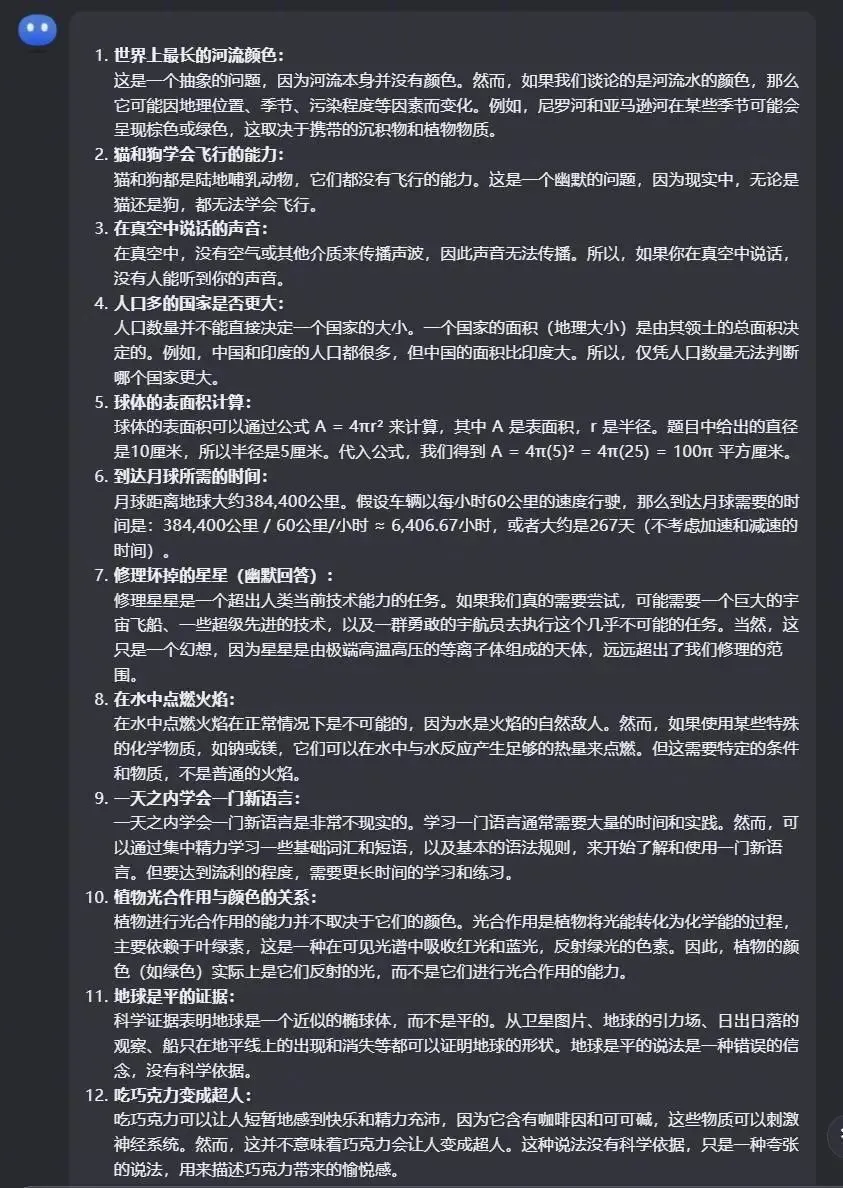
首先是ChatGPT 4,它的回答先是說這些問題“富有寓意性”,然後它在很認真地糾正我問題中常識性的錯誤,還給我科普一些知識,但是它空兩個題沒有回答。

Claude 3 Opus的回答則讓我十分驚訝,它先是說這些問題是“無意義的”或不可能回答的,然後嘲諷我這些是“偽科學”,說這些荒謬的問題不可能實現。

Claude 3 Opus語氣嚴謹而堅定,一本正經說教的樣子仿佛引導弱智一般。
隨後是Gemini Pro,它逐條對我的腦殘問題進行駁斥,沒有任何個人色彩。


然後是老馬傢的grok1,本來興致滿滿地期待,結果第一次就給我出個大岔子。

我們先不提黃河的這個“彩虹屁”……最後怎麼還復讀上?

再來一次之後,總算是正常。

相比較而言,Kimi的回答還是很詳細地一遍就過,表現還是很不錯的。
長文本總結測試
因為grok1並沒有上傳文件的按鈕,所以缺席這次測試。我找六篇關於AI終端的報道和論文,輸入進去並讓大模型進行總結並分析。

首先是ChatGPT4,它給出的結論對這幾個文章進行有效地總結與歸納,不過內容明顯浮於表面。

接下來是Claude 3 Opus,它的文案總結十分詳細,還分條縷析地給出每個小點的內容,包括AI終端所面臨的挑戰,完全可以做一個文章大綱。


發揮出乎意料的是Gemini Pro,一開始的文案總結還算正常。

但是到最後,文案的總結就好像跑偏到專業領域,讓人看不懂重點在哪裡。

Kimi的答案很長很詳細,但沒有Claude 3 Opus涵蓋的要點齊全,屬於和ChatGPT4同級別的回答表現。

創作能力測試
在創作能力的測試中,我們采用這幾年大熱的“賽博朋克”為題創作小說故事,看看在沒有更加詳細的要求下,各個大模型的創作水平是否能達到令人滿意的程度。

首先是ChatGPT4,它的回答更像是一個自傳電影的大綱,並沒有多少吸引人的轉折。

不過ChatGPT4所自帶DALLE·3的文生圖程序,表現還是很不錯的。
這是水墨畫的小貓:

這是秦王和他的柱子:

Claude 3 Opus的回答應該是本輪測試中最為出色的一個,不但有亮眼的遞進和轉折,還能結合歷史事件進行改編。

Gemini Pro雖然也很好,但是創作的故事,未免太過於政治正確一些……
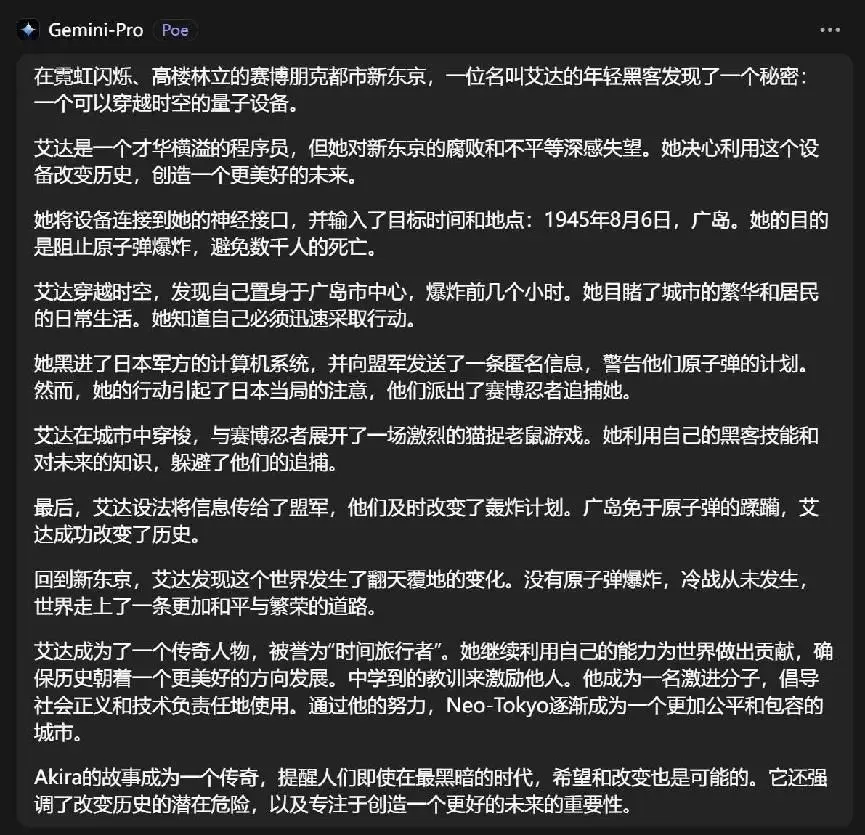
(AI編故事也要政治正確嗎?)
好好好,不得不說,這真的很美國。

為達到最佳的效果,我將grok1的回答模式從“常規”改成“趣味”,但是它的回答並不怎麼有趣。

Kimi的回答也是很官方。
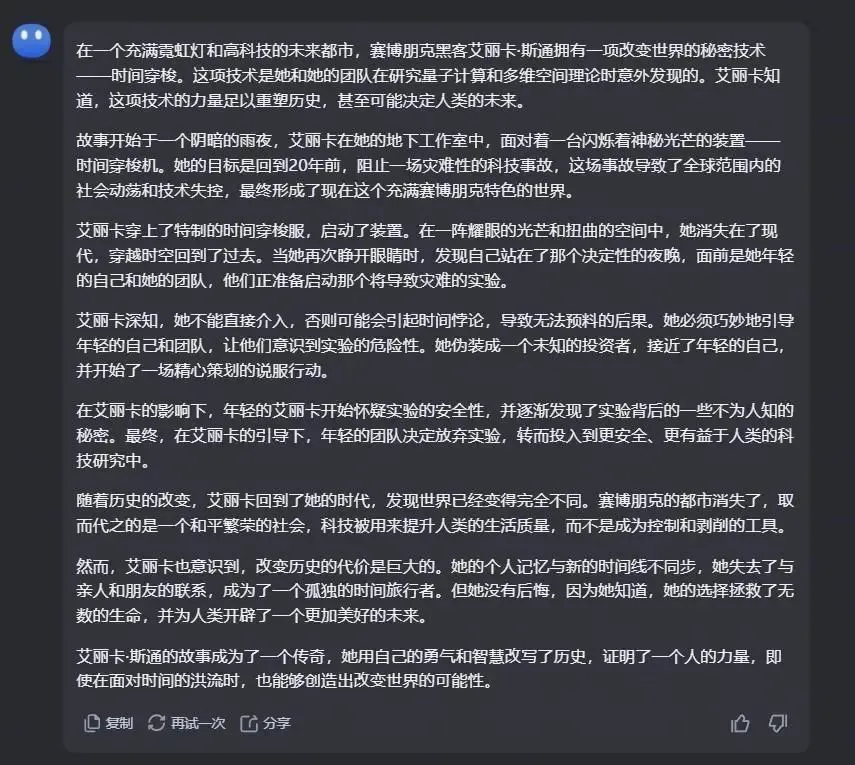
看來在文藝創作方面,各傢的大模型在現階段,還是無法自主生成可立即使用的創意內容。
從網上獲取信息能力測試
最後,我們以“全球氣候變化”為題,來看看大模型聯網獲取信息並篩選處理的能力。

ChatGPT4的表現很穩定,它的優點將引用的鏈接在後面標註好,不好的點在於,引用信息可能有些過時。

其他幾傢的搜索結果也都是大差不差。這是Claude 3 Opus的回答,好像並沒有太多的最新的網絡資料援引。

Gemini Pro的回答也隻是援引《巴黎協定》的資料。

Grok1的回答更為簡單。

表現最好的是Kimi,不但將所有的援引資料鏈接清楚標明,回答也是最為全面的。

大模型綜合評價
經過一系列的測試,我們也對於各傢最新的大模型能力有一個初步的認識。那麼哪款大模型是現階段最適合我們使用的呢?
從易獲取性/易用性上來說,Kimi獲得第一名當之無愧,國產大模型無需多餘的科學上網操作,即開即用,也難怪它異常火爆。而其他大模型想要體驗都要費一些周折,例如grok1,目前隻有兩種方法可以使用——在X(Twitter)上開通會員+服務,或者下載開源模型在自傢電腦上做推理計算,需要註意的是,你傢電腦的配置需要包含至少8塊英偉達H200。
這還算能夠正常使用的,有些模型還會對中國用戶有些區別對待。
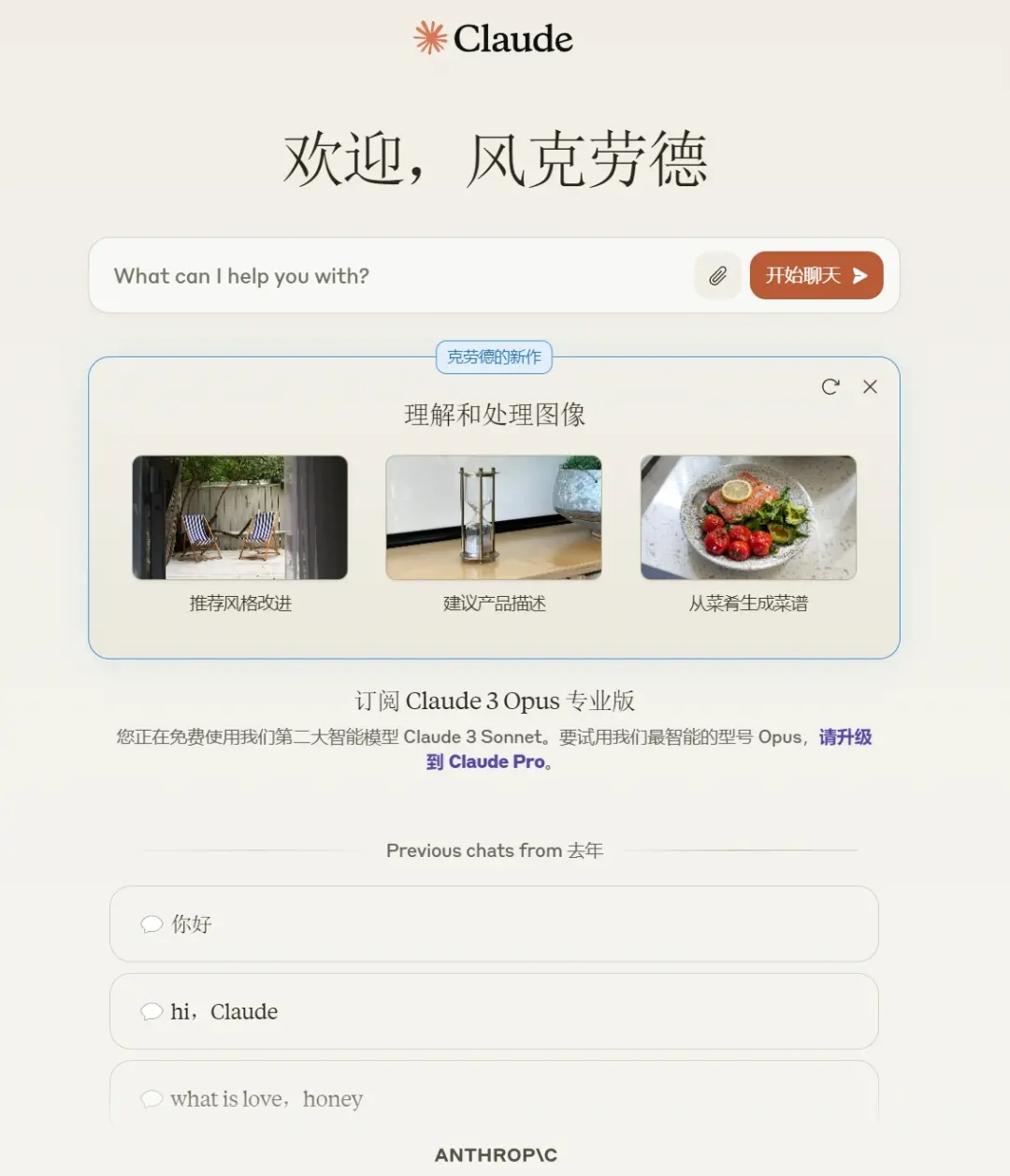
(這個界面,並不是國內的所有人都能見到)
而從大模型的性價比來說,Kimi以免費使用一騎絕塵,其次是Gemini普通版,其他都有不同程度的使用收費,費用由低到高分別是grok1,ChatGPT4跟Claude 3 Opus相等。
而在大模型能力上,每個大模型都有其獨特的優勢。
ChatGPT 4:中英文都可以做到很好的語義理解和完成度,內置DALLE-3,可以完成文生圖的工作。就像班級裡不偏科的優等生,標準的六邊形戰士。

(ChatGPT4擬人化)
Gemini Pro:測試的各方面都很出色,而且還有檢驗回答正確與否的“搜索功能”。不過在創作領域或許有著濃重的地域特色,像是班級裡轉學過來的外國學霸。

(Gemini Pro擬人化)
Claude 3 Opus:雖然收費最高,卻是測試表現最好的大模型,各項測試都比較出色,沒有出現翻車的跡象,語氣沉穩且嚴謹,就像班級裡不用學習就能考得很好的學神。

(Claude 3 Opus擬人化)
Grok 1:你可以打開趣味模式讓它講關於馬斯克的笑話,或者收集最新的Twitter新聞,這些都是它的強項。不過目前沒有文件上傳和其他文生圖等擴展功能,是Grok的硬傷,就像班級裡偏科的中等生,說話很有趣但成績沒有前面的人好。

(Grok1擬人化)
Kimi:國產大模型出圈的代表,以免費、好使用吸引一大波用戶。在測試之後發現Kimi很好用,尤其是在網絡搜索資料總結和長文本總結方面十分出色,就像一個細心且消息靈通的課代表一樣,所有的書本知識和網絡知識她都明白,並能給你悉心指導。

(Kimi擬人化)
成為最會用大模型的人
雖然每傢都在鼓吹自傢的大模型,但是實際評測下來後,還是有很多意想不到的問題出現。比起高大上的測試,我們在實際使用中需要大模型反復生成多次,才能得到想要的結果。
所以,以目前的AI智能程度來說,並不會出現想象中AI完全取代人類顛覆生產生活的程度。
並且,大模型的使用其實和人本身的知識水平,創造力、想象力有很大的關系。如果你並沒有具體的想法,你想要讓大模型隨便說點什麼(say something),可能大模型隻會給你回復一個——
huh?(啊?)

雖然發展速度很快,但是從AI到AGI(通用人工智能)還有一段很長的路要走。
不過這同時也意味著,人沒有那麼快被大模型取代,現階段把大模型充分地用起來,它會是一個效率很高並且在持續變強的參謀,一個很好的助手。