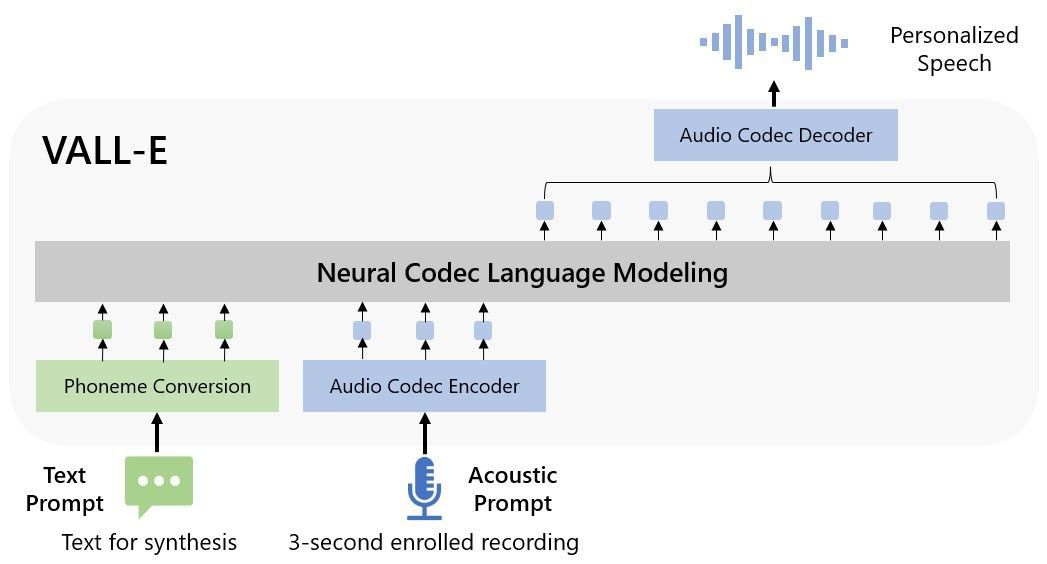
自從第一個文本到語音(TTS)模型發佈以來,研究人員一直在尋找讓計算機系統產生語音的方法,微軟的最新模型VALL-E是在這方面的一個重要進步。VALL-E是一個基於轉換器的TTS模型,隻需聽到三秒鐘的聲音樣本就能生成任何聲音的語音。這比以前的模型有很大的改進,以前的模型需要更長的訓練時間才能生成新的聲音。
對於計算機行業來說,VALL-E是一項驚人的技術壯舉,有可能改變我們與數字媒體互動的方式。語音的音調、魅力和風格都在生成的語音中保持不變,這是在使TTS系統聽起來更自然方面邁出的重要一步。
微軟會不會基於這項技術有更多運用目前還不清楚,然而,微軟已經發佈該模型的幾個實例,很明顯,這是TTS技術的一個重大進步。
您可以在這裡收聽范例:
https://mpost.io/vall-e-microsofts-new-zero-shot-text-to-speech-model-can-duplicate-everyones-voice-in-three-seconds/