OpenAI公佈一項功能的早期測試結果,該功能可用令人信服的人聲朗讀文字。這彰顯人工智能的一個新領域,並引發關於深度偽造的擔憂。該公司分享名為“語音引擎”(VoiceEngine)的文本轉語音模型小規模試用的早期演示和用例,據發言人介紹,目前約有10傢開發商可使用該模型。OpenAI在3月早些時候向記者介紹這一功能,但決定暫不大規模發佈。
OpenAI的發言人說該公司在收到政策制定者、行業專傢、教育工作者和創意人士等利益相關方的反饋後決定縮減發佈規模。據早前的新聞發佈會介紹,該公司原本計劃通過申請流程向多達100傢開發商發佈該工具。
其他AI技術已經在某些情境下被用來偽造聲音。今年1月,一通自稱喬·拜登(Joe Biden)總統打來的以假亂真的電話呼籲新罕佈什爾州居民不要在初選中投票,這一事件在全球關鍵選舉前加劇對AI的恐懼。
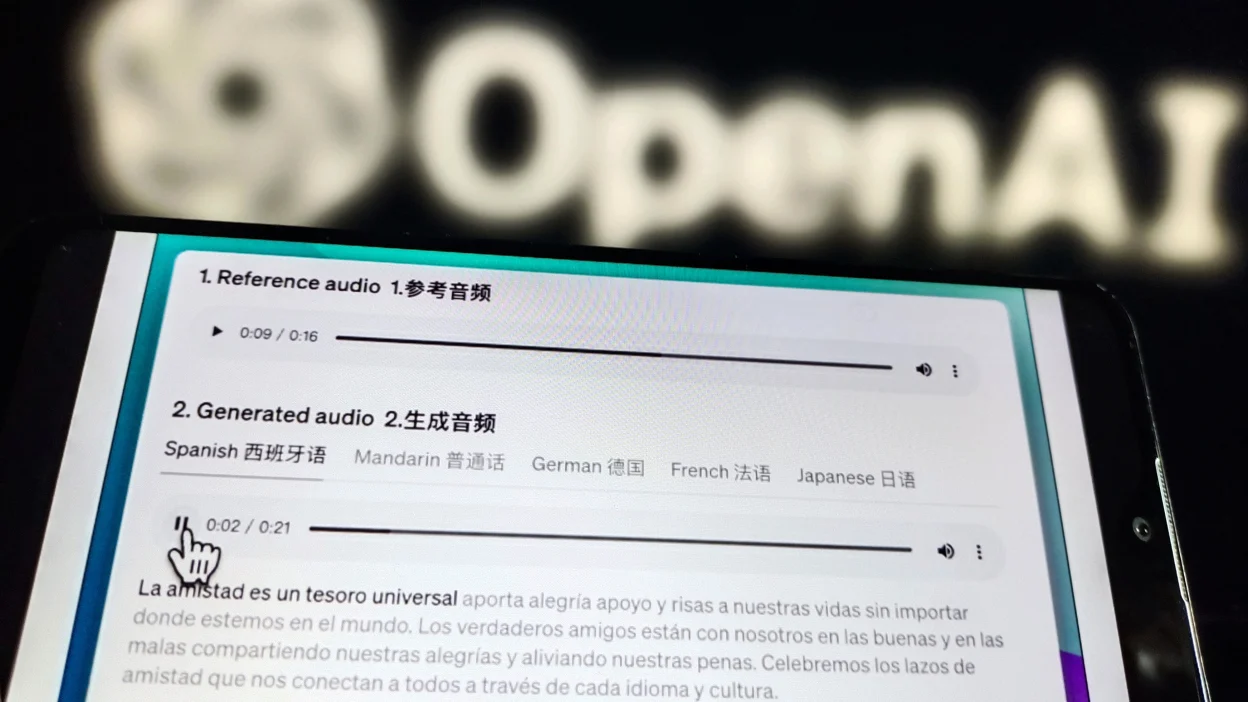
與OpenAI過去生成音頻的功能不同,語音引擎可以創建聽起來像具體個人的聲音,並完整呈現特有的語調和語氣。該軟件隻需要一段15秒的錄音,即可重現一個人的聲音。
“隻要音頻設置得當,基本就能得出人類水準的聲音。”OpenAI產品負責人傑夫·哈裡斯(Jeff Harris)說,“這種技術質量非常不起。”但哈裡斯也表示,“準確模仿人類語音的能力顯然存在很多安全上的不確定性。”
非營利性醫療系統Lifespan旗下的Norman Prince Neurosciences Institute是OpenAI目前的開發合作夥伴之一,該機構正在利用此項技術幫助患者恢復聲音。例如,據OpenAI的博客文章,該工具被用於恢復一位因腦瘤失去清晰說話能力的年輕患者的聲音,方法是復制她此前為一個學校項目錄制的發言。
OpenAI的自定義語音模型還可將生成的音頻翻譯成不同語言。這對於音頻行業公司非常有用,比如Spotify Technology SA。Spotify已經在自己的試點計劃中利用該技術來翻譯萊克斯·弗裡德曼(Lex Fridman)等熱門主持人的播客節目。OpenAI還宣傳該技術的其他有益應用,例如為兒童教育內容創建更多樣化的聲音。
在測試計劃中,OpenAI要求合作夥伴同意其使用政策,即在使用原始聲音前征得聲音主人的同意,並告知聽眾他們聽到的是AI生成的聲音。該公司還加入聽不見的音頻水印,以判斷哪些音頻由其工具創建。
OpenAI表示在決定是否大范圍發佈該功能前,正在征求外部專傢的反饋。該公司在博文中表示:“讓全球人民解這項技術的發展方向至關重要,不論我們最終是否親自廣泛部署它。”
OpenAI還寫道,希望其軟件的試用能“激發增強社會韌性的需求”,以應對更先進的AI技術帶來的挑戰。例如,該公司呼籲銀行逐步停止將語音身份驗證作為訪問銀行賬戶和敏感信息的安全措施。它還尋求開展公眾教育,幫助大傢解欺騙性的AI內容,並開發更多技術來檢測音頻內容是否由AI生成。