美國當地時間4月9日,Intel舉辦一場面向客戶和合作夥伴的IntelVision2024產業創新大會,做出多項重磅宣佈,包括全新的Gaudi3AI加速器,包括全新的至強6品牌,以及涵蓋全新開放、可擴展系統,下一代產品和一系列戰略合作的全棧解決方案。
數據顯示,預計到2030年,全球半導體市場規模將達1萬億美元,AI是主要推動力,不過在2023年,隻有10%的企業能夠成功將其AIGC項目產品化。
Intel的最新解決方案,有望幫助企業應對推廣AI項目時所面臨的挑戰,加速實現AIGC落地商用。

Intel現有的Gaudi 2誕生於2022年5月,並於2023年7月正式引入中國,擁有極高的深度學習性能、效率,以及極高的性價比。
它采用臺積電7nm工藝制造,集成24個可編程的Tenor張量核心(TPC)、48MB SRAM緩存、21個10萬兆內部互連以太網接口(ROCEv2 RDMA)、96GB HBM2E高帶寬內存(總帶寬2.4TB/s)、多媒體引擎等,支持PCIe 4.0 x16,最高功耗800W,可滿足大規模語言模型、生成式AI模型的強算力需求。

新一代的Gaudi 3面向AI訓練和推理,升級為臺積電5nm工藝,帶來2倍的FP8 AI算力、4倍的BF16 AI算力、2倍的網絡帶寬、1.5倍的內存帶寬。
對比NVIDIA H100,它在流行LLM上的推理性能領先50%、訓練時間快40%。
Gaudi 3預計可大幅縮短70億和130億參數Llama2模型、1750億參數GPT-3模型的訓練時間。
在Llama 70億/700億參數、Falcon 1800億參數大型語言模型上,Gaudi 3的推理吞吐量和能效也都非常出色。

Gaudi 3提供多種靈活的形態,包括OAM兼容夾層卡、通用基板、PCIe擴展卡,滿足不同應用需求。
Gaudi 3提供開放的、基於社區的軟件,以及行業標準以太網網絡,可以靈活地從單個節點擴展到擁有數千個節點的集群、超級集群和超大集群,支持大規模的推理、微調和訓練。
Gaudi 3 AI加速器具備高性能、經濟實用、節能、可快速部署等優點,能夠充分滿足復雜性、成本效益、碎片化、數據可靠性、合規性等AI應用需求。
Gaudi 3將於2024年第二季度面向OEM廠商出貨,包括戴爾、慧與、聯想、超威等。
目前,Intel Gaudi加速器的行業客戶及合作夥伴有NAVER、博世(Bosch)、IBM、Ola/Krutrim、NielsenIQ、Seekr、IFF、CtrlS Group、Bharti Airtel、Landing AI、Roboflow、Infosys,等等。
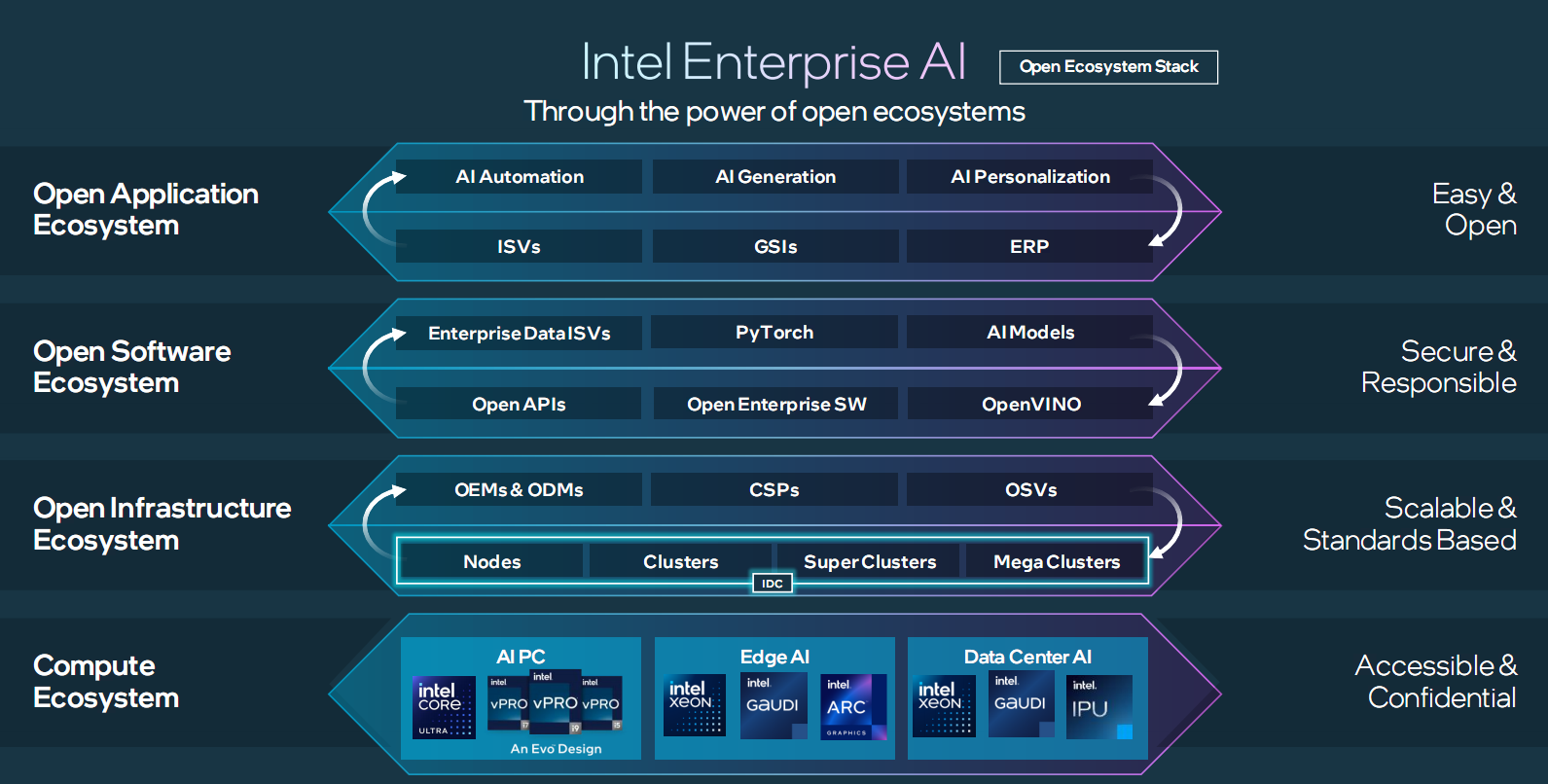
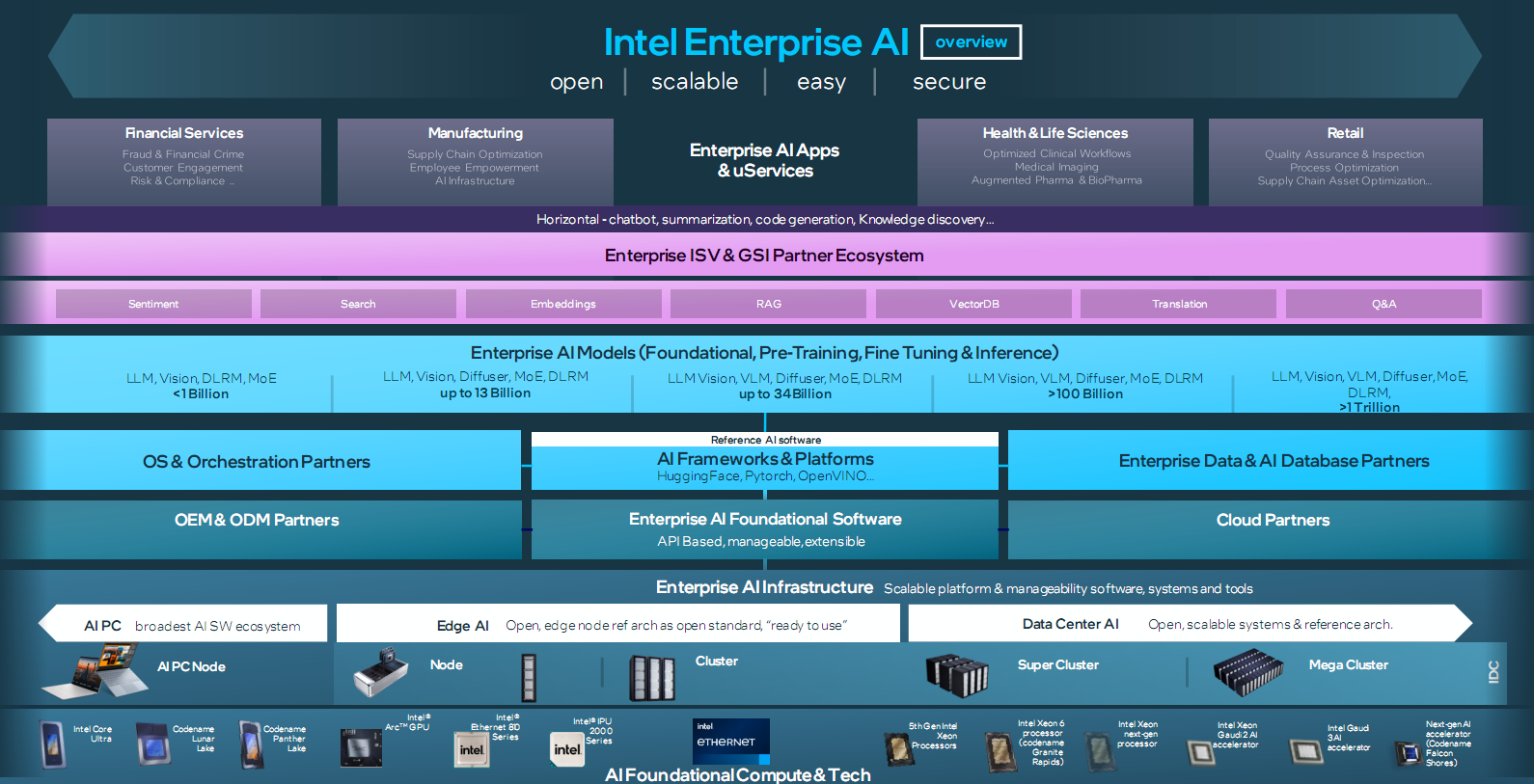
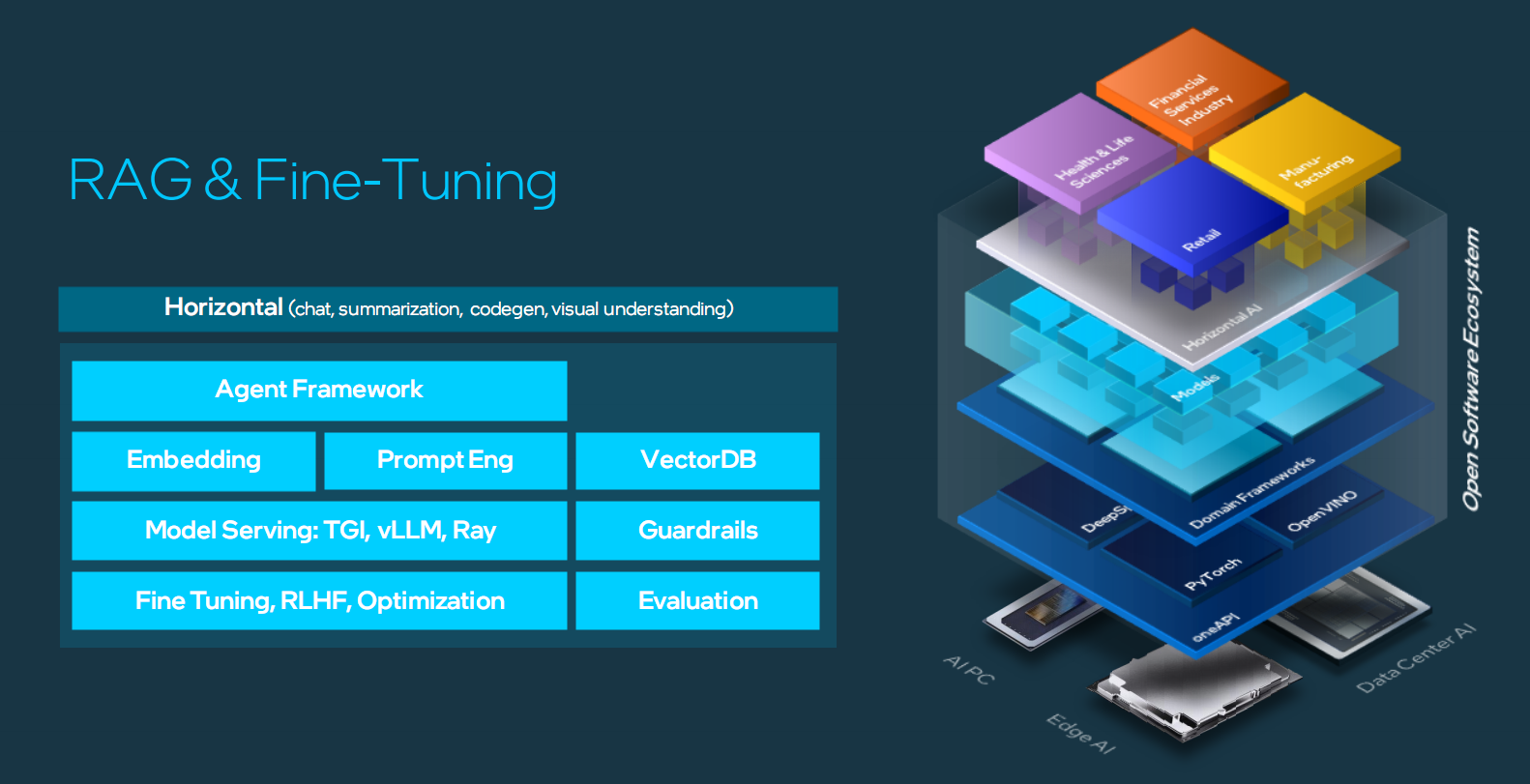
此外,Intel還宣佈聯合Anyscale、DataStax、Domino、Hugging Face、KX Systems、MariaDB、MinIO、Qdrant、RedHat、Redis、SAP、SAS、VMware、Yellowbrick、Zilliz等夥伴,共同創建一個開放平臺,助力企業推動AI創新。
該計劃旨在開發開放的、多供應商的AIGC系統,通過RAG(檢索增強生成)技術,提供一流的部署便利性、性能和價值。
初始階段,Intel將利用至強處理器、Gaudi加速器,推出AIGC流水線的參考實現,發佈技術概念框架,並繼續加強Intel Tiber開發者雲平臺基礎設施的功能。