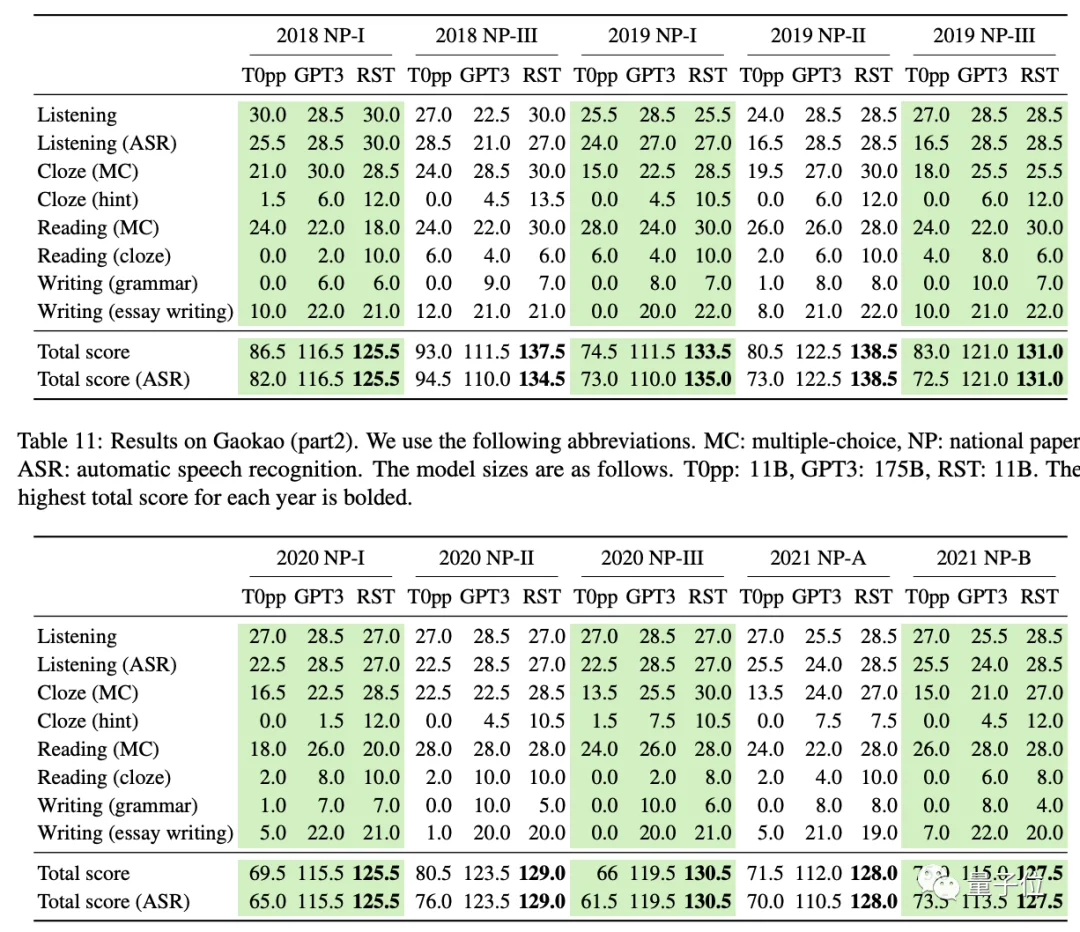
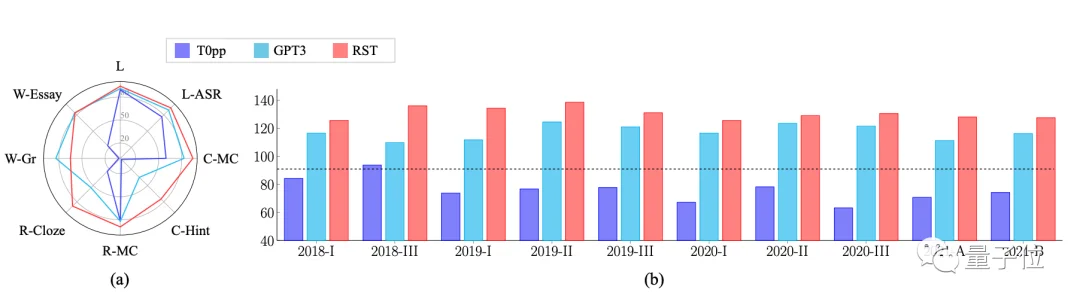
在挑戰寫語文作文後,AI現在又盯上瞭高考英語。結果好傢夥,今年高考英語卷(全國甲卷)一上手,就拿瞭134分。而且不是偶然的超常發揮。在2018-2021年的10套真題測試中,AI的分數都在125分以上,最高紀錄為138.5分,聽力和閱讀理解還拿過滿分。
這就是由CMU學者提出的,高考英語測試AI系統Qin。
它的參數量隻有GPT-3的16分之一,平均成績卻比GPT-3高出15分。
其背後的秘訣名叫重構預訓練 (reStructured Pre-training),是作者提出的一種新學習范式。
具體來看,就是把維基百科、YouTube等平臺的信息重新提取重構,再喂給AI進行訓練,由此讓AI具有更強的泛化能力。
兩位學者用足足100多頁的論文,深入解釋瞭這一新范式。
那麼,這一范式到底講瞭什麼?
我們來深扒一下~
什麼是重構預訓練?
論文題目很簡單,就叫reStructured Pre-training(重構預訓練,RST)。

核心觀點凝練來說就是一句話,要重視數據啊!
作者認為,這個世界上有價值的信息無處不在,而目前的AI系統並沒有充分利用數據中的信息。
比如像維基百科,Github,裡面包含瞭各種可以供模型學習的信號:實體,關系,文本摘要,文本主題等。這些信號之前由於技術瓶頸都沒有被考慮。
所以,作者在本文中提出瞭一種方法,可以用神經網絡統一地存儲和訪問包含各種類型信息的數據。
他們以信號為單位、結構化地表示數據,這很類似於數據科學裡我們常常將數據構造成表或JSON格式,然後通過專門的語言(如SQL)來檢索所需的信息。
具體來看,這裡的信號,其實就是指數據中的有用信息。
比如在“莫紮特生於薩爾茨堡”這句話中,“莫紮特”、“薩爾茨堡”就是信號。
然後,就需要在各種平臺上挖掘數據、提取信號,作者把這個過程比作瞭從礦山裡尋寶。

接下來,利用prompt方法,就能將這些來自不同地方的信號統一成一種形式。
最後,再將這些重組的數據集成並存儲到語言模型中。
這樣一來,該研究就能從10個數據源中,統一26種不同類型的信號,讓模型獲得很強的泛化能力。
結果表明,在多個數據集中,RST-T、RST-A零樣本學習的表現,都優於GPT-3的少樣本學習性能。

而為瞭更進一步測試新方法的表現,作者還想到瞭讓AI做高考題的方法。
他們表示,現在很多工作方法走的都是漢化GPT-3的思路,在評估的應用場景上也是跟隨OpenAI、DeepMind。
比如GLUE測評基準、蛋白質折疊評分等。
基於對當下AI模型發展的觀察,作者認為可以開辟出一條新的賽道試試,所以就想到瞭用高考給AI練練手。
他們找來瞭前後幾年共10套試卷進行標註,請高中老師來進行打分。
像聽力/識圖理解這樣的題目,還找來機器視覺、語音識別領域的學者幫忙。
最終,煉出瞭這套高考英語AI模型,也可以叫她為Qin。
從測試結果可以看到,Qin絕對是學霸級別瞭,10套卷子成績都高於T0pp和GPT-3。
此外,作者還提出瞭高考benchmark。
他們覺得當下很多評價基準的任務都很單一,大多沒有實用價值,和人類情況對比也比較困難。
而高考題目既涵蓋瞭各種各樣的知識點,還直接有人類分數來做比對,可以說是一箭雙雕瞭。
NLP的第五范式?
如果從更深層次來看,作者認為,重構預訓練或許會成為NLP的一種新范式,即把預訓練/微調過程視為數據存儲/訪問過程。
此前,作者將NLP的發展總結成瞭4種范式:
P1. 非神經網絡時代的完全監督學習 (Fully Supervised Learning, Non-Neural Network)
P2. 基於神經網絡的完全監督學習 (Fully Supervised Learning, Neural Network)
P3. 預訓練,精調范式 (Pre-train, Fine-tune)
P4. 預訓練,提示,預測范式(Pre-train, Prompt, Predict)
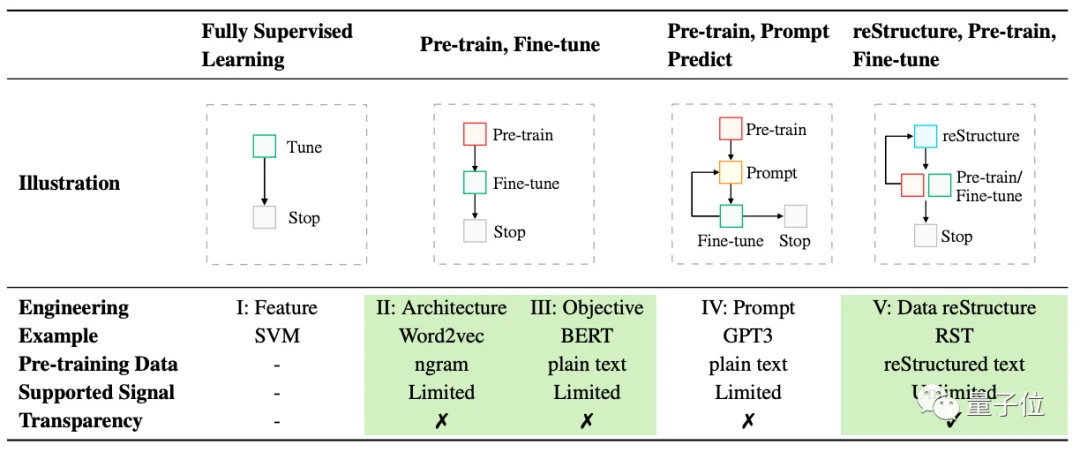
但是基於當下對NLP發展的觀察,他們認為或許之後可以以一種data-centric的方式來看待問題。
也就是,預訓/精調、few-shot/zero-shot等概念的差異化會更加模糊,核心隻關註一個點——
有價值的信息有多少、能利用多少。
此外,他們還提出瞭一個NLP進化假說。
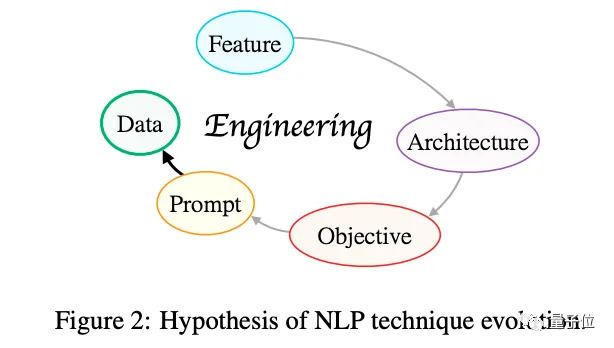
其中的核心思想是,技術發展方向總是順著這樣的——做更少的事實現更好、更通用的系統。
作者認為,NLP經歷瞭特征工程、架構工程、目標工程、提示工程,當下正在朝著數據工程方向發展。
復旦武大校友打造
本篇論文的一作為Weizhe Yuan。
她本科畢業於武漢大學,後赴卡內基梅隆大學讀研,學習數據科學專業。
研究方向集中在NLP任務的文本生成和評估。
去年,她被AAAI 2022、NeurIPS 2021分別接收瞭一篇論文,還獲得瞭ACL 2021 Best Demo Paper Award。

論文的通訊作者為卡內基梅隆大學語言技術研究所(LTI)的博士後研究員劉鵬飛。
他於2019年在復旦大學計算機系獲得博士學位,師從邱錫鵬教授、黃萱菁教授。
研究興趣包括NLP模型可解釋性、遷移學習、任務學習等。
博士期間,他包攬瞭各種計算機領域的獎學金,包括IBM博士獎學金、微軟學者獎學金、騰訊人工智能獎學金、百度獎學金。

One More Thing
值得一提的是,劉鵬飛在和我們介紹這項工作時,直言“最初我們就沒打算拿去投稿”。
這是因為他們不想讓會議論文的格式限制瞭構思論文的想象力。
我們決定把這篇論文當作一個故事來講,並給“讀者”一種看電影的體驗。
這也是為什麼我們在第三頁,設置瞭一個“觀影模式“的全景圖。
就是為瞭帶著大傢去瞭解NLP發展的歷史,以及我們所展望的未來是怎樣的,讓每一個研究者都能有一定的代入感,感受到自己去帶領著預訓練語言模型們(PLMs)通過礦山尋寶走向更好明天的一個過程。

論文結尾,還藏瞭一些驚喜彩蛋。
比如PLMs主題表情包:

還有結尾的插畫:

這麼看,100多頁的論文讀起來也不會累瞭