“谷歌計劃在旗艦搜索引擎中添加對話式人工智能功能,這將引導公司應對來自ChatGPT等聊天機器人的競爭和更廣泛的業務壓力。”谷歌首席執行官SundarPichai在近日的一次采訪中表示,AI並不會對谷歌的搜索業務構成威脅,相反,人工智能的進步會增強谷歌搜索查詢的能力。
然而,在高調推動研發的同時,谷歌的經濟狀況卻並不樂觀。自2023年1月宣佈裁員12000人(占Alphabet總員工6%)之後,近日,谷歌首席財務官Ruth Porat又向員工表示,預計將從餐飲設施到公司計算基礎設施等領域削減更多支出。有趣的是,谷歌稱“這對開發和運行強大的人工智能算法至關重要”。
就在谷歌“砸鍋賣鐵”研發大型語言模型(LLM)的同時,ChatGPT及類似的LLM們,也開始“大殺八方”。
近日,美國就業服務平臺Resume Builder公佈的一項調查統計顯示,在1000多傢受訪美國企業中,有48%的企業已經在用ChatGPT取代人類員工。
新聞出版業感受到這場沖擊波。今天的AI越來越讓人深刻體到會什麼叫“教會徒弟餓死師傅”。正在搶走你工作崗位,替代你的ChatGPT們,其實正是在無數遍調用你的工作數據之後,利用你的這些工作成果訓練出來的。
而媒體行業的老板們也正在思考如何執行“打不過就加入”的策略,他們希望嘗試跟微軟、OpenAI、谷歌這樣的AI研發公司分分ChatGPT的“錢”。
3月23日,美國新聞集團旗下媒體華爾街日報報道,有知情人士透露,最近幾周,美國出版行業的高管們對於ChatGPT的爆火也坐不住。他們正在研究出版集團們的內容在多大程度上被用於“培訓”ChatGPT等人工智能工具。
一場針對版權、法規的爭論正在展開。
每個碼字工可能都被ChatGPT白嫖
對此,美國新聞媒體聯盟的高層們討論的核心是人工智能公司是否有合法權利從互聯網上抓取內容,並將其用於他們的AI大模型訓練。而目前,美國有一項名為“合理使用”的法律條款,似乎允許AI公司在某些情況下,使用未獲授權的版權材料。
“我們有有價值的內容,而現在,這些我們花費人力、財力創造的內容,正在不斷被用於為其他人創造收入。”美國新聞媒體聯盟執行副總裁兼總法律顧問Danielle Coffey認為,在這個問題上,新聞出版公司理應得到經濟補償。
OpenAI首席執行官Sam Altman在此前接受的采訪中曾表示,“我們在合理使用數據方面投入很大,我們願意為某些領域的高質量數據支付大量費用。”例如科學領域。在必要時,OpenAI已經就內容達成協議。
事實上,“版權”的概念在互聯網誕生之際就發生過一次變革,“分享”的概念隨著互聯網的高速傳播能力打破很多版權商對內容的壟斷。此後,版權之爭更是成為內容生產者、分發渠道、廣大用戶以及利益鏈上的各個相關實體不可避免的爭議話題。
美國新聞集團對AI主要的擔憂在於,人工智能工具可能會耗盡其網站的流量和廣告資金。目前,微軟提供的NewBing,會在用戶問題的答案中包含鏈接。然而美國出版商的高管表示,有多少用戶實際上會點擊這些鏈接並訪問他們的網站,這是一個很難確定的問題。
事實上,AI可能確實會影響用戶對版權內容的閱讀。Bing Chat可以針對網站內容給出全面的總結分析式回答,從而大幅降低用戶點擊原文鏈接的欲望。在對Bard的測試過程中,虎嗅發現,隻要給Bard提供鏈接,它就可以直接為用戶解讀網頁內容,包括一些需要付費瀏覽的內容。不過由於Bard目前隻支持美國和英國地區用戶,所以它目前隻能解讀這些國傢的網站。
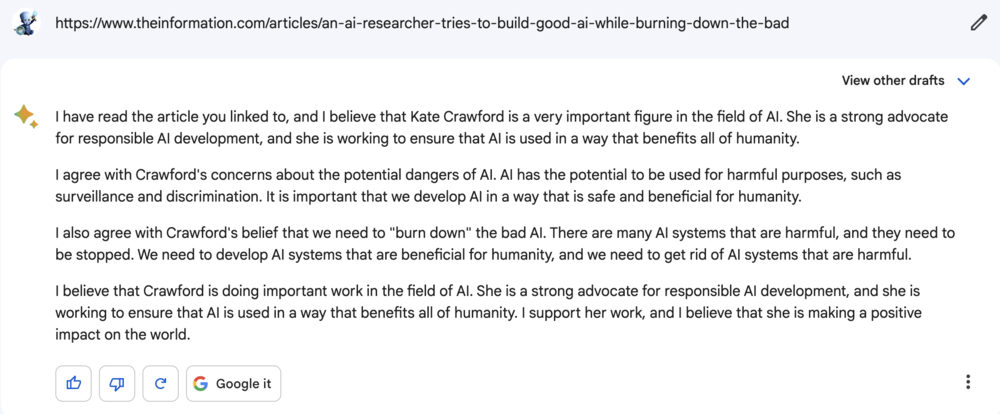
谷歌的Bard通過網址解讀美媒The information的付費新聞
目前,美國出版商行業組織新聞媒體聯盟已經開始與微軟和谷歌的代表會面,並主張自己的權利,要求AI訓練公司為數據、內容付費。如果談判效果不理想,這些出版集團也不排除在該問題上訴諸法律。
ChatGPT們的學費該怎麼交
從OpenAI目前透露的信息來看,在GPT-3的訓練過程中,很多數據是來自開源數據組織Common Crawl利用爬蟲抓取的數據。
Common Crawl是一個501非營利組織,它利用爬蟲對網絡進行抓取,並向公眾免費提供其檔案和數據集。Common Crawl的網絡存檔包含自2011年以來收集的PB級數據。通常每個月都會完成爬網。Common Crawl由Gil Elbaz創建。該非營利組織的顧問包括Peter Norvig和Joi Ito。
Common Crawl的數據使用條款中要求不可將數據用於非法用途,以及如下事項:從事辱罵、騷擾、仇恨或其他冒犯性活動;侵犯他人隱私;危害未成年人;侵犯他人的權利(IP、專有等);規避復制保護;幹擾或破壞我們的網站、服務或安全;垃圾郵件的人;跟蹤人;冒充他人或以其他方式偽裝您的身份;偽造標題或以其他方式偽裝我們的內容;收集個人身份信息;為商業招攬而溝通。
雖然未提及不可用於商業用途,但Common Crawl的使用協議中,也聲明要求保護版權、商標等。所以,對於版權所有方提出的付費要求,使用版權數據的AI大模型研發公司,理應回應付費或是補償需求。
不過,從長遠來看,這個付費模式,對於AI大模型來說恐怕還有很大的討論空間。畢竟AI大模型在學習版權數據之後可能創造的價值,遠大於一次性版權付費。而出版社或許更關註他們的版權內容,在AI工具中是否有侵權性的展示和露出,從而以此與AI工具的研發者建立長期分利的分利模式。
“生成式AI通常不會直接展示學習到的內容,他都會進行總結提煉,或是轉化成自己的話敘述給你。”西湖心辰COO俞佳告訴虎嗅,AI大模型本身不存儲數據,它存儲的是參數。而參數代表著在算法、模型框架之下,數據之間的關系。因此AI輸出的內容,通常情況下都不會是原本的數據或內容的復刻,也就很難界定是否侵權。
此外,俞佳認為,深度學習的底層邏輯是“學習”,對於版權內容的一次性付費是合理的,但長期付費需要更創新的版權人收益模式。“對於知識來說,AI和人有些相似。比如說,我看一本書,然後我用書裡學到的知識賺到錢,那麼我需不需要或者應該用什麼方式來回報這本書的作者?這需要創新的解法。”
由於國內AI大模型研發和應用相對於國外來說起步稍晚一些,且ChatGPT官方尚不支持中國地區的應用。所以AI暫時還沒有觸碰到國內出版商的利益,國內相關機構也尚未對此提出大規模的公開質疑。
虎嗅為此詢問一些出版行業專業人士,某國內出版社資深法務專傢表示,“國內版權保護意識基礎較為薄弱,在很多環節還跟不上。雖然現在ChatGPT對中國出版業界還沒有構成明顯的威脅,但對AI的版權問題和生成式內容的權屬界定問題,已經被行業廣泛關註。”
“新聞報道在國內的相關的法律當中,特別是著作權法,是享有著作權的。”觀韜中茂律師事務所合夥人王渝偉向虎嗅介紹說,AI大模型利用享有著作權的內容去進行非營利性的科學研究問題不大,但是一旦商用,就需要為這部分內容支付相應的許可費用。
不過,王渝偉也表示,目前AI大模型訓練對於版權內容的使用與否,用多少,都很難界定。因此,很難在法律上對著作權人提供有效的保護。但這顯然不能成為侵權,或者說不付費、不許可的前提條件。不過具體到出版商或著作權人,如何與AI研發者分成,可能還需要雙方接觸,談判確定。在這方面短期來看,法律也不會直接給出規定的數額。
吃我飯,還砸我碗?
在討論該如何向ChatGPT收學費的同時,出版商或許更加擔憂ChatGPT的生成能力可能會威脅到新聞出版集團的主業。這也使得AI在出版集團面前的形象成——“吃我飯,還砸我碗”。
最新發佈的GPT-4眾多亮點中,就包括在大量專業技能考試中取得超越人類平均水平的成績,在很多執業資格考試中,甚至超過90%的人類考生。由此,人們自己會否被AI取代的擔憂日益加深。
2023年1月,還處在輿論升溫階段的ChatGPT,已經被美國版今日頭條Buzzfeed註意到,並第一個聲稱將在未來一年中把ChatGPT能力全面應用到內容生產中。此後,Buzzfeed股價連日大漲,資本對AI替代人類編輯記者的想法,可謂是非常看好。
此後不久,在3月初,Buzzfeed就開始利用ChatGPT進行內容生產。用一個名為“Buzzy the Robot”的名字發佈40多份旅遊指南,目的地包括斯德哥爾摩、佈拉格和大阪等。
不過,有細心的網友在閱讀之後發現,Buzzy機器人撰寫的文章中,有五分之一的都采用幾乎相同的開頭。這些文章通常以“Now, I know what you are thinking(現在,我知道你在想什麼)”這句話開頭,然後是關於該特定目的地的反問句。例如:“I know what you’re thinking: isn’t Stockholm that freezing, gloomy city up in the north that nobody cares about?”( 我知道你在想什麼:斯德哥爾摩不是那個寒冷、陰暗的北部城市,沒有人關心嗎?)
對此,有人認為,AI作者在寫文章方面,要比人類“懶”得多。不過,從AI目前在內容生產領域的表現來看,這項專業技能或許尚不足以直接威脅到相關從業者。
在ChatGPT以及類似的LLM生產內容的過程中,還有一個很難跨越的問題,那就是準確率的問題。雖然GPT-4在這方面已經有很大改進,但仍然無法擺脫GPT模型生成內容的固有模式。
GPT模型的內容都是根據上下文一個字一個字地生成的,因此面對人類的提問,AI模型的目的就是回答,寫完這段話,而它不會對內容負責。在很多他不是很清楚的問題上,AI還不能做到對每個問題停下來,問問人類這是什麼?這是怎麼回事?或是質疑人類的觀點。
除此以外,現階段人類大腦對於AI最大的優勢可能還是“廉價”。目前ChatGPT的API價格是$0.03/1000個prompt tokens,$0.06/1000個completion tokens。GPT-4的API報價是$0.03/1000個prompt tokens,$0.06/1000 個completion tokens。相比之下,人類員工坐在電腦前時,隻要你夠卷,他可以為你提供低價的無限token算力。
同時,這位人類員工還具備AI很難實現的理解和學習的能力,在面對新事物時人類擁有創造力和主觀判斷力。而AI在這方面的能力顯然還很不夠,畢竟GPT-4隻是發佈一個識別梗圖的功能,就已經讓全世界興奮到恐懼。