根據維基百科,高速緩存(英語:cache)簡稱緩存,原始意義是指訪問速度比一般隨機存取存儲器(RAM)快的一種RAM,通常它不像系統主存那樣使用DRAM技術,而使用昂貴但較快速的SRAM技術。
當CPU處理數據時,它會先到Cache中去尋找,如果數據因之前的操作已經讀取而被暫存其中,就不需要再從隨機存取存儲器(Main memory)中讀取數據——由於CPU的運行速度一般比主內存的讀取速度快,主存儲器周期(訪問主存儲器所需要的時間)為數個時鐘周期。因此若要訪問主內存的話,就必須等待數個CPU周期從而造成浪費。
早在PC-AT/XT和80286時代,並沒有Cache,CPU和內存都很慢,CPU直接訪問內存。但到80386的芯片組增加對可選的Cache的支持,高級主板帶有64KB,甚至高端的128KB Write-Through Cache。
到80486 CPU裡面,則加入8KB的L1 Unified Cache,當時也叫做內部Cache,不分代碼和數據,都存在一起;芯片組中的Cache,變成L2,也被叫做外部Cache,從128KB到256KB不等;增加Write-back的Cache屬性。Pentium CPU的L1 Cache分為Code和data,各自8KB;L2還被放在主板上。Pentium Pro的L2被放入到CPU的Package上。Pentium 3開始,L2 Cache被放入CPU的Die中。從Intel Core CPU開始,L2 Cache為多核共享。
CPU的緩存曾經是用在超級計算機上的一種高級技術,不過現今電腦上使用的的AMD或Intel微處理器都在芯片內部集成大小不等的數據緩存和指令緩存,通稱為L1緩存(L1 Cache即Level 1 On-die Cache,第一級片上高速緩沖存儲器);而比L1更大容量的L2緩存曾經被放在CPU外部(主板或者CPU接口卡上),但是現在已經成為CPU內部的標準組件;更昂貴的CPU會配備比L2緩存還要大的L3緩存(level 3 On-die Cache第三級高速緩沖存儲器)。
但直到現在,主流芯片還是止步於L3。
緩存的演進
據Quora博主,高級架構師Jerason Banes所說,之所以L4沒被采用,這與CPU架構的發展有著莫大的關系。
他表示,如果我們如果將時鐘回滾到 6502 CPU,您會發現這是一個非常簡單的設計,在實際使用中也很精確,這主要是因為 6502 使用馮·諾依曼架構。這是一個非常簡單的結構,內存、CPU 和 I/O 都根據一個主時鐘以鎖步方式發生。
這意味著如果 CPU 以 1.4MHz 運行,則內存必須以 1.4MHz 運行,但這這很快成為一個問題。
他表示,隨著 CPU 開始加速到 10 MHz,能夠跟上的 RAM 變得非常昂貴。而事實上,從 RAM 到 CPU 的物理距離幾乎不可能跟上 CPU。此外,RAM 容量的增加(兆字節大小)意味著需要使用更復雜的控制電路來尋址內存位置。這意味著當您非順序地讀取內存時,內存會變得具有不可預測的設置時間。
對此,行業提出的解決方案是保留少量 CPU 快速內存,這就是L1 緩存。現在,L1 + CPU 的行為就像舊的 6502 CPU 一樣,但它可以調用 RAM,就像它是一個超高速硬盤驅動器一樣,可以獲取當前不在 L1 中的任何 RAM 塊。就像硬盤驅動器一樣,CPU 隻會等待必要的數據被提取到 L1 緩存中。
這種方法之所以奏效,是因為程序的關鍵部分往往非常小。足夠小到 CPU 在需要返回主內存之前可以花費大量時間運行程序。但美中不足的是——數據與代碼。因為一個程序可能會處理大量數據。這會導致 L1 緩存的使用不佳,並導致緩存中出現大量“misses”。所以 CPU 會有效地減慢主內存的速度,這是可以接受的,除 CPU 比這更慢的事實。
問題是 CPU 正在運行的代碼很容易落入“最近最少使用”的桶中,並被淘汰出 L1 以支持正在處理的數據。一旦 CPU 返回到該代碼塊,它就必須停止並從主內存中重新獲取代碼。這是非常低效的。
為解決這個問題,CPU 轉向哈佛架構. (以早期的Harvard-1 計算機命名.) 在哈佛架構中,代碼與數據保存在不同的內存中。這具有簡化數據路徑的優勢,因為可執行代碼來自一組路徑,而數據來自另一組路徑。更重要的是,通過將 L1 緩存分成兩部分(代碼與數據),數據永遠不會意外驅逐正在運行的代碼。
於是我們將 64KB L1 緩存拆分為 32KB 代碼和 32KB 數據。
緩存的其餘部分用於嘗試處理越來越快的 CPU。CPU 時鐘越快,電能在時鐘周期之間的時間片內傳輸的距離就越短。由於這是一個無法克服的物理問題,CPU 設計人員開始從主內存“暫存”他們需要的數據。L2 的速度通常是 CPU 的一半,但尺寸更大,因此它可以在 CPU 本身繁忙時按順序流式傳輸接下來的幾個塊。當 CPU 請求下一個數據時,它幾乎不需要等待那麼長時間,這就是我們獲得 256KB L2 緩存的方式。
但是L3呢?那個是從哪裡來的?
最後一塊拼圖來自多核處理器。每個內核都想繼續工作,但如果每次需要從主內存中獲取更多數據時它們都必須落後於對方,那麼它們就做不到。因此,L3 緩存在每個內核上的不同 L2 緩存之間充當緩沖區。它將依次嘗試為所有主內存調用提供服務,每次都會多拉一點,以增加在 L2 緩存請求時它已經擁有數據的可能性。這就是為什麼 L3 的數量往往會隨著核心數量的增加而增加。內核越多,它們就越有可能進入主內存的“戰鬥”。
資料顯示,L3 緩存在 Nehalem(第一代酷睿 i7 系列)中成為主流,這是第一個單片四核 CPU 芯片,這意味著所有 4 個內核都在同一塊矽片上。相比之下,它的前身 Core 2 Quad 由同一封裝上的兩個獨立 Core 2 Duo 芯片組成。

為何止步於L4?
在這部分開始之前,我們必須申明,雖然L4目前沒有被主流采用,但IBM早在2000年代就在其自己的某些X86芯片組中添加L4緩存,並在2010年在System z11大型機的NUMA互連芯片組中添加L4緩存。
據解,IBM的z11處理器具有四個內核,每個內核具有64 KB的L1指令和128 KB的L1數據高速緩存,以及每個內核1.5 MB的L2高速緩存和在這四個內核之間的24 MB共享L3高速緩存。z10的NUMA芯片組具有兩排96 MB的L4緩存,總計192 MB。
在談到為什麼沒有用到L4緩存的時候,知乎用戶tjunangang在一個問答下面回應直言——緩存太占地方,而且投入和回報不成正比,不劃算。他表示,如下圖所示,三級緩存差不多占據兩個核心的面積,如果加上四級呢?五級呢?要知道緩存容量都是急速遞增的,如果有四級緩存,單獨的緩存面積就比整個現有的CPU大。
在tjunangang看來,如果繼續引入L4緩存,可能引致下述問題:
1.同樣的晶圓,原本能生產32塊CPU,加上四級緩存可能10塊都生產不,價格暴漲沒人買賬。
2.核心面積大,功耗大,發熱量大,對散熱設備要求高,與未來發展趨勢對著幹..而且核心面積大,良品率低,比較悲劇的是容易碎(我按碎過好多塊)
3.堆緩存這種方式,明顯是土豪作風,要知道intel早期處理器連L3 Cache都沒有。而且關鍵的問題是,你單純的堆緩存,早晚有一天會混不下去,和之前攀主頻的競賽類似,還不如想辦法去提升架構。
4.對於整體性能的作用,L1 cache最大,L2次之, L3甚至不到L1 cache的十分之一。若是不計成本的話,加到L4還有情可原,加到L5其實已經和系統內存差不多。
知名博主“老狼”則表示,目前已經有L4,它有兩種形式,分別是eDRAM和Optane DIMM。例如在英特爾的Iris系列中,就有一塊高速DRAM被放入Package中(eDRAM),它平時可以充當顯存,也可以被設定為L4緩存。
曾經任職於Cray Research,Sun Microsystems,Oracle,Broadcom,Cavium和Marvell的芯片架構師Rabin Sugumar在接受nextplatform采訪的時候表示,並沒有人規定L4緩存必須由嵌入式DRAM(就像IBM對其芯片所做的那樣)或更昂貴的SRAM構成。
根據他的觀點,就目前而言,我們的L3已經很大。因此關於L4緩存,Rabin Sugumar也認為也許是eDRAM,甚至是HBM或DRAM。在這種情況下,一個看起來很有趣的是——L4高速緩存實現是將HBM用作高速緩存,而不是延遲高速緩存,而不是帶寬高速緩存。
“這樣做的想法是,由於HBM容量有限且帶寬較高,因此我們可以獲得一些性能提升,並且在帶寬受限的使用案例中我們確實看到顯著的收益。緩存未命中數。但是,就性能和成本而言,需要做的數學就是添加另一個緩存層是否值得。”Rabin Sugumar說。
有那麼多人發佈如此多觀點,在筆者看來,Intel才是其中的關鍵因素。在日前,他們帶來一個新的分享?
即將走向主流?
據外媒tomshardware報道,英特爾即將推出代號為 Meteor Lake 的處理器,將配備 L4 緩存的非官方信息已經流傳一段時間。而現在, VideoCardz 發現的一項新英特爾專利表明,英特爾已經準備好代號為 Adamantine L4 的高速緩存塊,這將可用於某些 CPU。
“該 IC 可以在某些應用中與 AMD 的 3D V-Cache 競爭,但該小芯片不會僅用作性能助推器。”VideoCardz表示。

該專利表明,英特爾的 Adamantine(或 ADM)緩存不僅可以改善 CPU 和內存之間的通信,還可以改善 CPU 和安全控制器之間的通信。例如,L4 可用於改進引導優化,甚至在重置時保留緩存中的數據以縮短加載時間。
報道表示,雖然專利本身沒有提到 Meteor Lake,但隨附的圖像清楚地展示一個處理器,該處理器具有利用Intel 4工藝生產的兩個高性能的 Redwood Cove 和八個節能的 Crestmont,此外還包括一個基於英特爾 Gen 12.7 的圖形小芯片,還有一個包含兩個以上 Crestmont 內核的 SoC 塊,以及一個使用英特爾 Foveros 3D 技術互連的 I/O 小芯片。該描述對應於英特爾的 Meteor Lake 處理器。
同時,Adamantine L4 緩存可用於 Meteor Lake 以外的廣泛應用。
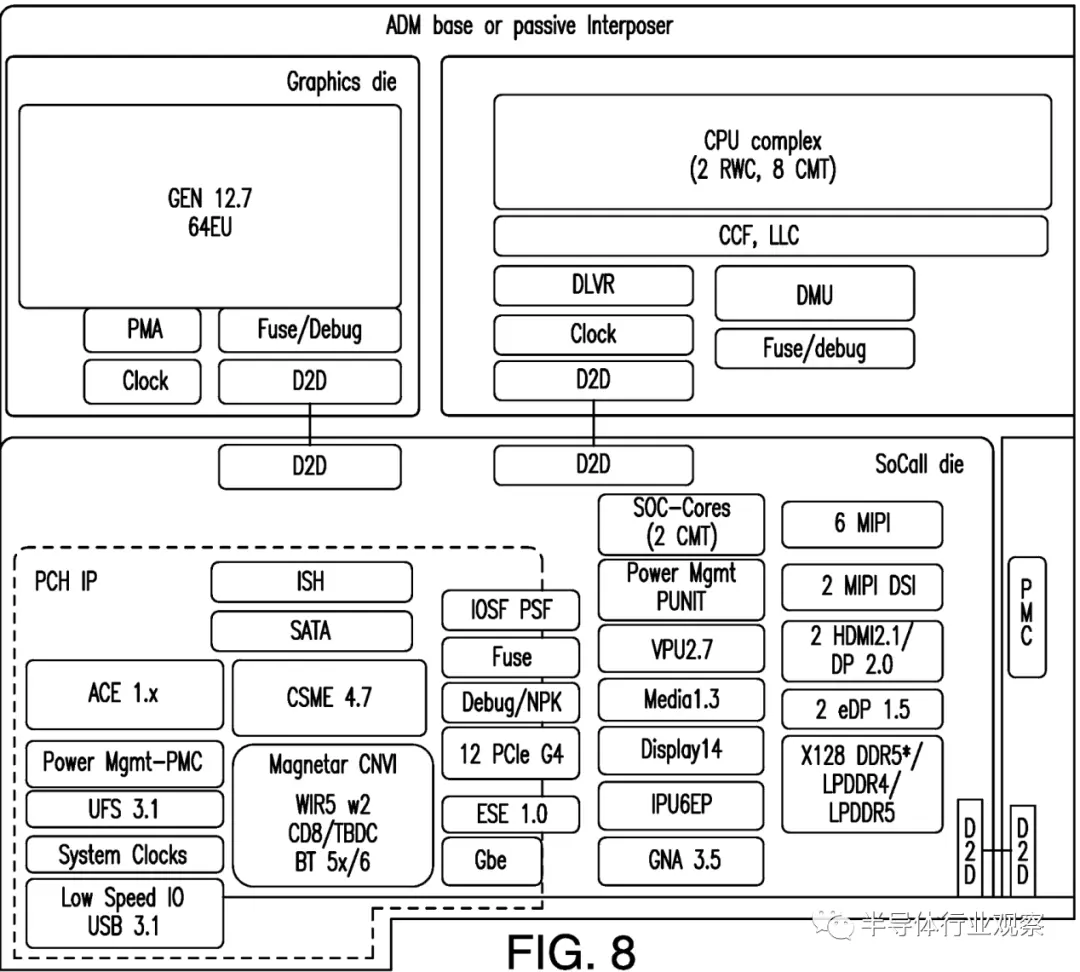
英特爾在介紹該專利的時候表示,下一代客戶端 SoC 架構可能會引入大型封裝緩存,這將允許新的用途。
他們認為,L4(例如,“Adamantine”或“ADM”)高速緩存的訪問時間可能比 DRAM 訪問時間短得多,後者用於改進主機 CPU 和安全控制器通信。實施例有助於保護啟動優化方面的創新。重置時具有更高預初始化內存的高端芯片增加價值,可能會增加收入。在重置時讓內存可用還有助於消除傳統 BIOS 假設,並為現代設備用例(如汽車 IVI、傢用和工業機器人等)提供支持,這就推動產品走向新的細分市場。
也就就說,L4緩存要來?