北大團隊發起一項Sora復現計劃——OpenSora。框架、實現細節已出:初始團隊一共13人:帶隊的是北大信息工程學院助理教授、博導袁粒和北大計算機學院教授、博導田永鴻等人。

為什麼發起這項計劃?
因為資源有限,團隊希望集結開源社區的力量,盡可能完成復現。

消息一出,就有人北大校友兼AnimateDiff貢獻者等人即刻響應:
還有人表示可以提供高質量數據集:
所以,“國產版Sora”的新挑戰者,就這麼來?
計劃細節,已完成3個初步功能
首先,來看目前公佈的技術細節——即團隊打算如何復現Sora。
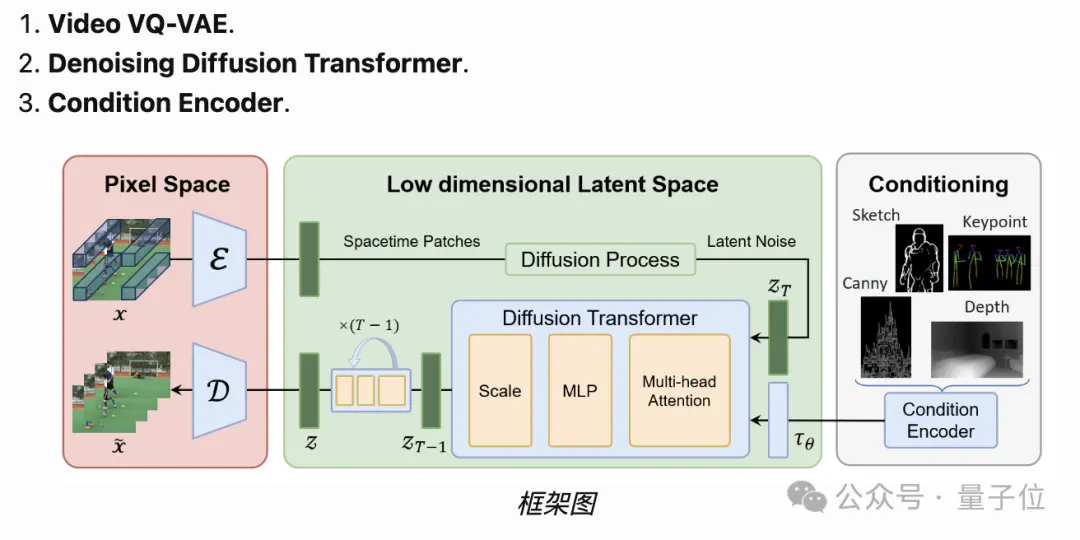
整體框架上,它將由三部分組成:
Video VQ-VAE
Denoising Diffusion Transformer(去噪擴散型Transformer)
Condition Encoder(條件編碼器)
這和Sora技術報告的內容基本差不多。
對於Sora視頻的可變長寬比,團隊通過參考上海AI Lab剛剛提出的FiT(Flexible Vision Transformer for Diffusion Model,即“升級版DiT”)實施一種動態掩碼策略,從而在並行批量訓練的同時保持靈活的長寬比。

具體來說, 我們將高分辨率視頻在保持長寬比的同時下采樣至最長邊為256像素, 然後在右側和底部用零填充至一致的256x256分辨率。這樣便於videovae以批量編碼視頻, 以及便於擴散模型使用註意力掩碼對批量潛變量進行去噪。
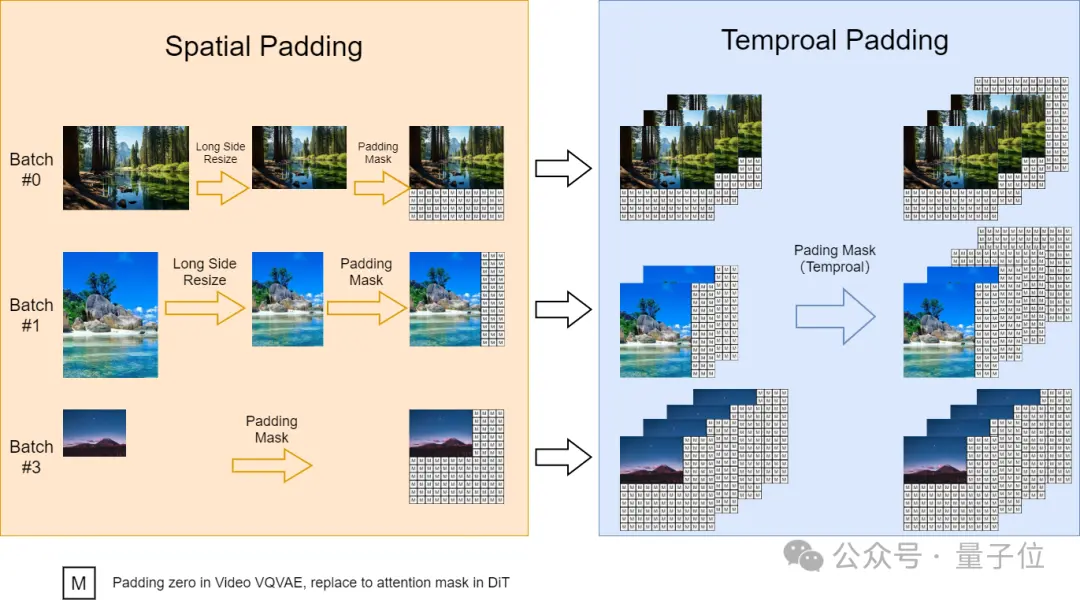
對於可變分辨率,團隊則表示在推理過程中,盡管在固定的256x256分辨率上進行訓練,,但使用位置插值來實現可變分辨率采樣。
具體而言:
我們將可變分辨率噪聲潛變量的位置索引從[0, seq_length-1]下調到[0, 255],以使其與預訓練范圍對齊。這種調整使得基於註意力的擴散模型能夠處理更高分辨率的序列。對於可變時長,則使用VideoGPT中的Video VQ-VAE,,將視頻壓縮至潛在空間,支持這一功能。
同時,還要在擴展空間位置插值至時空維度,實現對可變時長視頻的處理。
在此,主頁也先給兩個demo,分別是10s視頻重建和18s重建,分辨率分別為256x256和196x196:

這三個功能都已經初步實現。
相關的訓練代碼也已經在對應的倉庫上上線:
成員介紹,目前的訓練是在8個A100-80G上進行的(明顯還遠遠不夠),輸入大小為8幀 128 128,大概需要1周時間才能生成類似ucf(一個視頻數據集)的效果。
而從目前已經列出的9項to do事項來看,除可變長寬比、可變分辨率和可變時長,動態掩碼輸入、在embeddings上添加類條件這兩個任務也已完成。
未來要做的包括:
采樣腳本
添加位置插值
在更高分辨率上微調Video-VQVAE
合並SiT
納入更多條件
以及最重要的:使用更多數據和更多GPU進行訓練

袁粒、田永鴻領銜
嚴格來說,Open Sora計劃是北大-兔展AIGC聯合實驗室聯合發起的。
領銜者之一袁粒,為北大信息工程學院助理教授、博導,去年獲得福佈斯30歲以下亞洲傑出人物榜單。

他分別在中國科學技術大學和新加坡國立大學獲得本科和博士學位。
研究方向為深度視覺神經網絡設計和多模態機器學習,代表性一作論文之一T2T-ViT被引次數1000+。
領銜者之二田永鴻,北京大學博雅特聘教授,博士生導師,IEEE、ACM等fellow,兼任鵬城實驗室(深圳)人工智能研究中心副主任,曾任中科院計算所助理研究員、美國明尼蘇達大學訪問教授。

從目前公佈的團隊名單來看,其餘成員大部分為碩士生。
包括袁粒課題組的林彬,他曾多次以一作或共同一作身份參與“北大版多模態MoE模型”MoE-LLaVA、Video-LLaVA和多模態對齊框架LanguageBind(入選ICLR 2024)等工作。
兔展這邊,參與者包括兔展智能創始人、董事長兼CEO董少靈(他也是北大校友)。
完整名單:

誰能率先發佈中文版Sora?
相比ChatGPT,引爆文生視頻賽道的Sora研發難度顯然更大。
誰能奪得Sora中文版的首發權,目前留給公眾的是一個大大的問號。
在這之中,傳聞最大的是字節。
今年2月初,張楠辭去抖音集團CEO一職,轉而負責剪映,就引發外界猜測。
很快,一款叫做“Boximator”的視頻生成模型浮出水面。
它基於PixelDance和ModelScope兩個之前的成果上完成訓練。
不過,很快字節就辟謠這不是“字節版sora”:
它的效果離Sora還有很大差距,暫時不具備落地條件,並且至少還需2-3個月才能上線demo給大傢測試。
但,風聲並未就此平息。
去年11月,字節剪映悄悄上線一個AI繪畫工具“Dreamina”,大傢的評價還不錯。
現在,又有消息稱:
Dreamina即將上線類似sora的視頻生成功能(目前在內測)。

不知道,這一次是不是字節亮出的大招呢?
Open Sora項目主頁:
https://pku-yuangroup.github.io/Open-Sora-Plan/blog_cn.html
https://github.com/PKU-YuanGroup/Open-Sora-Plan